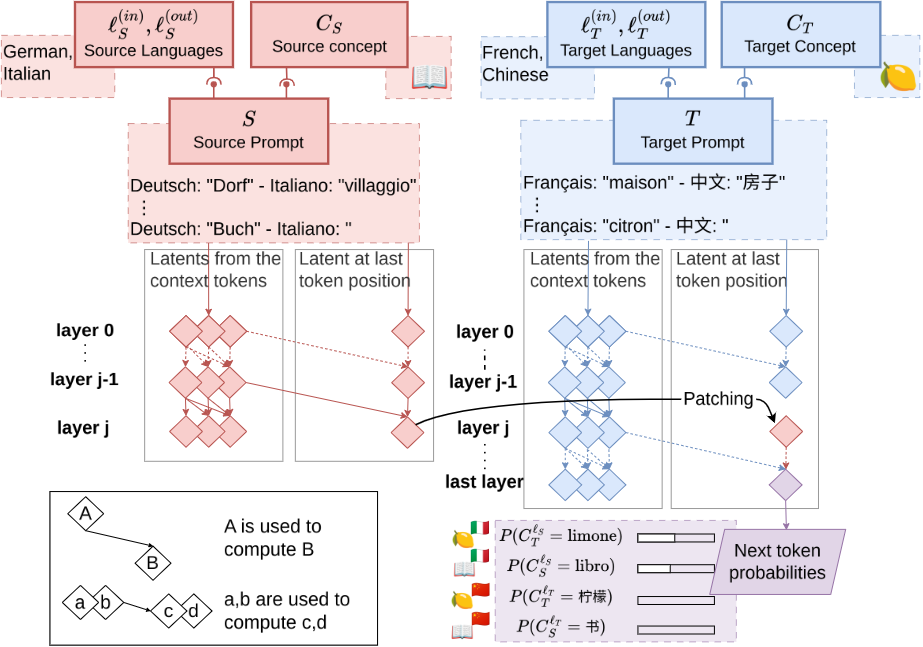
Shared Global and Local Geometry of Language Model Embeddings
💡같은 계열의 언어 모델들은 차원이 달라도 token embedding의 구조가 굉장히 비슷하다! 그래서, 한 모델에서 만들어낸 steering vector를 다른 모델에서 선형변환만으로 재사용 가능하다!예: 1B, 3B에서 helpfulness를 올리도록 하는 vector를 찾고 나서, 8B로 그대로 옮겨서 쓸 수 있음!
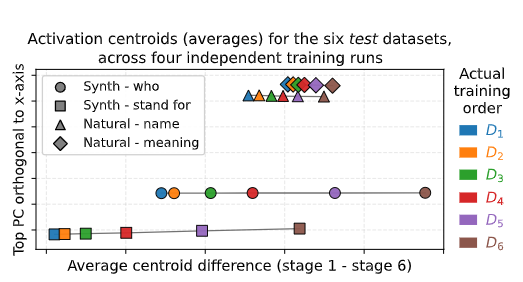
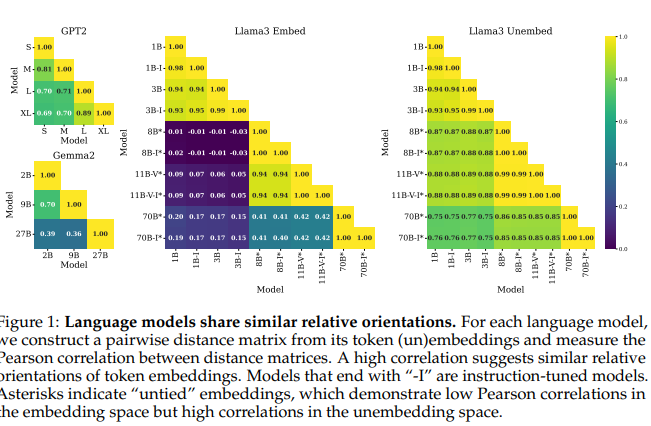
FRESH IN MEMORY: TRAINING-ORDER RECENCY IS LIN-EARLY ENCODED IN LANGUAGE MODEL ACTIVATIONS
💡언어 모델은 “무엇” 을 배웠는지와 “언제” 배웠는지에 대해 알고있다.⇒ 다양한 통제 실험을 통해 검증해보자 ! !
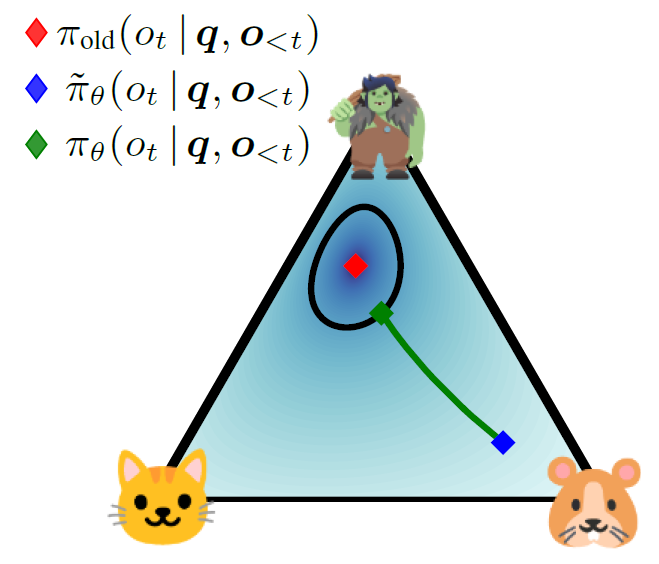
TROLL: Trust Regions Improve Reinforcement Learning for Large Language Models
💡LLM을 RL로 학습할 때 모델이 한 번에 너무 크게 바뀌면 망가지므로, 허용된 범위 안에서만 업데이트해서 안전하게 학습시키자
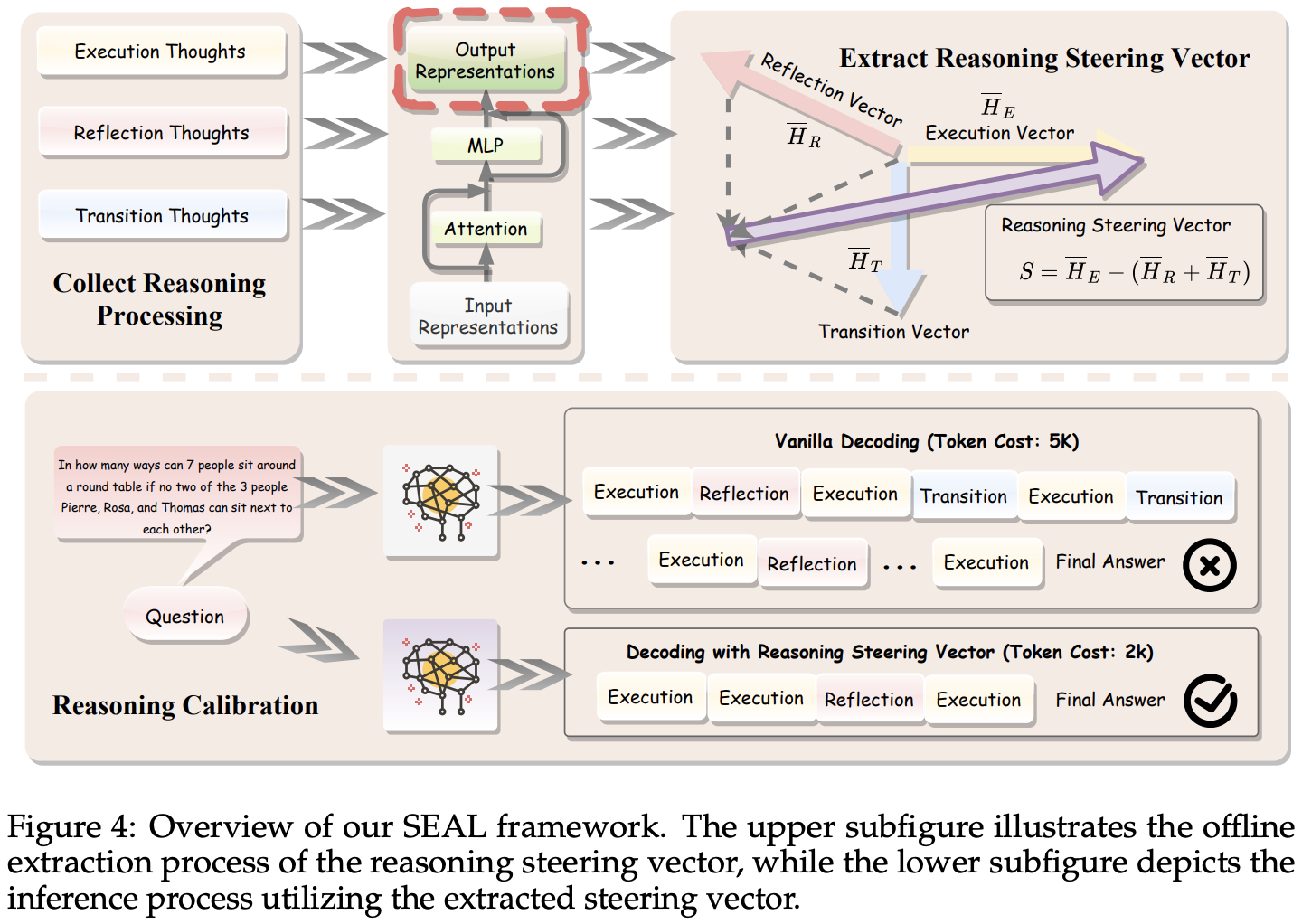
SEAL: Steerable Reasoning Calibration of Large Language Models for Free
