Small Transformers Don’t Need LayerNorm at Inference Time: Scaling LayerNorm Removal to GPT-2 XL and Implications for Mechanistic Interpretability
Review
| 닉네임 | Strength & Weakness & Sugguestions | 별점 (0/5) |
|---|---|---|
| 눈물 | • 강점 : 안정화를 위해 당연시(?) 사용되었던 LN을 부분적으로 제거함으로써 LLM의 추론 연산을 효율적으로 할 수 있음을 제시. LN을 제거하면 안정성이 떨어지므로, loss spike가 발생하는데, 이것을 낮추려면 fine-tuning이 더 필요할 거고, 비효율적이지 않나? 생각했지만, inference시에만 '부분적'으로 한다고 하니 효율적인 측면에서도 좋은 방법인 것 같음. 무엇보다 interpretability 측면에서는 큰 의미가 있다고 생각함. • 약점 : 물론 loss spike는 작은 모델에 한해서 심하게 튄다고 하지만, GPT-2 외에 더 큰 파라미터를 갖는 모델에서도 실험을 했으면 더 일반성이 좋았을 것 같음. • 보완점 : 파라미터가 더 많은 모델에 대한 실험을 통해 일반성 확보. | 3.8 |
| 덩쿠림보 | Layer norm을 대체하고 그것이 잘 작동하는지 실험하는 것은 매우 novelty하고 중요함! 전체적으로 sound하고, 제거했을 때, interpretability가 증가한 것은 좋은 결과임. 대신 layer norm을 제거했을 때의 취약점도 같이 서술했다면 좋았을 것 같음. 내 생각에는 좀 안정성이 떨어져서 다양한 task의 alignment가 제대로 수행되지 않을 수도 있겠다는 생각이 조금 듦. | 4 |
| thumps-up | • 장: 학습 안정성을 위해 제안된 LN이 오히려 interpretability를 해친다는게 나한텐 신기한 관점이었다! transformer decoder의 가장 클래식한 모듈인 GPT2에 대해 분석하는 것도 reasonable함 • 단: 흥미롭긴 한데 그래서 이게 뭐? • 보완: 다른 family에 대해서도 분석했으면 완성도가 훨씬 높았을듯! | 2.8 |
| 피땀 | • 강점: 당연히 필요하다고 생각했던 LN에 대해 추론 시점엔 없어도 된다는 점을 실험을 통해서 정량적으로 증명함 • 약점: GPT2은 너무 구형 모델임.. Llama, Qwen이나 Mistral 같은 현대 아키텍처에서도 일반화가 가능한지 실험해봤으면 좋았을 듯 (안한 이유가 있지 않을까?) • 보완점: 현대 모델 아키텍처에서도 꼭 분석해봤으면 함 | 2.2 |
| 웃으면서 보자 | 장점: 구조적 기능 분석, 효율적 관점, 흥미로운 관점과 기여, 실험. 단점: 문제점을 보이고 해결한 것이 아니라, 그냥 현상을 보고한 논문이라 조금 아쉬움. 결과에 대한 의심이 새록새록 보완점: 없애는 것에 대해 기능적이나 성능적으로 다양한 태스크 및 모델에 대해 평가했으면 함. 분석적으로. | 3.3 |
| 독수리오형제 | • 강점: LayerNorm이 inference에 필수적이지 않을 수 있다는 걸 실험적으로 잘 보여줌 • 약점: 더 다양한 모델군에서의 실험이 있으면 좋겠음. 또한 DLA error은 감소했지만 attribution patching은 좋아지지 않았음. Interpretability 관련한 이점이 전면적으로 개선되는거는 아닌듯 • 보완점: inference시 latency 관련해서 측정이 있으면 좋을것 같음. 그리고 trainning 시에서도 LN의 제거 영향이 궁금함 | 4.0 |
| 삐질 | • 강점: Layer norm이 비선형적 특성이 강한데, 이로 인해 LLM component들이 서로 얽혀있던걸 선형으로 바꿈으로써 특정 component의 역할을 분리하여 설명할 수 있다는게 가장 큼 • 약점: Layer Norm 제거하려면 추가적인 파인튜닝이 필요한데, 이에 대한 비용 분석 + 메모리가 얼마나 감소하는 지 분석 실험이 부재함 • 보완점: Reasoning task에 적용해봐서 추론 성능 or 시간에 대한 영향 분석 수행 | 3.8 |
