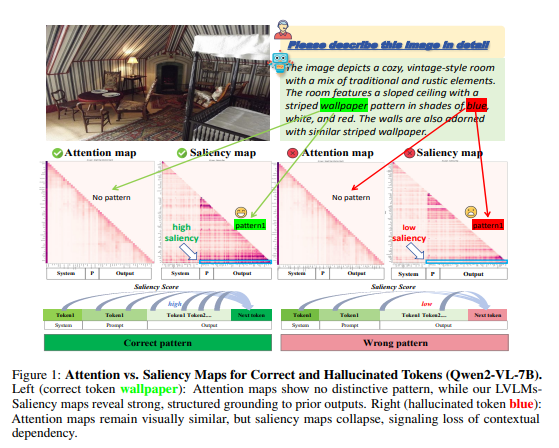
Hallucination Begins Where Saliency Drops
Review
| 닉네임 | 한줄평 | 별점 (0/5) |
|---|---|---|
| thumps-up | • 장: 재학습 없이 hallucination을 완화하는 방법론 제안. VLM의 환각에 대한 명확하고 직관적인 interpretability 제공 !!!! • 단: openreview forum에 있는 통계,분석 내용들이 본문에도 있었으면 좋았을텐데! • 보완: single-modal (LLM)과의 경향 비교 추가하기 | 4.5 |
| 눈물 | • 강점 : hallucination의 원인을 attention + attention gradient(saliency)로 표현해 분석하고, saliency와 LOCORE를 통해 context drift를 방지하는 아이디어를 제시함. 방지하는 수식도 논리적인듯. 사실 attention 매커니즘이 강력하다보니, hallucination도 단순히 attention 자체의 영향력과 직결될 줄 알았지만, 아니었음. • 약점 : 아이디어 제시는 좋지만, 추가 연산(gradient)이 생기는 것도 고려해야 함. • 보완점 : 다른 논문들에서 추정치를 구하던데, gradient도 추정해서 할 수 있을까? 된다면 매우 획기적일듯? | 4.3 |
| 웃으면서 보자 | 장점: 모달리티에 따라 발생하는 문제를 잘 정의함. 문제 정의와 아이디어, 해결 방법이 직관적이고 깔끔함. 단순하게 하나의 모델이 처리하면 모달리티 환각이 줄어들 수 있다고 생각할 수 있지만, 그에 대한 좋은 참고 및 생각 자료가 될듯. 단점: 사실 크로스 모달에서 가장 중요한건 각 정보를 잘 융합하고 처리하는 것이라고 생각함. 환각은 그걸 못해서 발생하는 것이라고 생각함. 그냥 사후 검증해도 충분하지 않나? 굳이 이렇게까지? 보완점: 해석은 가능하미, 단순화하는 방법이 없을까? | 4.0 |
| 독수리오형제 | • 강점: 기존 hallucination 분석이 주로 attention pattern에 의존했다면, 이 논문은 attention과 gradient를 결합한 saliency로 attention을 더 다방면으로 활용하고자 함 • 약점: 왜 이런 현상이 생기는지에 대한 근본원인 분석이 있으면 좋겠음 • 보완점: 꽤나 많은 곳에 사용할 수 있을것 같다. LLM측면에서는 saliency가 떨어진 구간만 추가적으로 검증하거나, retrieval를 호출하는 방식 등? | 4.2 |