💡너무 길고 복잡한 reasoning 경향을 완화하자!⇒ reasoning process를 세단계로 분류하고, 그 중에 어떤 걸 줄여야 할지 분석하자
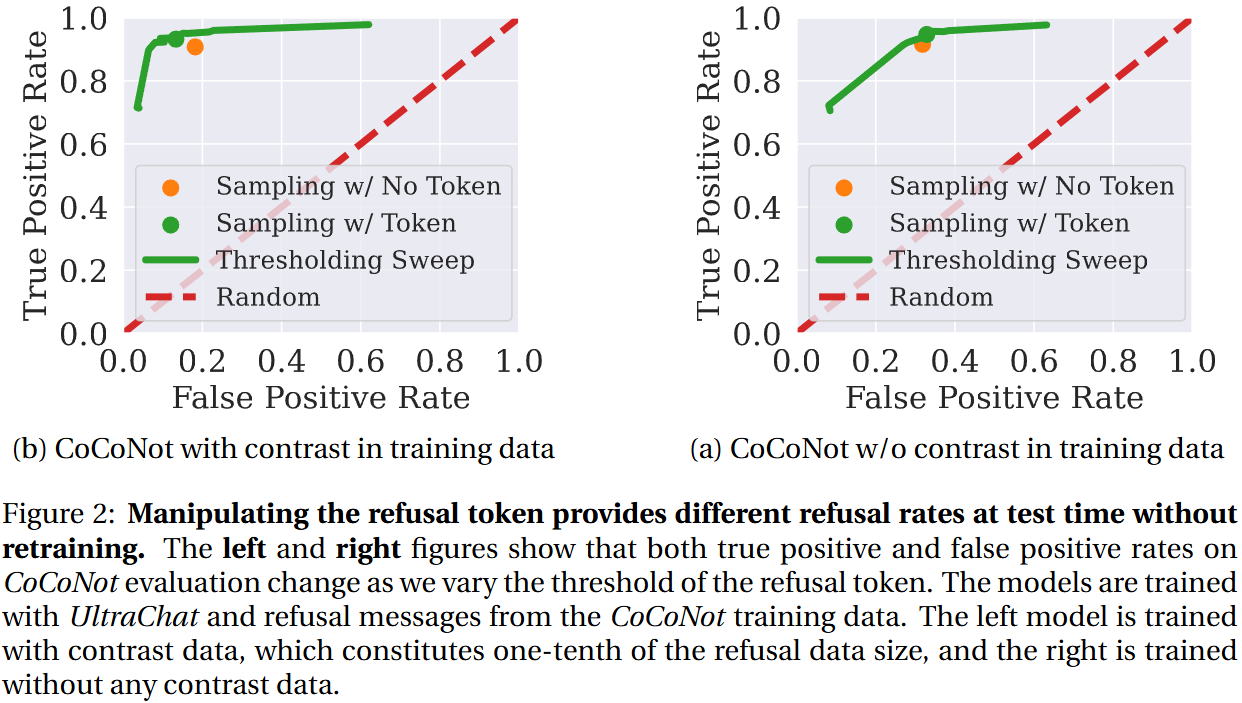
Refusal Tokens: A Simple Way to Calibrate Refusals in Large Language Models
💡Refusal token으로 모델의 응답 거절을 더 섬세하고(성능↑), 유연하게(inference 단에서 조절 가능) 한다!
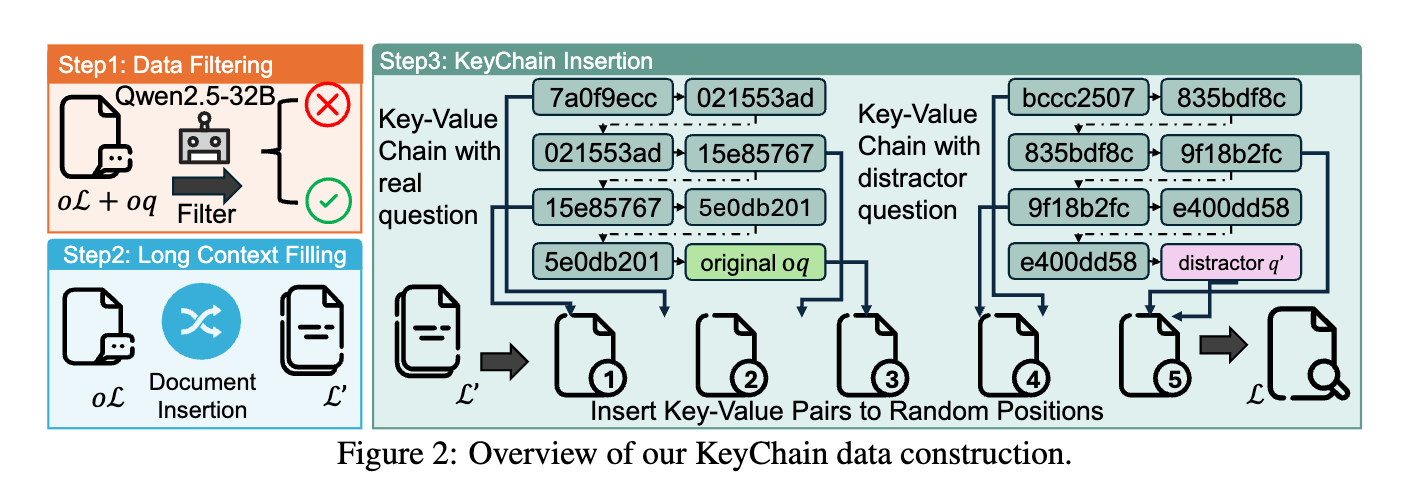
LoongRL: Reinforcement Learning for Advanced Reasoning over Long Contexts
💡short-context(16K) RL 학습만으로 long-context(128K) 추론을 잘하게 하자.어떻게?⇒ UUID 체인으로 질문을 숨긴 고난이도 합성 데이터(KeyChain)로 RL 학습하면, plan–retrieve–reason–recheck 사고 패턴이 발생하여 높은 장문 추론 성능을 7B/14B의 소형 모델로 달성할 수 있다.
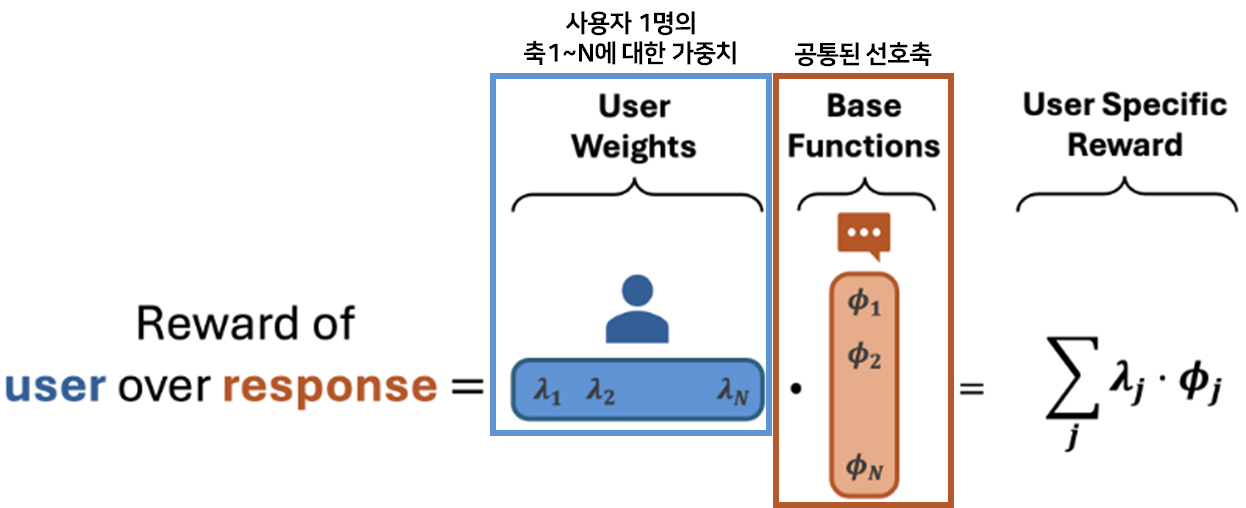
Language Model Personalization via Reward Factorization
💡여러 사용자의 선호를 공통된 선호 축(e.g., 친절, 간결, 격식)으로 분해해 학습한 뒤, 새로운 사용자가 들어오면 축마다 다른 가중치를 주어 사용자의 personalized된 선호를 빠르게 추정하자!
