27 March 2026
Temporal Sparse Autoencoders: Leveraging the Sequential Nature of Language for Interpretability
ICLR'26 Oral
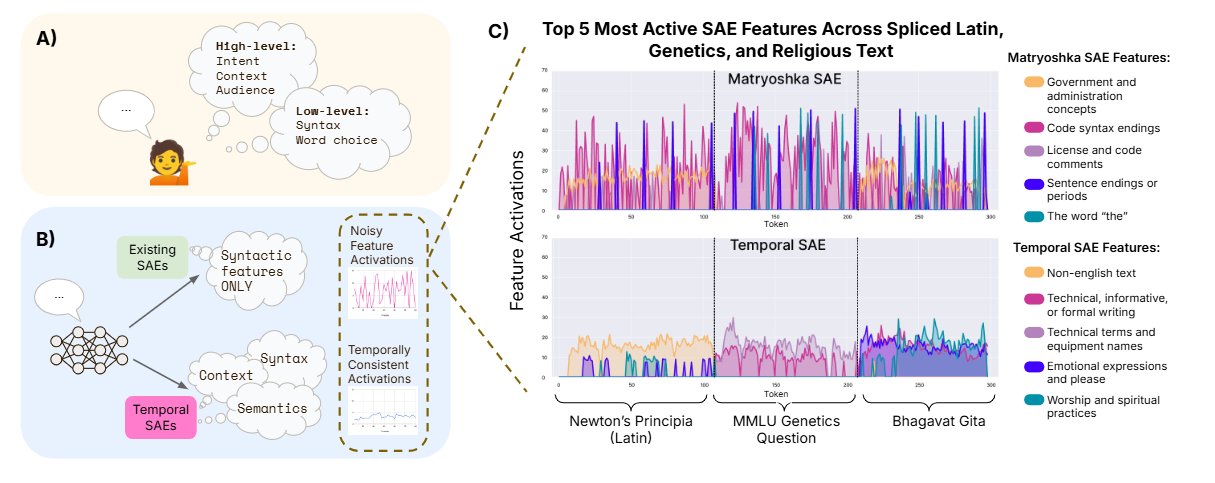
💡기존 SAE는 토큰을 독립적으로 처리하기 때문에 구문 정보에 편향되어 의미를 잘 포착하지 못한다. ⇒ 언어의 시간적 구조(인접 토큰 간 고수준 의미가 유사하다는 성질)를 SAE에 추가하자!
27 March 2026
Small Transformers Don’t Need LayerNorm at Inference Time: Scaling LayerNorm Removal to GPT-2 XL and Implications for Mechanistic Interpretability
ICLR'26 Poster
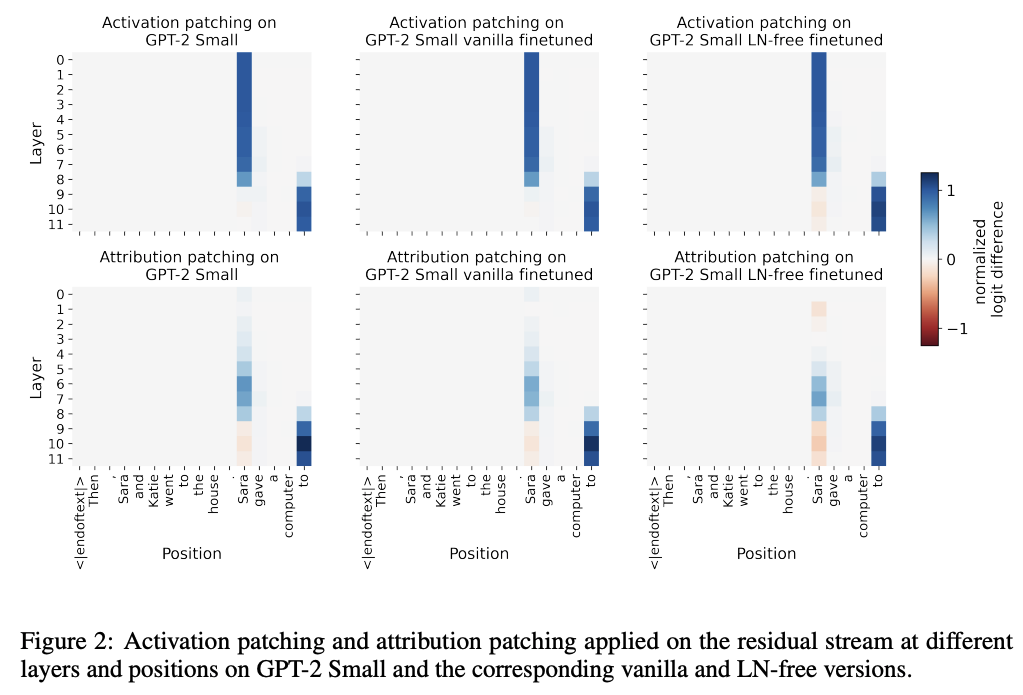
💡Layer normalization은 training stability에는 중요하지만, inference 단계에서는 꼭 필요하지 않을 수 있다! GPT-2 의 모든 LayerNorm을 제거하여 보여줌