| 팝콘 | • 장점: layer-norm을 모델 성능의 큰 손상 없이 보다 효율적인 모듈로 대체할 수 있음을 밝힘 • 단점: 이미 학습된 LLM에서 각 layer-norm 레이어를 부분적으로 제거하면서 복구하고 있는데, 처음부터 layer-norm 레이어가 없었더라도 기존처럼 학습이 잘 됐을까? • 보완점: 작은 모델로라도 layer-norm 없이 처음부터 훈련한 모델의 성능 비교 | 3.5 |
| 파이어 | • 장점: Layer-Norm을 제거하고도 같은 효과를 얻으면서 설명 가능성이 향상될 수 있다는 부분을 밝혀낸 것에 기여가 큼. • 단점: Layer-Norm을 제거하더라도 과연 학습이 잘될까? • 보완: Layer-Norm을 제거하고 실험하거나, 파인 튜닝한 결과와 비교한 실험이 추가되었으면 함. | 3.9 |
| 초콜릿 | • 장점: LN을 제거한 후 모델이 overconfident해진다는 것을 논문에서 언급하고 분석한 점이 좋았음 • 약점: DLA error는 줄었는데, attribution patching error는 대로 남아있어서, LN을 제거하면 interpretability가 좋아진다는 주장이 완전하지 않은것 같았음. • 보완점: Attribution patching error가 왜 개선되지 않는지 원인 분석이 있었으면 좋았을것 같다 | 3.5 |
TL; DR
Layer normalization은 training stability에는 중요하지만, inference 단계에서는 꼭 필요하지 않을 수 있다! GPT-2 의 모든 LayerNorm을 제거하여 보여줌
Summary
- 연구진

- 인용수: 5
- openreview forum : https://openreview.net/forum?id=VPtHqcafIY
- 리뷰어들에게는 8,8,8,6점을 받았지만, AC는 meta reiew 에서 “rejection-like” meta review를 주었음! 한번 읽어보시는 걸 추천 ~~
Background & Motivation
- Layer Normalization Layer
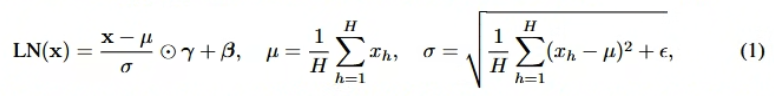
- ⊙ : Hadamard (element-wise) product
- 학습 단계에서의 stabilize를 위한 Layer 임
- 선행연구에서는 LN이 confidence regulation에 기여한다고 밝히기도 했음
- 미리 학습해둔 값을 사실상 linear transformation처럼 쓸 수 있는 Batch normalization 과 달리, LN은 inference때 매번 수행해야 하는 연산임. (=non-linear function)
- LN의 non-linearity로 인해, model의 mechanistic interpretability가 방해됨
- mechanistic interpretability 란? 모델을 더 작은 component의로 분해하고, 각 component의의 개별적인 효과와 상호 작용을 이해하는 것
- why? LM이 residual stream activation에 따라 각 component(=sublayer, head, …)가 영향을 받기 때문
- Eq (1) 에서, 현재 시점에서의 평균을 빼고 std를 나눠서 정규화하는데, 각 단계에서의 평균, std가 다 다르기 때문에 뒤 단계까지 영향을 끼침
- 그래서 기존 interpretability 연구에서는 NL을 linear transformation으로 근사화해서 수행했음
- 참고 논문:
- [ICLR’24] Copy Suppression: Comprehensively Understanding an Attention Head https://openreview.net/forum?id=g8oaZRhDcf
- but, 정확하지 않고, 이렇게 학습된 모델은 실제 LLM과 다름
- 참고 논문:
- 또는 아예 LN 을 없애고, element-wise tanh function을 사용함
- but, 여전히 non-linear function이기 때문에 interpretability 연구에 부적합
⇒ 이미 학습된 실제 transformer에서 LN을 제거한 버전을 분석해보자 !!