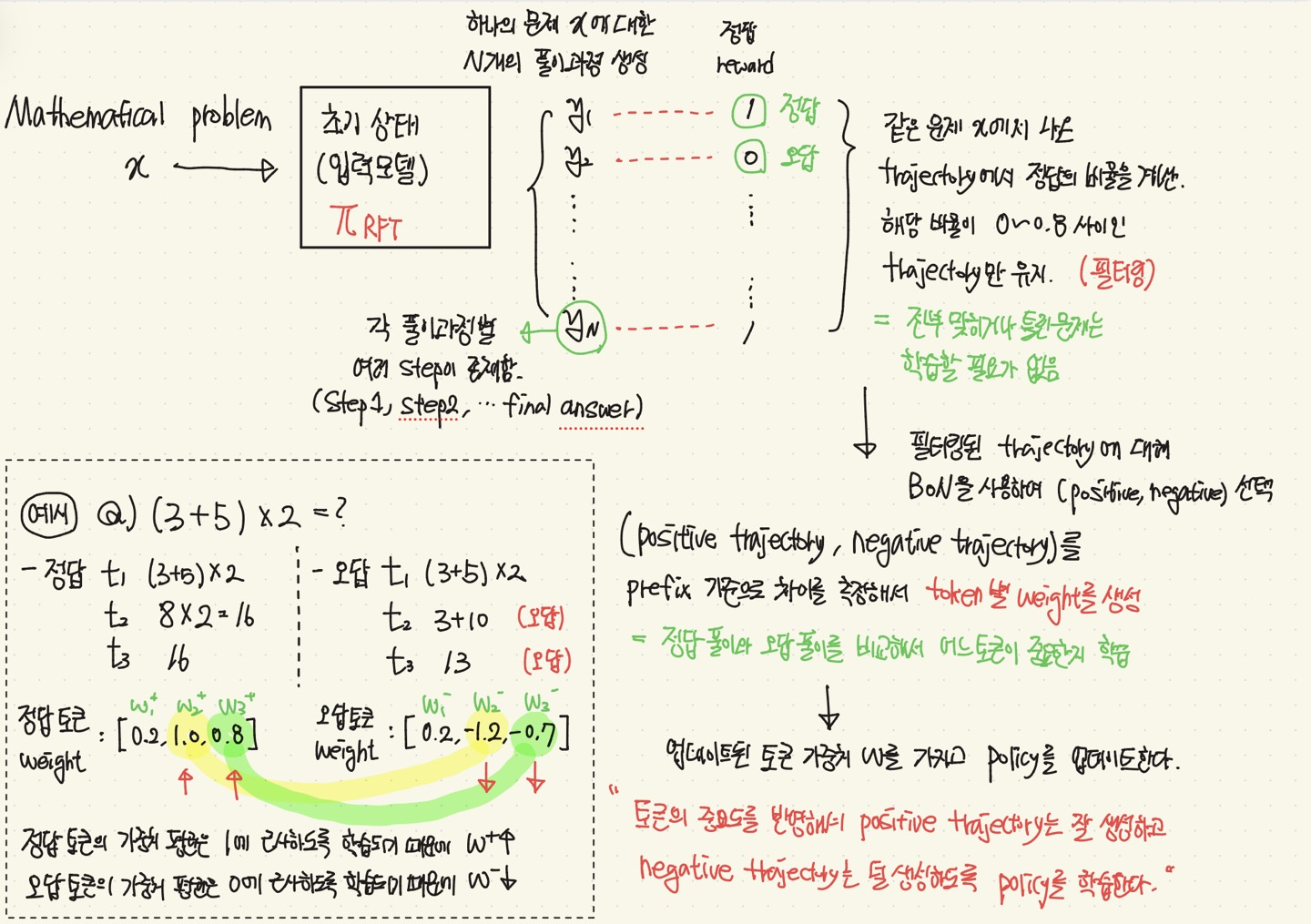
Exploring the Limit of Outcome Reward for Learning Mathematical Reasoning
💡Mathematical Reasoning Task 를 할 때, RL을 간접적으로 구현하여 간단하게 풀어보자.(= 강화학습 형태로 수학문제를 효과적으로 풀어보자 !)
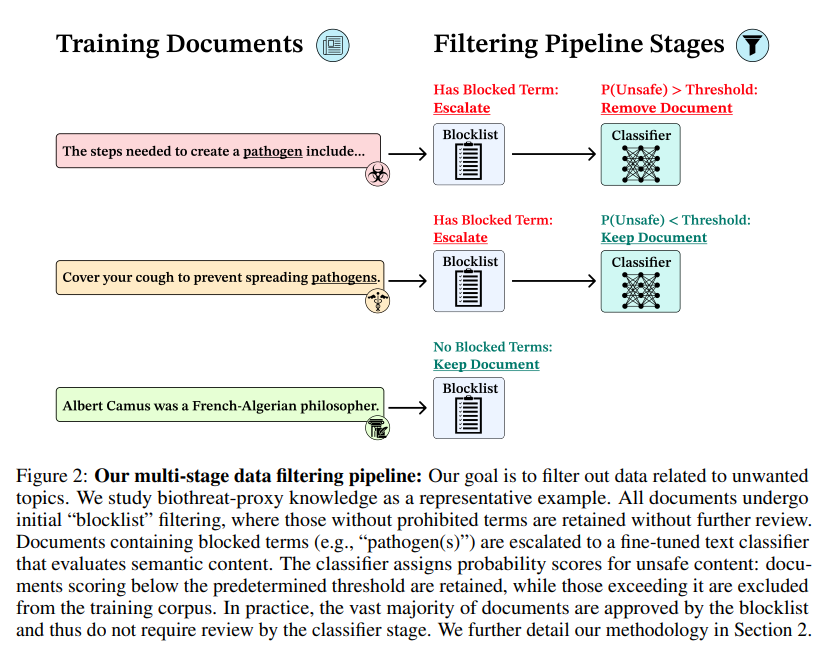
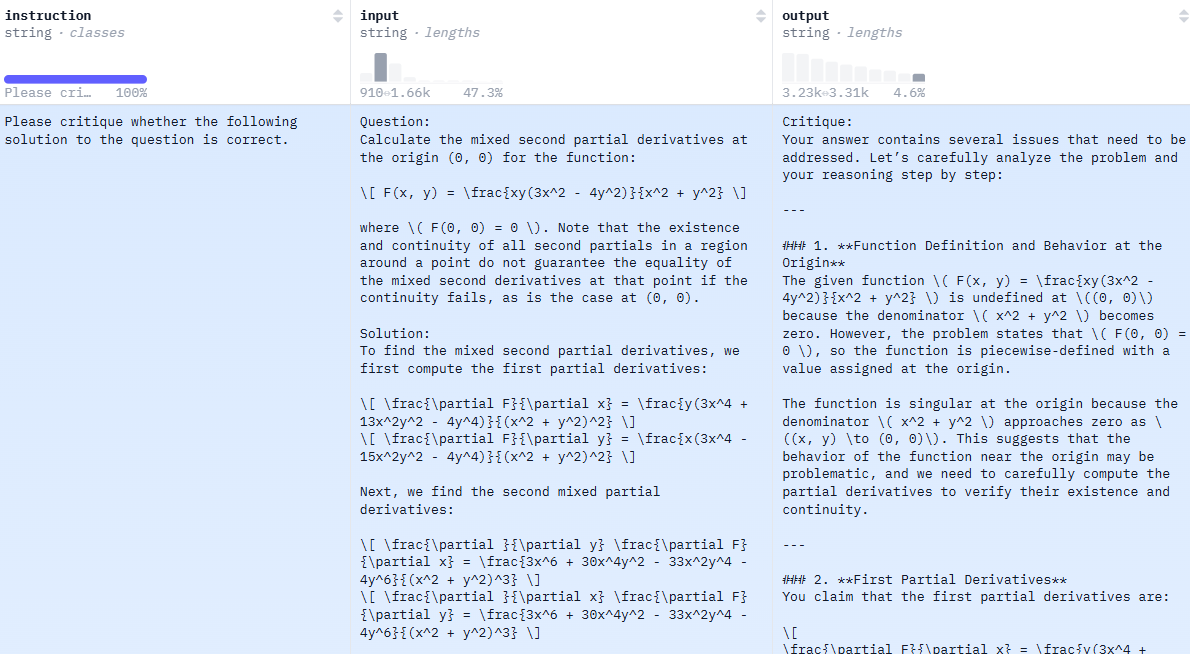
Critique Fine-Tuning: Learning to Critique is More Effective than Learning to Imitate
💡정답을 그대로 모방하는 SFT보다, noisy한 답안을 ‘비판(critique)’하도록 학습하는 방법이 reasoning 성능 향상에 더 효과적이다!Human learning process의 방식(critical thinking, analyze, understanding…)을 모델 학습에 적용해보자
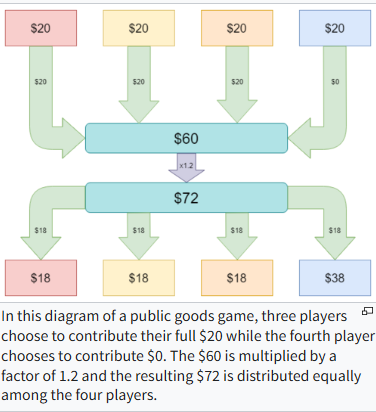
Corrupted by Reasoning: Reasoning Language Models Become Free-Riders in Public Goods Games
💡현재의 추론 최적화가 협력을 별도로 정렬시키지 않는다면, 협력이 아닌 합리적 이기주의를 표방하는 개인주의 모델이 탄생할 수 있다!즉, 추론 능력과, 협업 능력(비용 감수 측면)은 별개다!