| 팝콘 | • 장점: saliency와 LVLM hallucination의 연관을 새롭게 밝힘. 기존과 다르게 입력 프롬프트가 아닌 생성물과의 관계가 hallucination과 관련됨을 보임 • 단점: SGRS가 복잡도에 비해 성능 향상 정도가 적은 경우가 있음 • 보완점: 과거 output 토큰을 잊는 것과 hallucination이 무슨 관련인지 분석결과나 설명 | 4.0 |
| 삐질 | • 장점: 어텐션은 단순한 가중치 분포로 실제 영향력을 알기 어려웠는데, gradient를 고려함으로써 어떤 토큰이 다음 예측에 실제로 영향을 미치는지를 파악 가능함 • 단점: VLM에서 hallucination의 핵심은 이미지와 텍스트 간 misalignment인데, 방법 자체는 텍스트 대상인듯? VLM에 focus를 덜 둔 느낌 • 보완점: 이미지 grounding을 추가해서 이미지 토큰 -> 텍스트 토큰 saliency도 고려 | 4.0 |
| 초콜릿 | • 장점: Attention만으로는 실제 영향력을 파악하기 어려운 한계를 gradient와 결합해서 보완함. inference 단계에서 바로 적용 가능함 • 약점: Saliency 계산을 위해 매 토큰마다 gradient를 구해야 하는데, 이 추가 연산 비용이 실제 환경에서 부담이 되지 않을까 • 보완점: 텍스트만 다루는 일반 LLM에서도 같은 saliency 하락이 나타나는지 볼수 있으면 좋을것 같다 | 4.0 |
| 피땀 | • 장점: motivation 에서 시작해서 실제로 문제점을 보이는데에 그치지않고 해결방법(SGRS, LocoRE)를 제시하는 점에서 기승전결이 휼륭함 • 약점 & 보완점: grounding strength를 측정할 수 없는 LLM에서도 일반화 가능할까? 이에 대한 추가 실험이 있었으면 좋았을 듯 | 4.0 |
| 덩쿠림보 | Saliency map을 보는건 LLM스러운 접근은 아니어서 꽤 새로움! 과연 NLP에서도 먹힐까 하는 생각은 듦. 물론 구문 분석 등 saliency map을 연상시키는 방법론들이 이미 NLP에서도 적용되기는 한데, 흠.. 이런 느낌. 전체적인 접근은 novel한 것 같음! | 3.6 |