Contributions (What they’ve revealed)
transformer로부터 LN을 제거하였음 & LN layer 없이도 작동하며, original model과 유사한 cross-entropy loss를 달성할 수 있음을 보임
- FakeLN block 정의
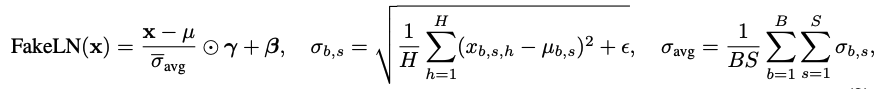
- standard deviation 대신에, fixed scalar 사용
- BS: batch size
- 구체적인 removal process
- 0번째 MLP layer의 LN ( ) 를 제거하고 fine-tuning
- 1번째 MLP layer의 LN ( ) 를 제거하고 fine-tuning
- …
- 0번째 query/key LN ( ) 을 제거 하고 fine-tuning
- 1번째 query/key LN ( ) 을 제거 하고 fine-tuning
- …
- 0번째 value LN ( ) 을 제거 하고 fine-tuning
- 1번째 value LN ( ) 을 제거 하고 fine-tuning
- …
- Final NL 제거
- 한번에 없애지 않는 이유?
: 모든 LN을 한 번에 없애면 모델 성능이 회복 불가능하게 붕괴하기 때문에, LN block을 하나씩 제거하고 loss spike가 가라앉을때까지 (일정 step만) fine-tuning함
- LN layer 제거를 보다 안정적으로 수행하기 위한 Auxiliary loss 활용
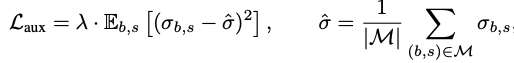
- λ: hyperparameter
- Limitations에서 언급하길, GPT2-large/XL model을 안정화하기 위해 추가적으로 도입한 loss라고 함 !!