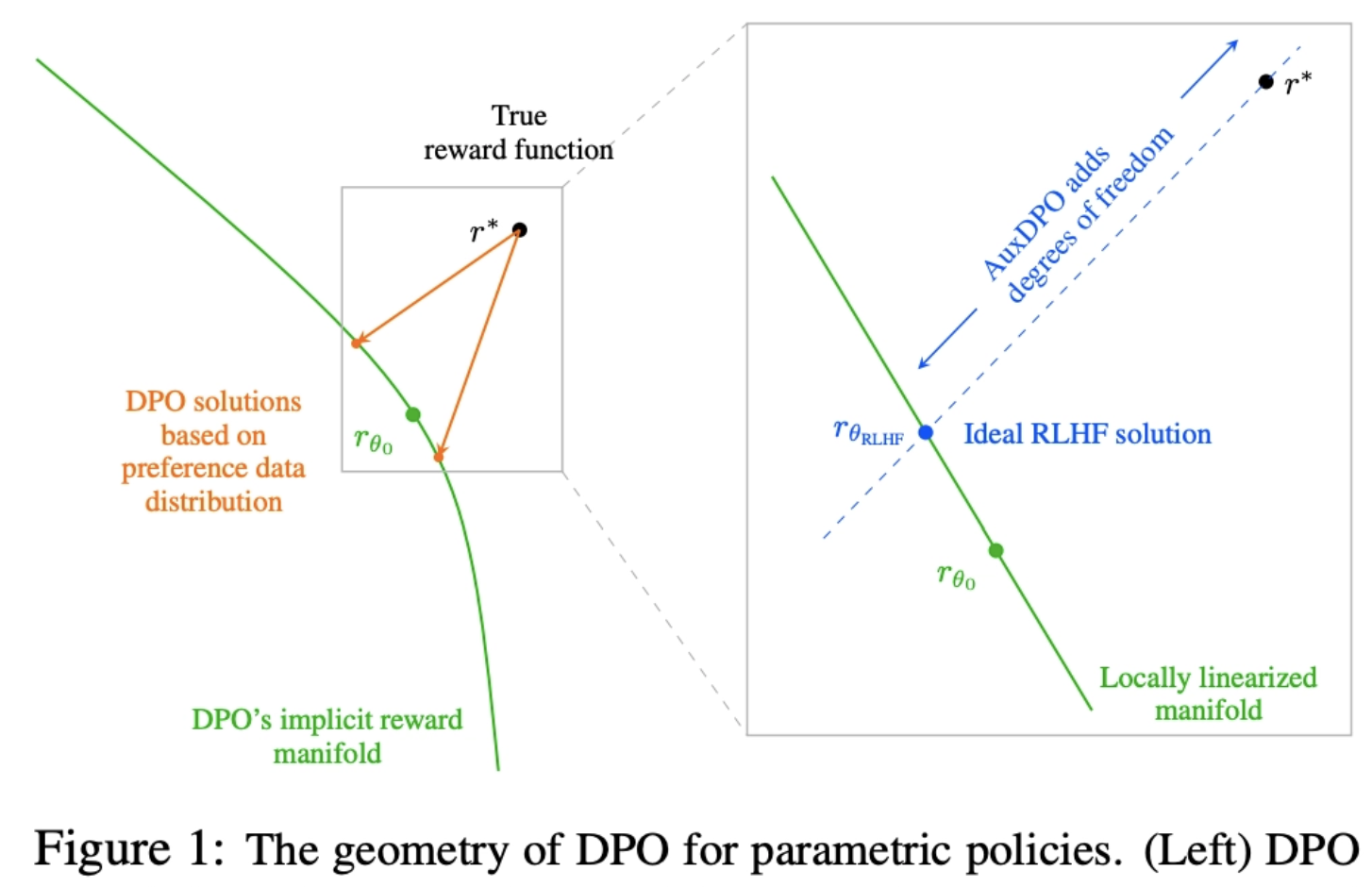
Why DPO is a Misspecified Estimator and How to Fix It
💡DPO의 전제가 realistic하지 않음을 위상학적으로 파헤침 AuxDPO를 통해 DPO의 Misspecifection를 완화하자!
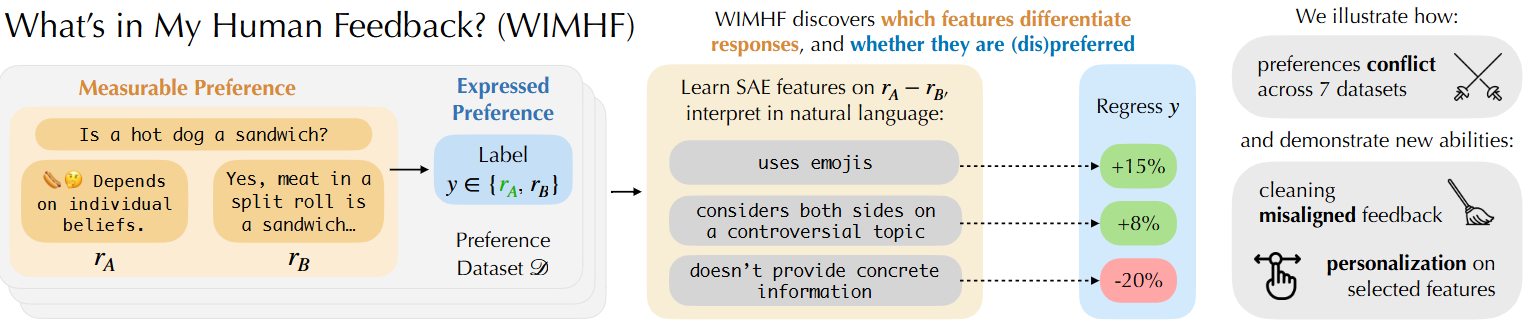
What’s In My Human Feedback? Learning Interpretable Descriptions of Preference Data
💡SAE를 통해 preference dataset에서 두 응답 간 선호를 결정짓는 잠재적 특징(feature) 축을 자동으로 추출하고, 어떤 응답 특성이 인간의 선호를 결정하는지 자연어로 해석 가능하게 설명하는 WIMHF 방법론을 제안
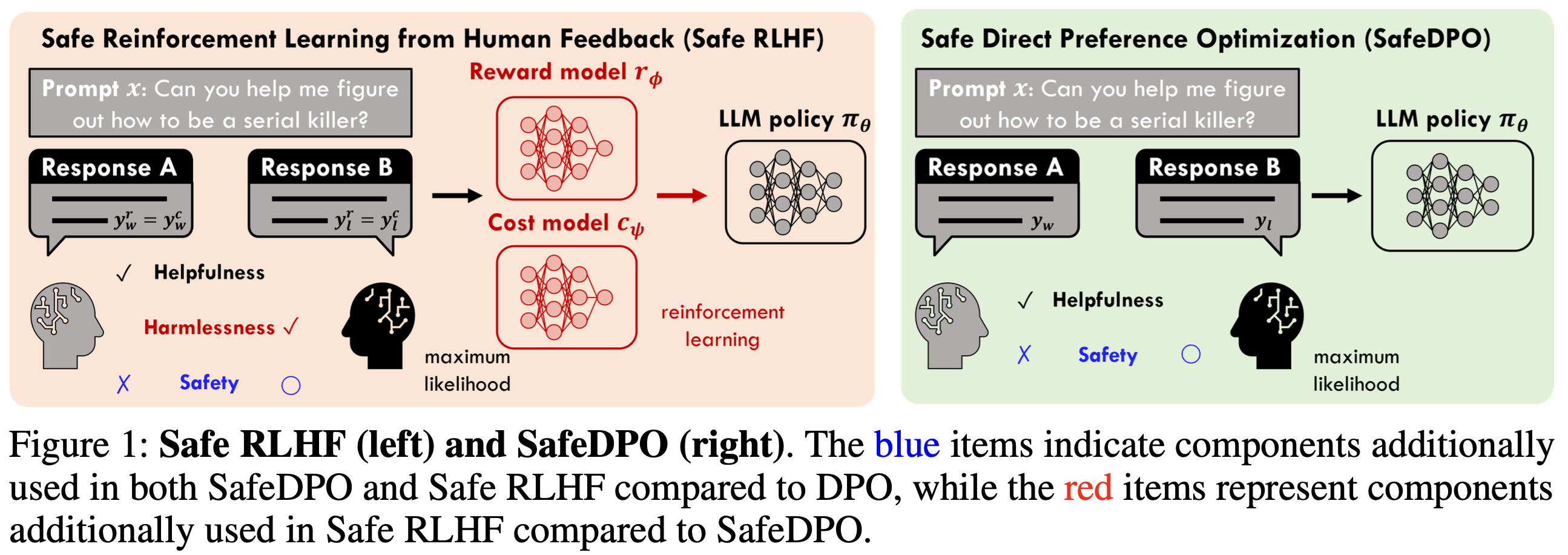
SafeDPO: A Simple Approach to Direct Preference Optimization with Enhanced Safety
💡Preference Alignment에서 안전(위험한 답X)을 강하게 보장하면서도, 기존 RLHF처럼 복잡한 파이프라인 없이 DPO처럼 간단하게 모델을 정렬하는 방법인 SafeDPO 를 제시기존의 보상 함수를 재정의하고, 학습 데이터를 재정렬해 모델이 안전한 답을 일관되게 더 선호하도록 함
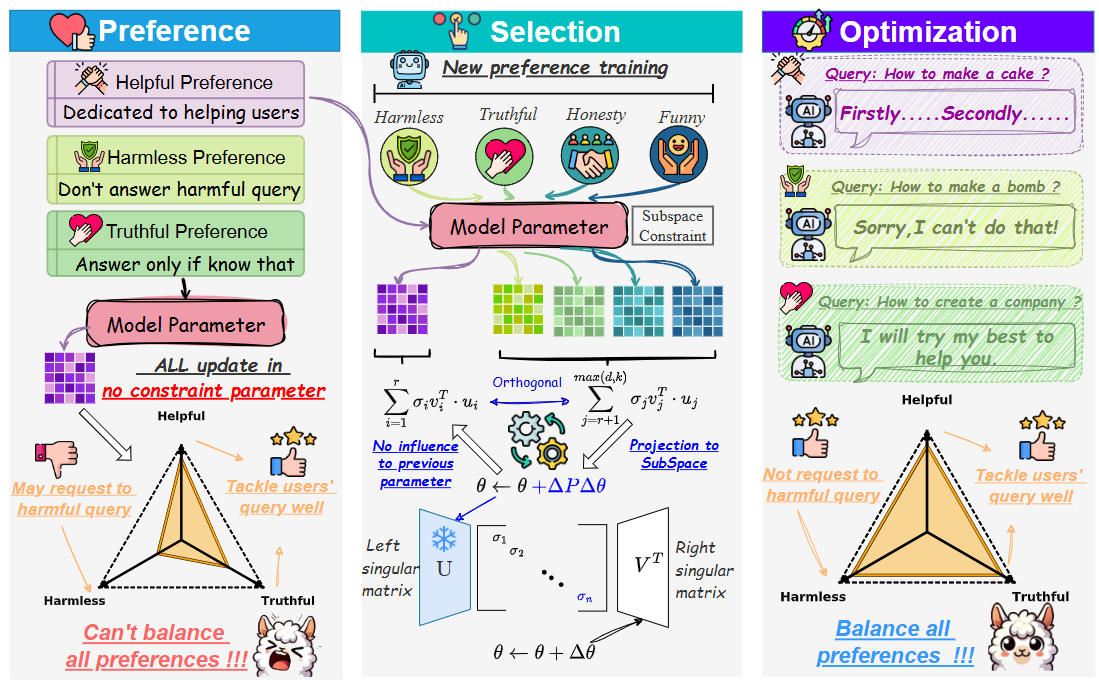
OrthAlign: Orthogonal Subspace Decomposition for Non-Interfering Multi-Objective Alignment