| 파이어 | • 장점: Saliency를 계산하여 정확성을 검증하였다는 아이디어가 신선함. • 단점: Text-only LLM에서도 같은 현상이 발생하는지 의문 • 보완점: 이미지 Grounding 및 텍스트 only LLM에 대해서도 실험 및 증명이 필요. | 3.8 |
TL; DR
💡
Hallucination을 줄이기 위해 Attention map말고도 Saliency map에서 gradient가 줄어드는 부분을 확인해야 한다!

Summary
Background & Motivation
- Large Vision Language Model (LVLM) 모델은 Cross-modal task에서 많은 효과를 보여 왔음
- Visual Question Answering (VQA)나 Image Caption에서 특히 활용도가 높음
- 외부 지식을 활용하는 많은 방법들이 제안되어 왔는데, Interpretability (해석가능성)이 부족한 한계점
- 현재까지 Large Vision Language Model들에 대하여 Hallucination을 Correct Output과 구분할 수 있는 방법론이 많이 개발되고 있으나, 한계가 있음
- Forward-pass Attention에 의존하고, Gradient에 기반한 신호는 기존 방법들에서 무시되어 왔음
- Forward-pass Attention mask에서 sink되는 부분이 있으면 Hallucination이라고 판정해 왔지만 이게 적용되지 않는 예시가 너무 많음
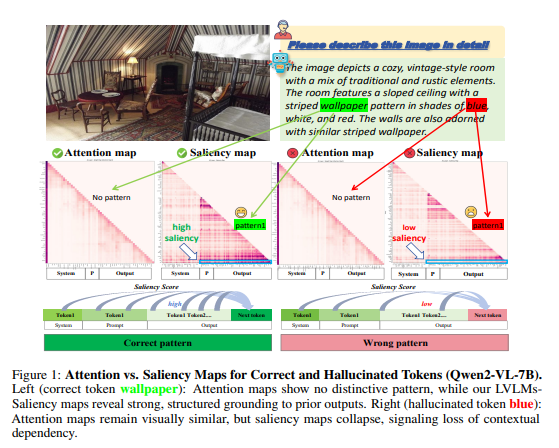
- Hallucinated Token을 구분할 때, 기존의 Forward-pass Attention map으로는 구분할 수 없고, Saliency Map에서 low Saliency를 가지는 부분이 Hallucination이 발생하는 부분임을 보임
- “Label Words” (2023)의 information flow 개념에서 착안하여 특정 token에서 information highlight가 집중됨을 이용
- LVLM-Saliency를 제안(Element-wise product of attention.weights and gradients)
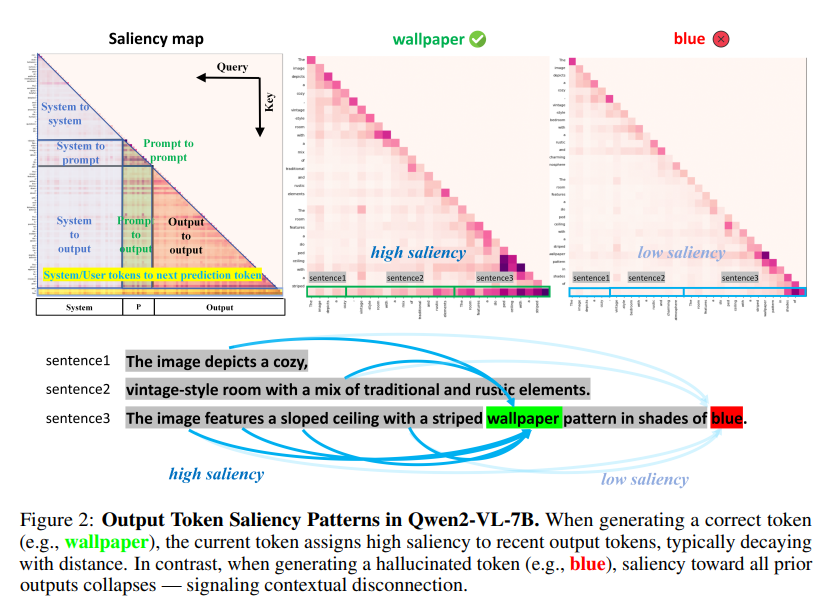
- 다음 토큰에 대해 선행 output token들이 Saliency가 낮을 경우 Hallucination이 발생함!
- 모델이 이전의 Context를 잊어버린 경우 Hallucination이 발생함