- 학습 결과
- training loss
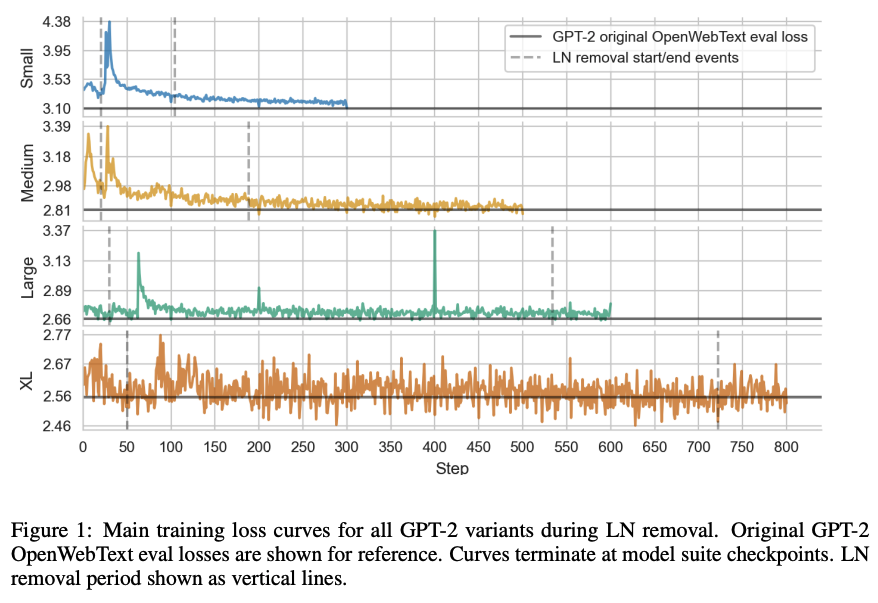
- 학습 이후에도 비슷한 cross entropy loss를 달성함

- training loss
- FakeLN block 정의
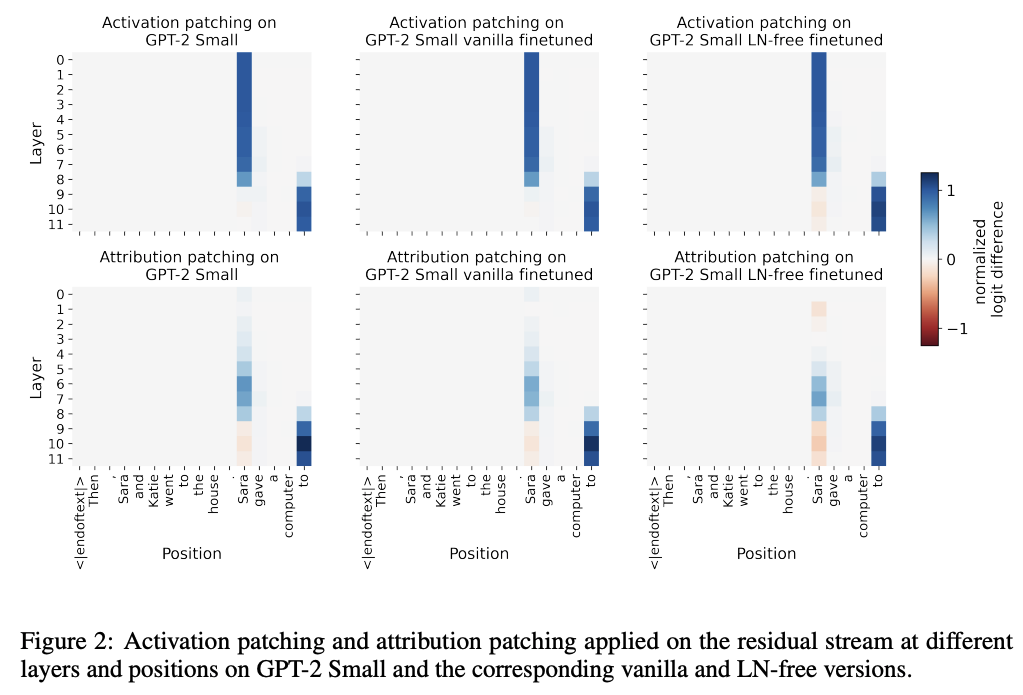
LN layer가 없을 때 model의 interpretability가 향상되었음을 검증
: 기존 interpretability 분석 연구에서 많이 활용되는 direct logit attribution (DLA), attribution patching 사용
- LN layer가 없을 때 DLA error가 50% → 0%로 감소함
- direct logit attribution(DLA)란?
- 어떤 component의 direct effect(=특정 component가 중간 component를 거치지 않고 output에 주는 효과)를 선형 근사로 추정하는 방법
- 기존 LN은 nonlinearity를 가지고 있기 때문에, DLA가 근사화됨
⇒ 이예 따라 DLA와 DE간의 차이(=error)가 있을 수 밖에 없음!
- DLA가 DE와 평균적으로 얼마나 어긋나는가를 평가하기 위해 Normalized Mean Absolute Error (NMAE) 활용하여 측정
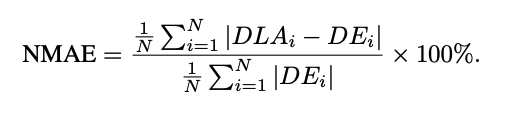
- w/LN 49.07% → w/FakeLN 0.00%로 감소함
- direct logit attribution(DLA)란?
- attribution patching은 LN layer 유무와 무관함
- activation patching이란?