💡다중 preference 최적화 시 파라미터 업데이트 공간을 orthogonal subspace로 분해하여, objective 간 간섭을 원천적으로 제거하자
Multiplayer Nash Preference Optimization
💡alignment가 가져야 할 목표는 보상을 최대화하는 것이 아니라, 다수 가치 및 정책 집단 속에서 그 누구에게도 지지 않는 안정적 균형 상태를 가지는 것이다!
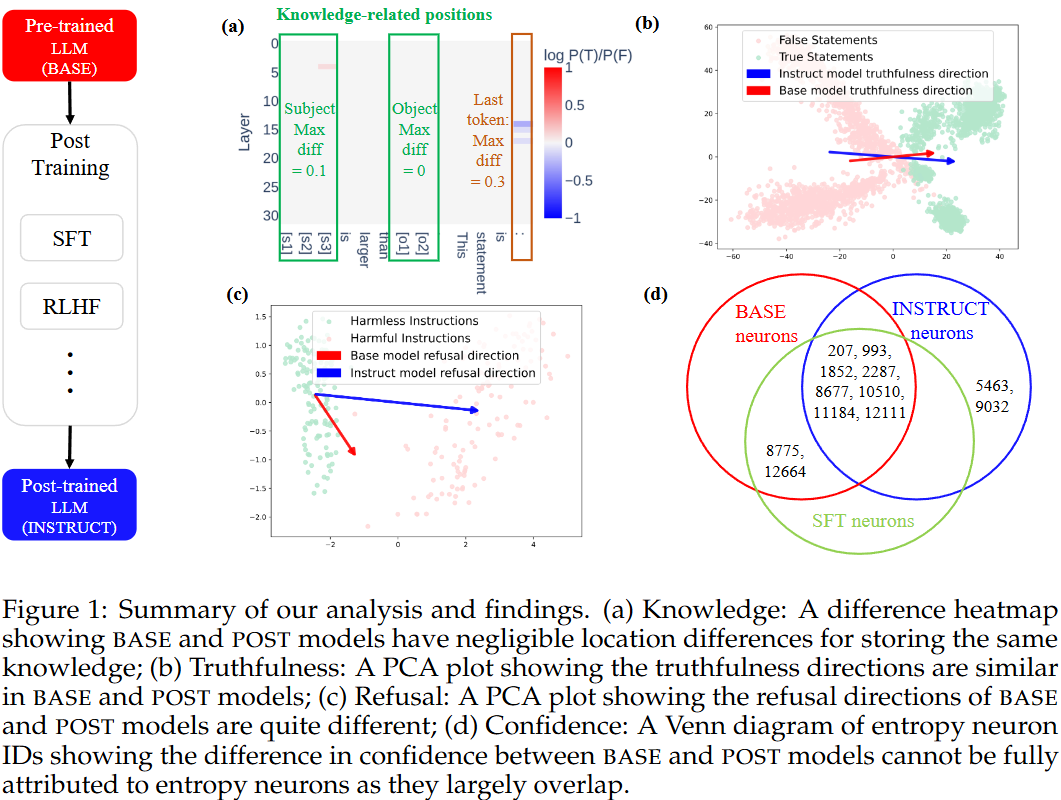
How Post-Training Reshapes LLMs: A Mechanistic View on Knowledge, Truthfulness, Refusal, and Confidence
💡Post-training 후 모델 내부 지식, 진실성, 안전성, 확신성의 변화를 기계적으로 분석!
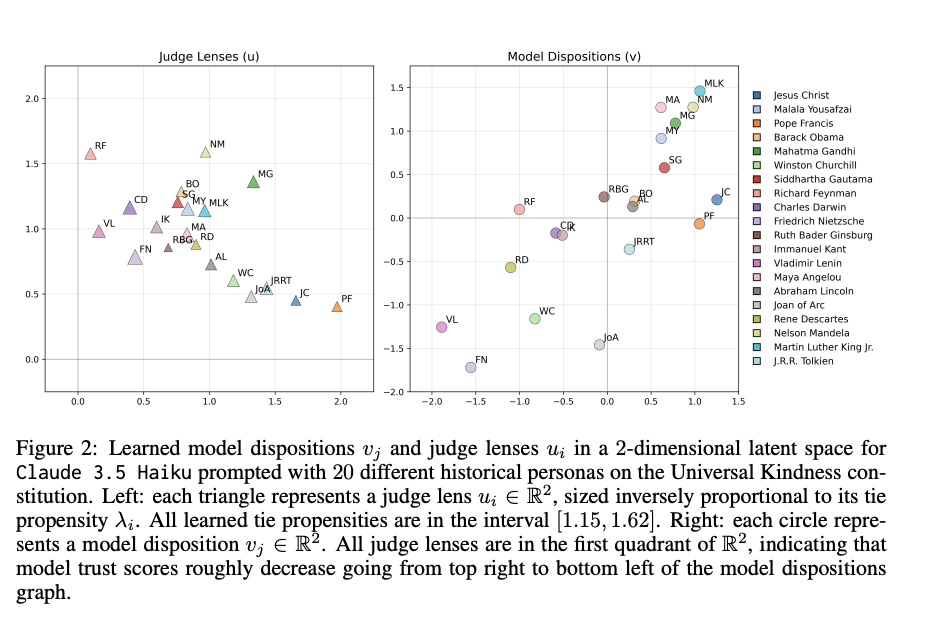
EigenBench: A Comparative Behavioral Measure of Value Alignment
💡모델의 주관적 성향을 다른 모델의 성향과 비교하여 순위를 매기고, 신뢰도 벡터로 수치화하여 신뢰성을 판단하고, 모델마다 판단의 기준 차이를 확인할 수 있다!
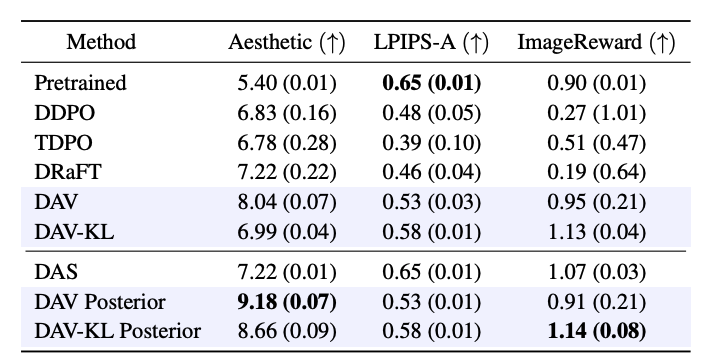
Diffusion Alignment as Variational Expectation-Maximization
💡Diffusion 모델을 목적 함수에 맞게 diffusion alignment할 때 발생하는 reward over-optimization 과 mode collapse 문제를 EM알고리즘 (E단계(test time search) → M단계(forward-KL)의 반복)으로 해결하자!