- 이전의 output context만 영향을 미치고, Prompt Saliency는 이 문제에서 거의 영향이 없음
Method
- Saliency-guided Rejection Sampling (SGRS)
- Normalized Saliency
- Attention Weight A와 logit s가 있을 때, 실제 후보의 정답 확률 분포 y와 모델의 출력 바로 이전인 logit s간의 Cross-Entropy loss를 계산
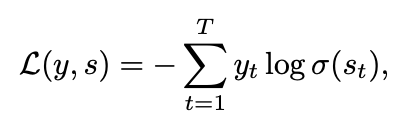
- 이후 Attention Matrix A(layer l와 head h별 Matrix)와 Loss의 Gradient를 구해 Attention이 얼마나 Loss에 영향을 미치는지 구함
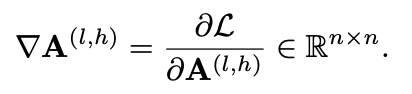
- layer와 head별 Saliency Matrix S를 Hadamard Product를 통해 구함
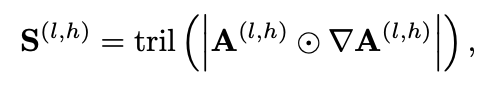
- Layerwise Attention은 Attention Head마다의 Saliency를 평균을 내어 계산하며 L2 정규화를 적용함
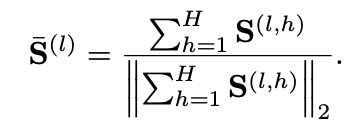
- SGRS는 Token을 실제로 출력하기 전에 후보 토큰의 Grounding 품질을 평가함
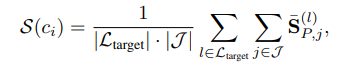
- c_i는 후보 토큰 (Candidate) 중 하나
- Layer-wise Normalized Saliency Matrix를 활용하여 Saliency를 계산
- Target layer와 Generated output token별로 Saliency를 구하여 평균을 냄
- Candidate의 Saliency가 일정한 Threshold 이상이 되었을 때만 출력을 허용하는 방법을 사용하여 Hallucination을 방지
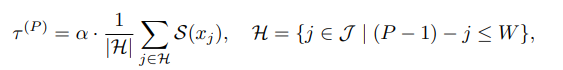
- Adaptive Threshold: S(xj)는 xj(현재) Token까지의 Saliency를 의미함
- Window size W를 지정하여 특정 범위까지의 Saliency를 계산한 평균보다 크면 품질이 만족했다고 평가하는 원리
- Alpha 값은 Threshold의 민감도를 조정하기 위함
- Normalized Saliency