: 어떤 내부 activation이 정말로 원인인지 확인하기 위해, 정답을 잘 맞히는 clean prompt에서 나온 activation을 corrupted prompt에서 나온 activation에 같은 위치로 대체하여, 각 component의 결과를 관찰하는 방법
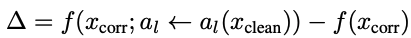
⇒ 정확하지만, 실제로 activation을 하나하나 바꿔 넣으면서 확인해야 하기에 연산량 커짐
- attribution patching이란?
: activation patching의 first-order Taylor approximation

⇒ 근사하는 과정에서 attribution patching errors 발생
- 결과
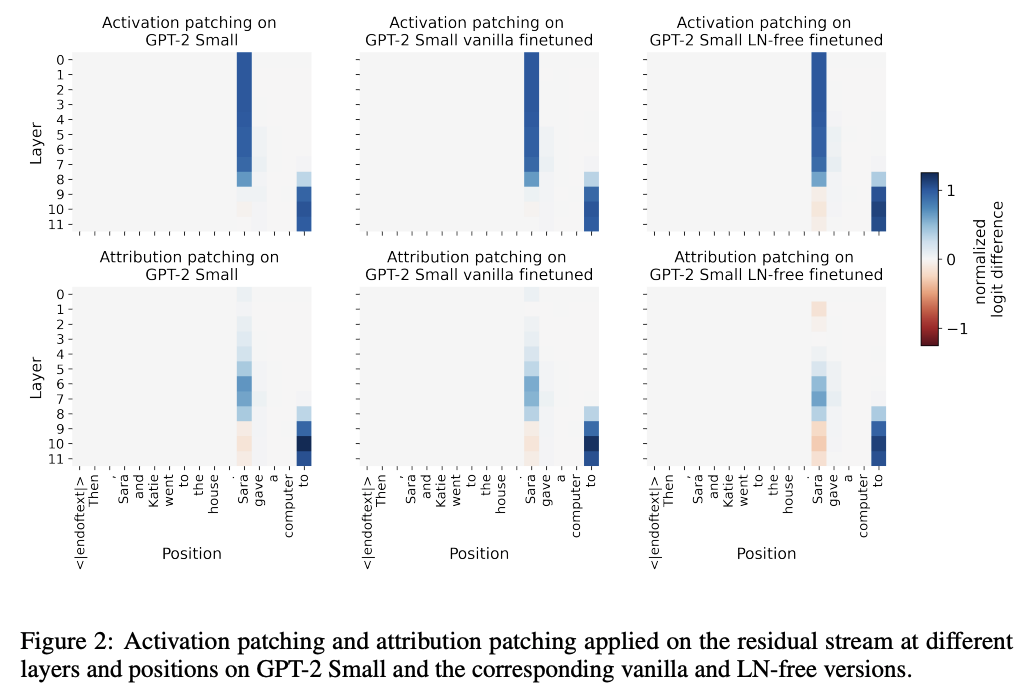
- LN free model이라고 해도, attribution patching errors 는 여전함
- activation patching이란?