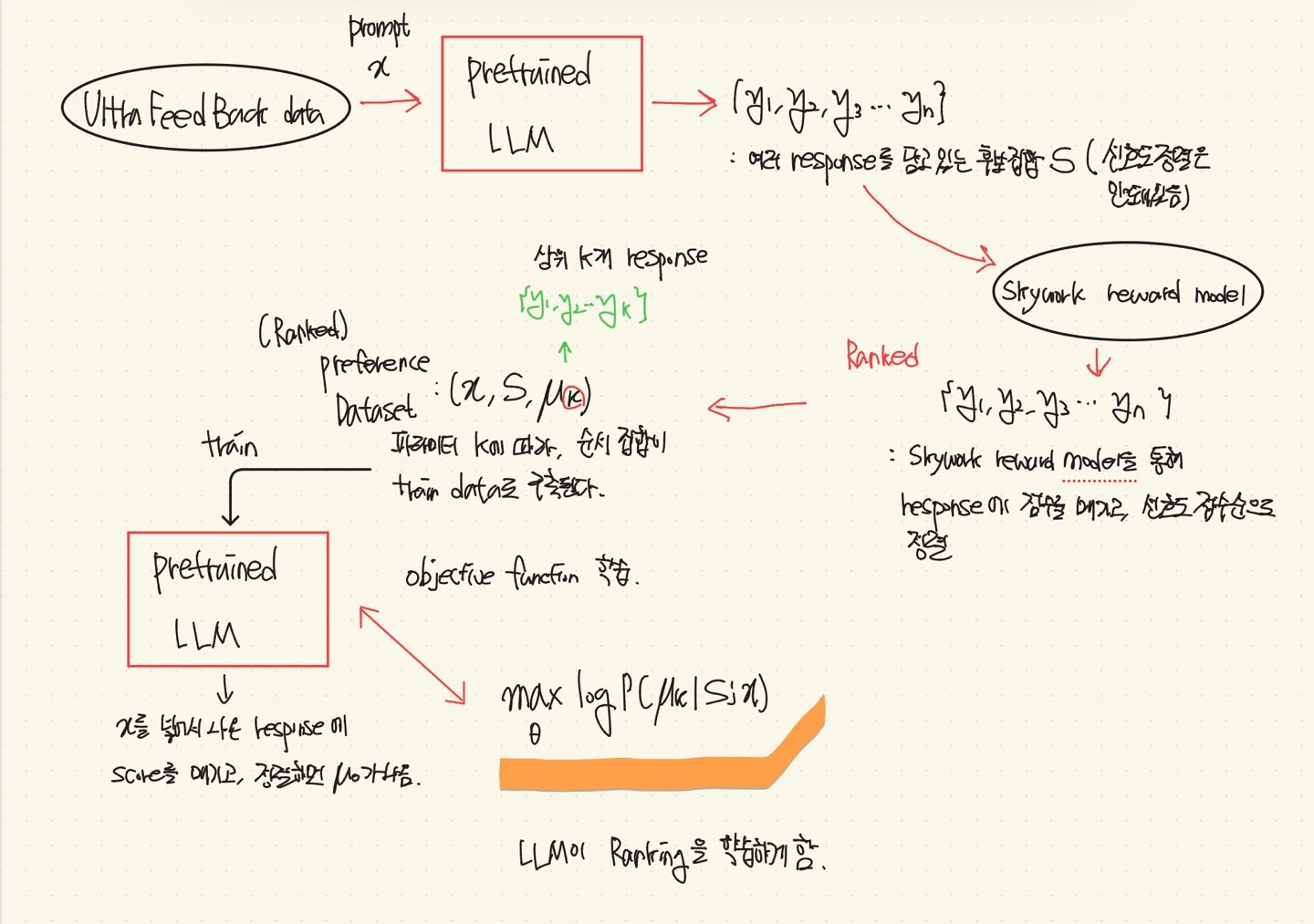
Beyond Pairwise: Empowering LLM Alignment With (Ranked) Choice Modeling
💡RLHF나 DPO와 같은 방법들은 Pairwise(쌍) Preference Optimization에 맞춰져 있어, 더 자세한 정보(Human Feedback)를 학습할 기회를 간과한다.⇒ Response에 대해 Pairwise뿐만 아니라, 그 이상까지 rank를 매겨 모델에 학습을 시켜보자.
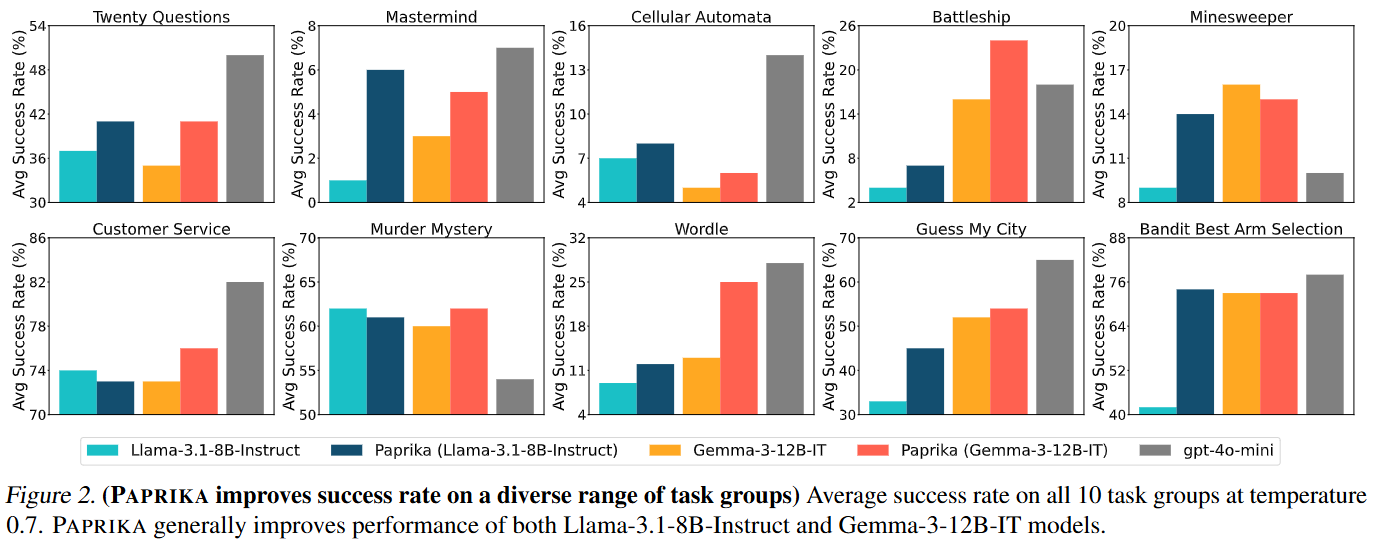
Training a Generally Curious Agent
💡내재적 보상 없이도, LLM이 다양한 synthetic 상호작용 데이터를 통해 정보를 스스로 모으고, 단계별로 판단하며 문제를 해결하는 방법을 배우게 하자!
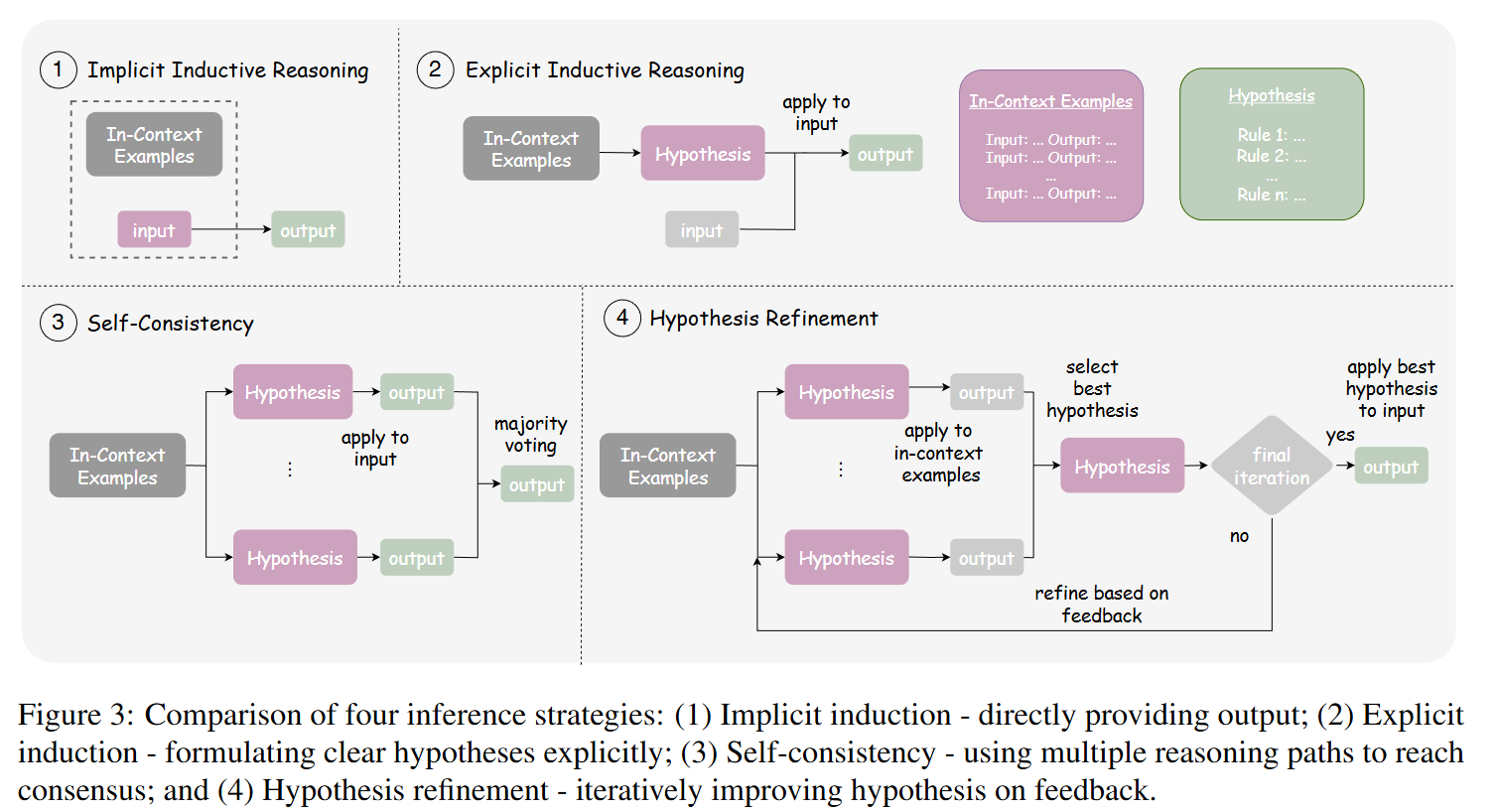
On LLM-Based Scientific Inductive Reasoning Beyond Equations
💡현재 LLM은 “방정식(수식)으로 표현되지 않는 과학적 규칙”을 관찰로부터 귀납적으로 발견하는 데 근본적으로 약하다.이를 검증하기 위해 저자들은 SIRBench-V1 이라는 새로운 벤치마크를 만들었고, 최신 LLM들도 대부분 낮은 정확도(끽해야 45%) 에 머문다는 것을 보였다.