- Local Coherence Reinforcement (LOCORE)
- LocoRe는 sequence-level context drift를 바로잡는 역할을 함
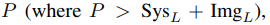
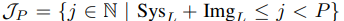
- Absolute position P: 현재 위치
- Jp: 현재 위치 이전에 생성된 토큰들을 의미
- P+1(현재보다 바로 뒤 위치)의 토큰을 예측하기 위해서 P+1을 Query로 Jp를 key로 사용하여 Attention을 봄(단, window size를 조절하여 최근 s개 이내의 토큰을 집중적으로 봄)
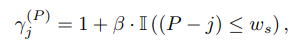
- Gain 및 Attention Matrix Update
- 최근 토큰일 수록 Attention을 증폭하는 방식
- 현재 위치 P에서 과거 토큰 위치 j의 차가 windows size이하일 때만 Gain을 1+(Beta)로 적용
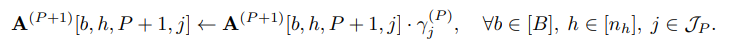
- b: batch, h: head, P+1: 생성하려는 next token, j: 과거의 토큰
- Next Token을 생성할 때 과거의 토큰을 얼마나 참조하는지를 나타내며, Windows Size이내의 최근 과거 토큰에 대해서만 Gain을 부여함.
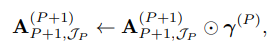
- Gain Vector로 factorization하여 Attention Weight를 Update하는 형태
- LocoRe는 sequence-level context drift를 바로잡는 역할을 함
Experiments
- Experimental Setups
- Baselines
- 최신 모델들로 실험
- LLaVA-v1.5-7/13B 모델, Qwen2-VL-7B, Intern-VL-7/13B 모델로 실험
- Evaluation Benchmarks
- 이미지 벤치마크
- Comprehensive Benchmarks
- LLaVa, MM-Vet, MME
- General VQA benchmarks
- VizWiz
- Hallucination benchmarks
- POPE
- CHAIR
- Comprehensive Benchmarks
- 이미지 벤치마크
- Baselines
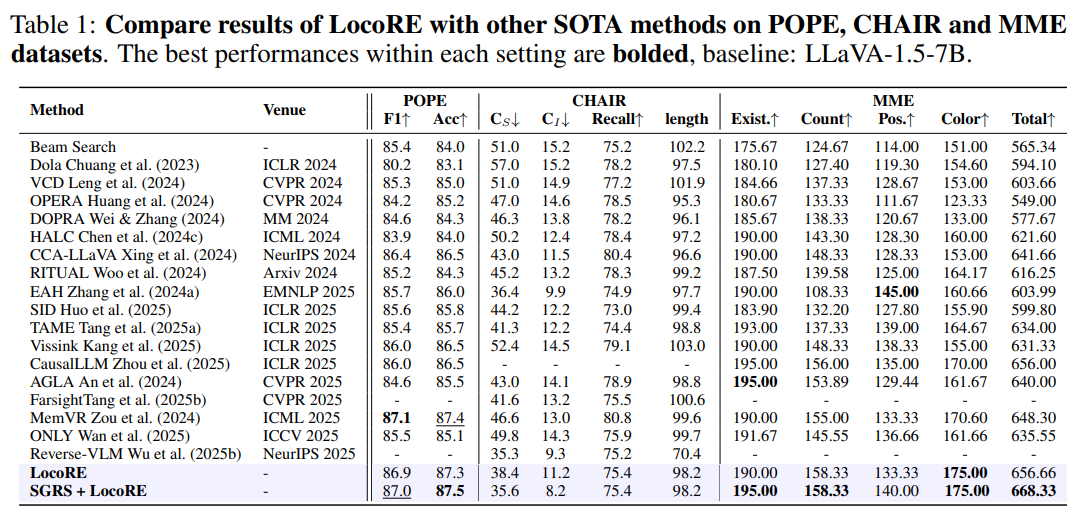