- LN layer가 없을 때 DLA error가 50% → 0%로 감소함
추가 분석 수행
- LN layer가 residual stream geometry를 어떻게 바꾸는가
- 선행연구에서, “first position token의 hidden representation L2 norm이 유난히 크며, 이는 attention sink의 핵심 mechanism임”을 밝혔음
- NL-free model에서도 같은 현상이 나타나는지를 관찰함
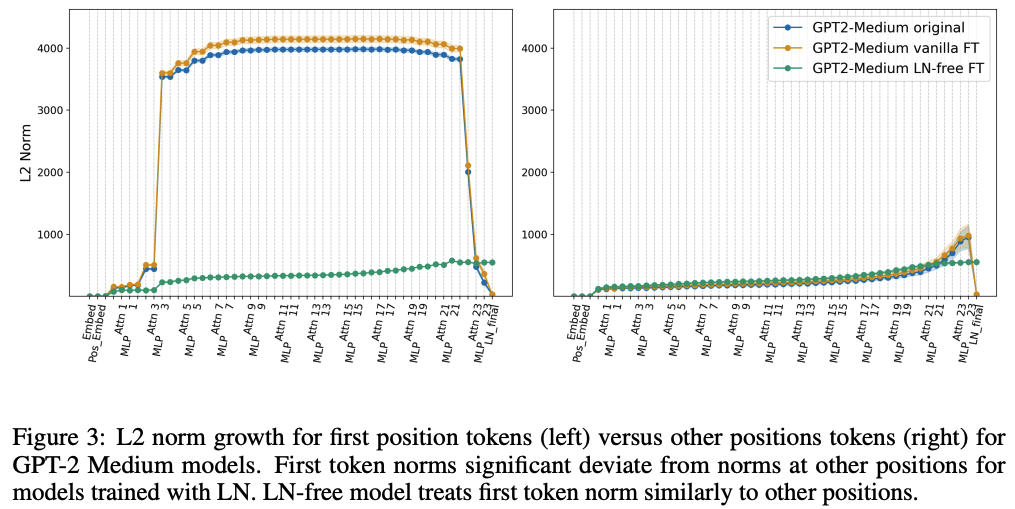
- LN-free model은 first token을 다른 token과 거의 동일하게 취급함
- attention sink rate도 55.3% → 45.3%로 감소함
- LN-free model은 조금 더 overconfident함
- LN-free model을 개발하는 와중에, GPT-2 Medium의 경우, 출력 분포의 평균 엔트로피는 2.86 → 2.53 으로 감소함을 발견
- 이에 따라, entropy neuron(=confidence neuron)을 분석해봄
- 기존 연구와 동일한 방법으로 발견 및 분석 수행함
: weight norm이 크고, 모든 output logit에 거의 같은 영향을 주는 (token ranking 자체를 바꾸지 않는) neuron
- 결과 분석
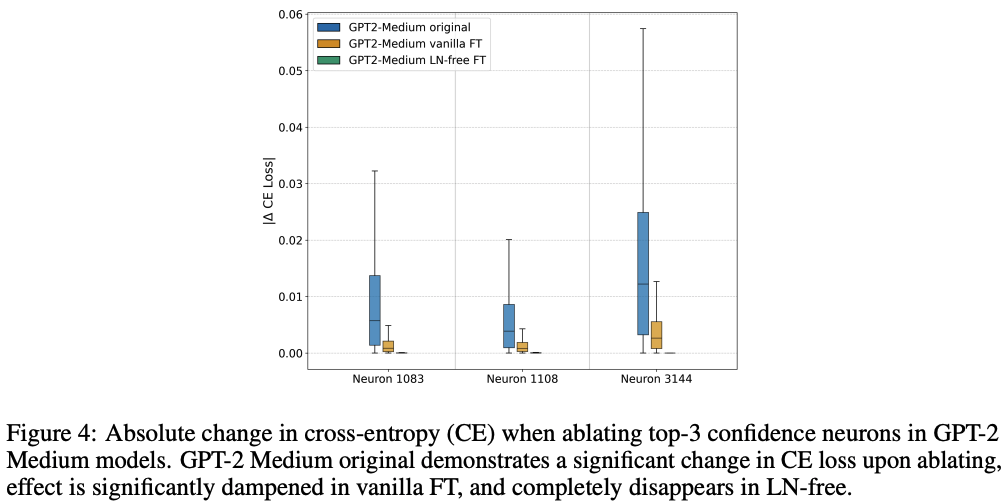
- entropy neuron인 1083, 1108, 3144의 cross entropy loss 값이 NL-free에서 크게 감소함
⇒ 즉, confidence neuron이 기능을 하지 않음
- entropy neuron인 1083, 1108, 3144의 cross entropy loss 값이 NL-free에서 크게 감소함
- 기존 연구와 동일한 방법으로 발견 및 분석 수행함
- LN layer가 residual stream geometry를 어떻게 바꾸는가