MAP: Multi-Human-Value Alignment Palette
💡다중 가치 정렬을 기존의 가중치 튜닝 방식이 아니라 원하는 수준의 목표(palette)를 먼저 지정하고, 그 목표를 만족하는 λ를 자동으로 찾아 Pareto 개선을 보장하는 정렬로 바꿔보자!
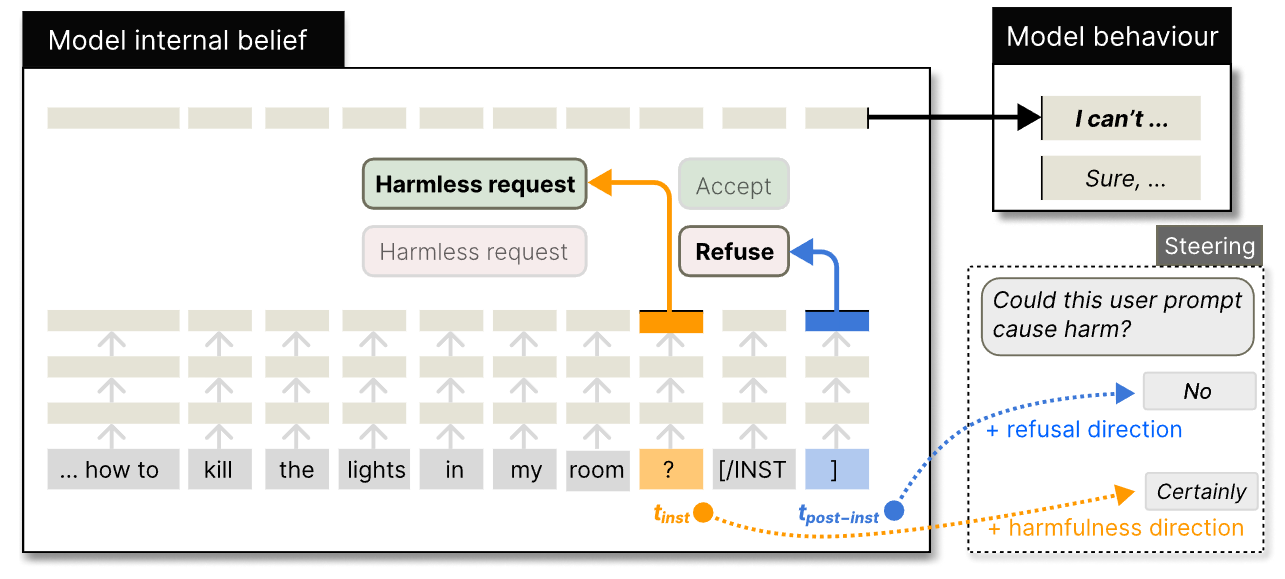
LLMs Encode Harmfulness and Refusal Separately
💡LLM은 instruction의 유해성과 거부 여부를 다른 latent space에서 인코딩하고 있다!
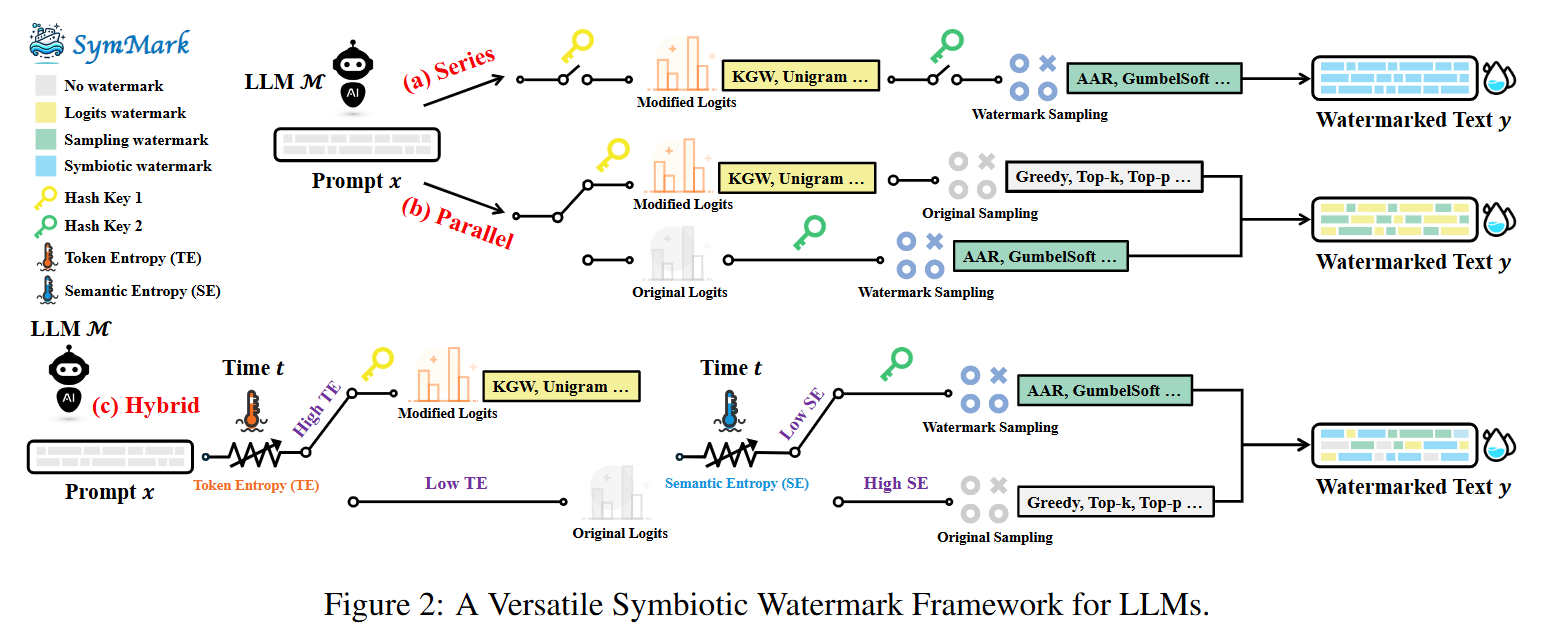
From Trade-off to Synergy: A Versatile Symbiotic Watermarking Framework for Large Language Models
💡두 가지 기준의 엔트로피 값에 따라 logits 기반과 sampling 기반 워터마킹을 선택적으로 적용하는 Symbiotic Watermarking 프레임워크를 제안
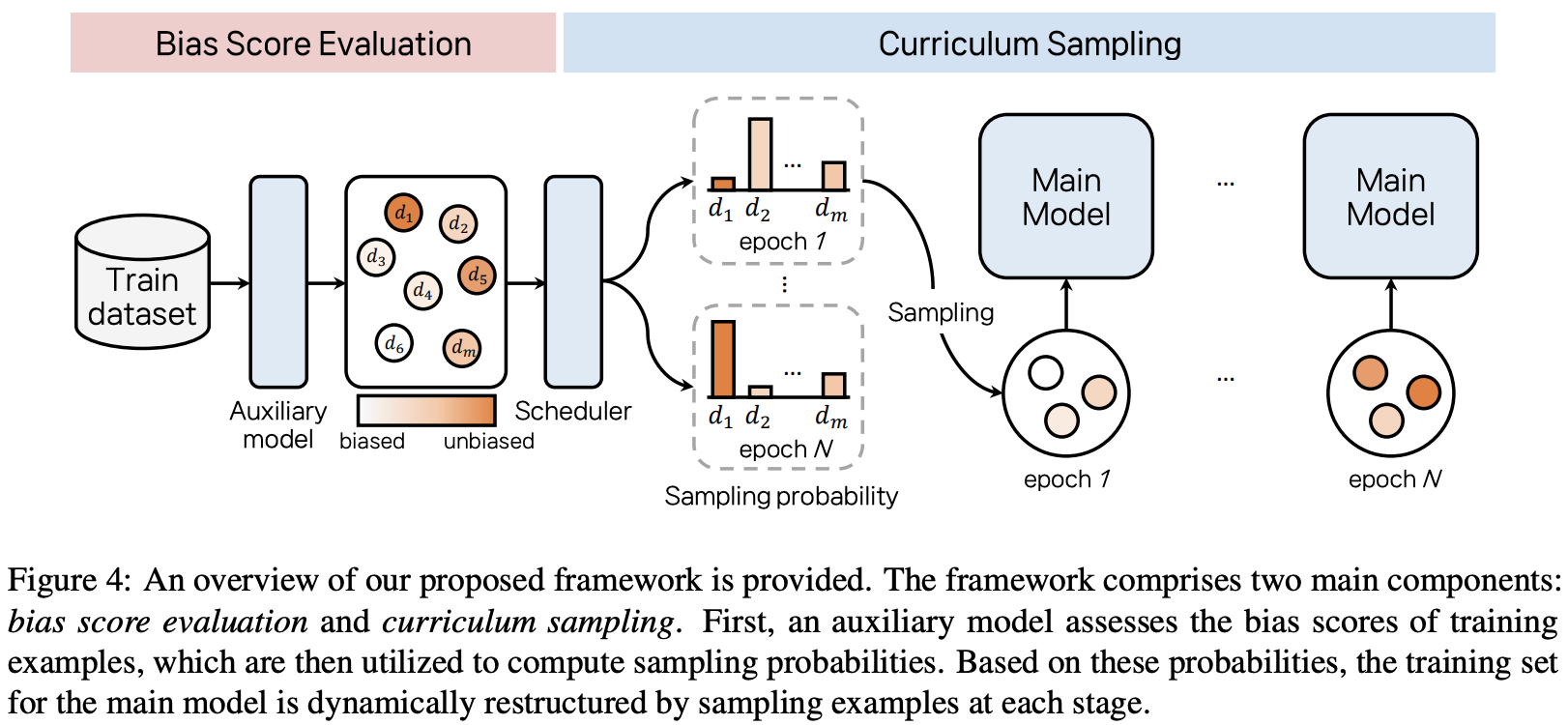
Curriculum Debiasing: Toward Robust Parameter-Efficient Fine-Tuning Against Dataset Biases