- Evaluation Results on Hallucination Benchmarks
- CHAIR and POPE Evaluations
- OPERA, DOLA, VCD, HALC, ICD , RITUAL, AGLA, SID, Only
- SFT methods
- LESS is more, CCA-LLaVa, Reverse-VLM
- End-of-Sequence (EOS) Symbol을 조절하여 logit을 조절함
- 모델 출력의 truthfulness을 Attention Head의 조절로 개선하는 것을 목표
- Vissink, EAH, TAME, MemVR, Farsight
- CHAIR and POPE Evaluations
- Evaluation Results on Generation Benchmark
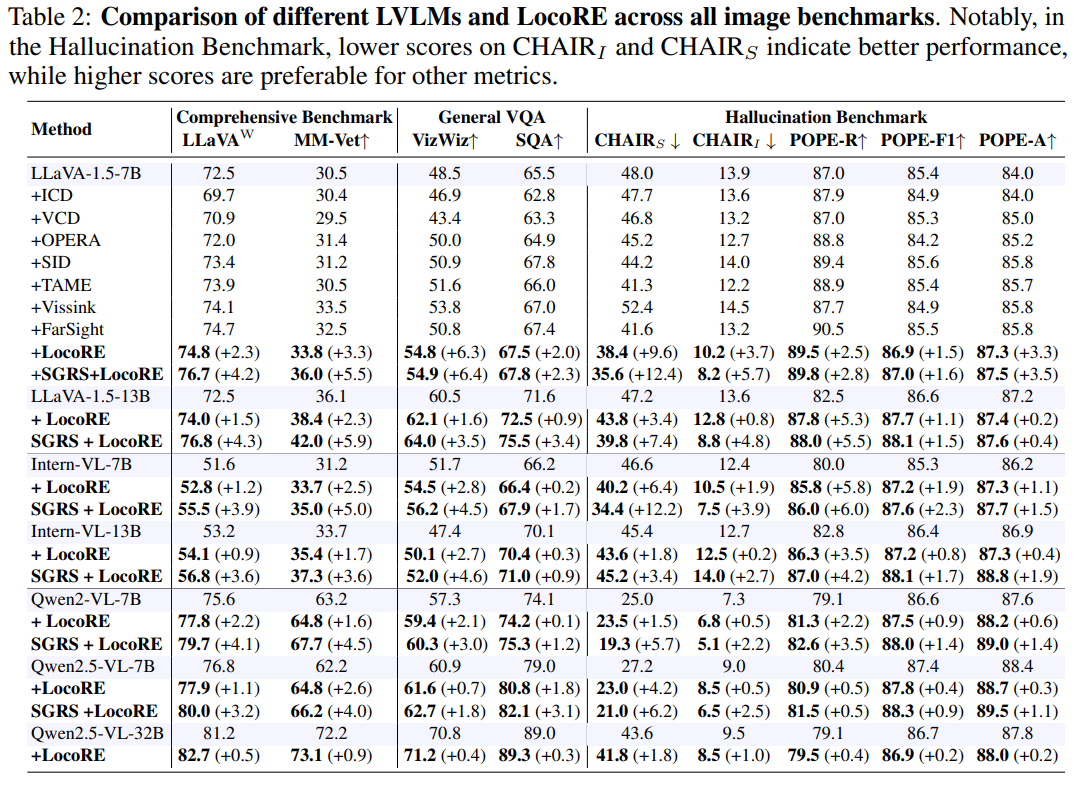
- MME 벤치마크
- 모델의 Perceptual 능력을 평가하기 위한 10개의 Task로 구성되며, Recognitive 능력을 평가하기 위한 4개의 task로 구성됨
- 모든 카테고리에서 가장 높은 성능을 보임
- SGRS와 LocoRE를 결합하는 것이 Reasoning-intensive tasks를 향상하게 됨
- MME 벤치마크
Ablation Study
- Effect of LocoRE
- LocoRE를 LLaVA-1.5, Qwen2에 합치는 것이 성능 결과를 향상시키는 것에 기여함
- LocoRE가 Hallucination을 구조적인 환경, 비구조적인 환경 모두에서 개선함을 확인함
- Saliency map visualization with LocoRE
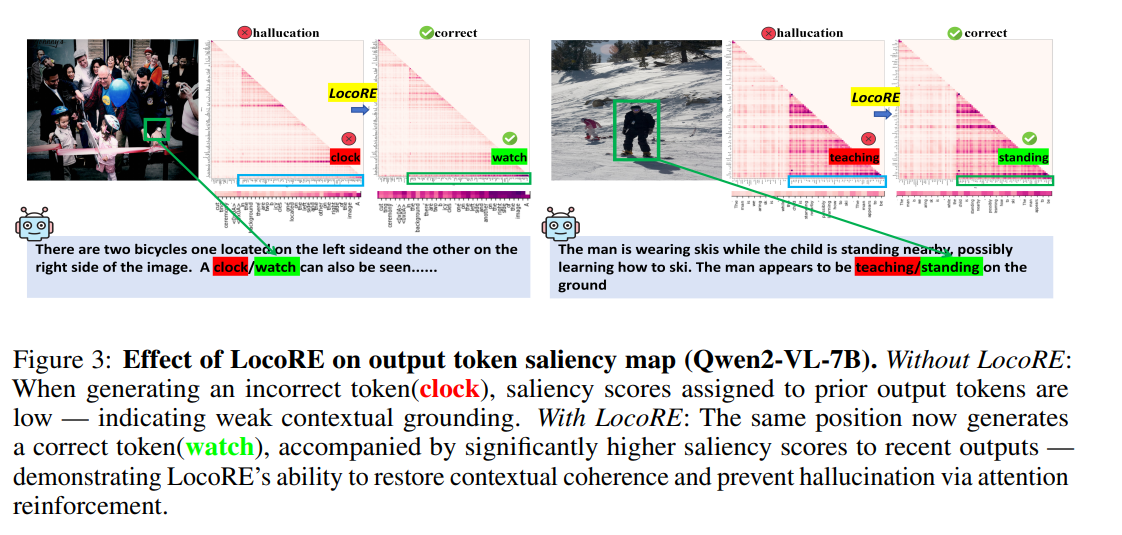
- LocoRE가 최근에 생성된 과거 토큰을 더 참조하도록 함으로써 성능을 크게 향상시킴
- Baseline에서 관찰되었던 “forgetting”을 대응하여 개선하였음
- Intra-output saliency decay를 줄여서 Hallucination을 줄였음
Conclusion
- Hallucination이 Weak Saliency와 연관됨을 밝힌 연구
- SGRS와 LocoRE를 통해 Visual Attention을 boost하고 local coherence를 강조함
- 별도의 Model Training 없이 Benchmark들에서 output 성능을 개선하는 효과를 보임