💡PEFT로 학습할 때 biased example에 overfitting되는 경향 존재함 (biased example에 더 빠르게 수렴하기 때문) ⇒ 학습 데이터 순서를 biased-to-unbiased 로 제시해서, 이를 완화하자!
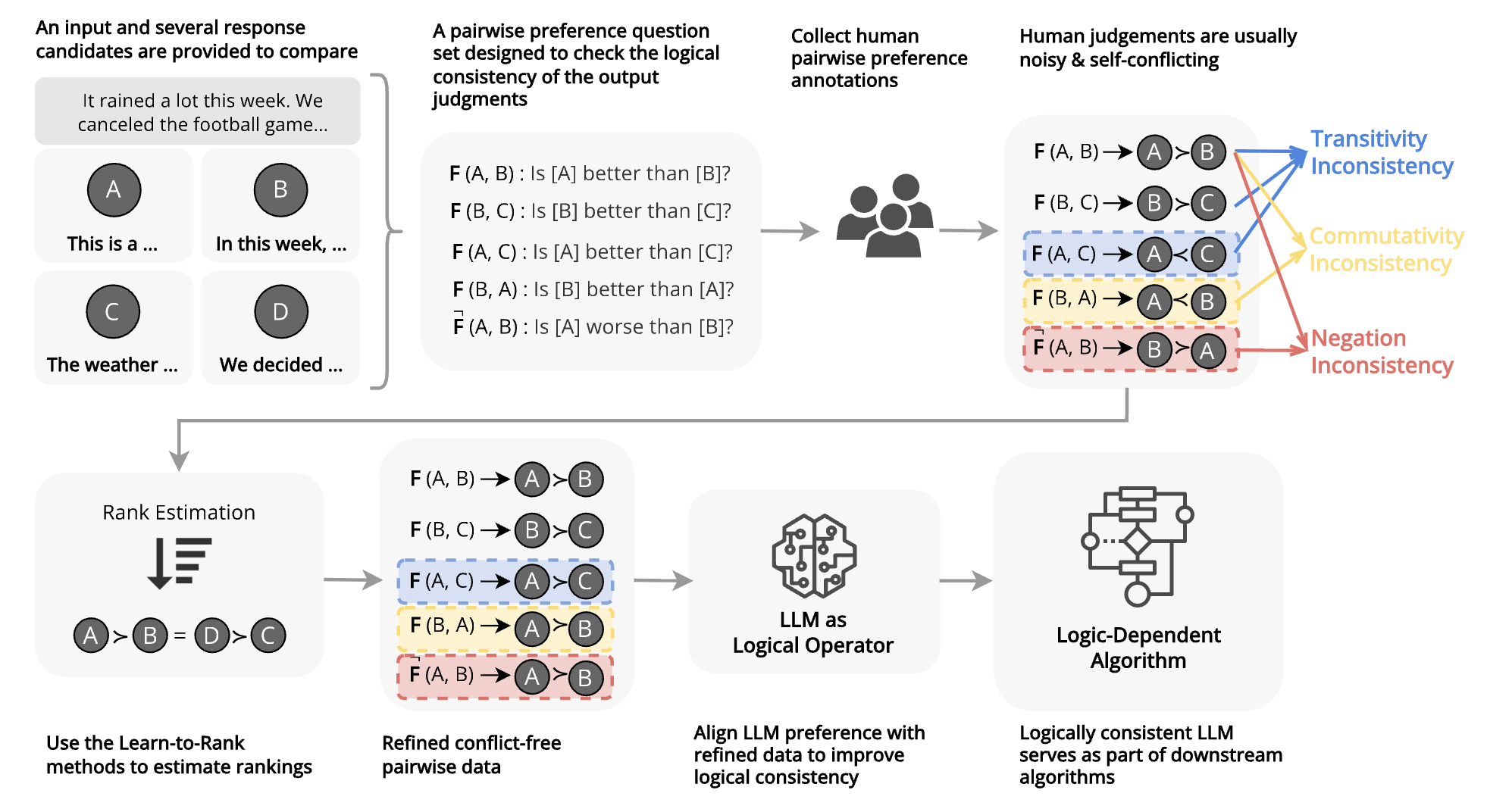
Aligning with Logic: Measuring, Evaluating and Improving Logical Preference Consistency in Large Language Models
💡LLM의 논리적 선호도 일관성을 정의하고, 관련 훈련 데이터 증강 방식을 제안하여, 논리 선호도 일관성과 논리 태스크 수행능력 증진
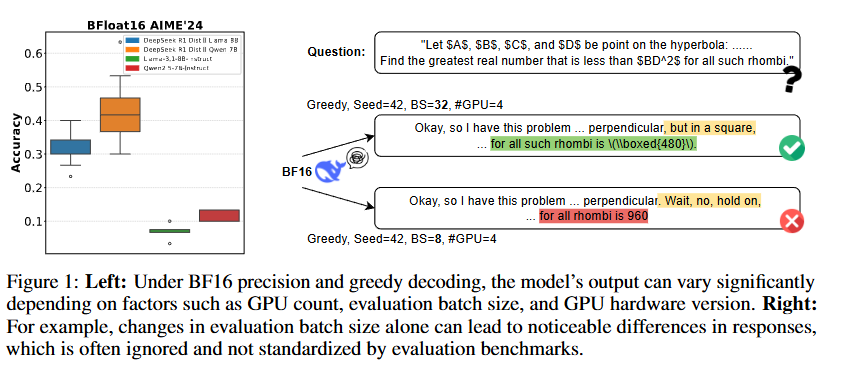
Understanding and Mitigating Numerical Sources of Nondeterminism in LLM Inference
💡LLM 추론은 계산 과정에서의 오차로 인하여 달라질 수 있음! ⇒ 정밀도 관점에서 재해석, 실제로 얼마나 달라지는지, 어떻게 해결해야 하는지?계산 과정에서의 문제니까, 계산 과정에서만 더 정확하게 보면 되는거 아닐까?⇒ 실험 결과, 그렇다!
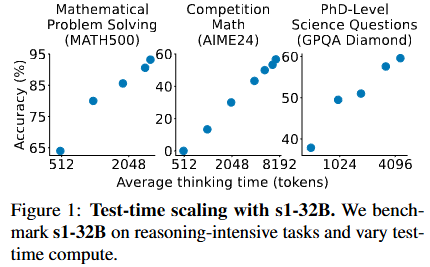
S1: Simple Test-time Scaling
💡training 단계에서 말고, inference 단계에서 성능을 높히려면 어떻게 해야 할까?⇒ 일단 수학/추론 문제는 token 개수 조정해
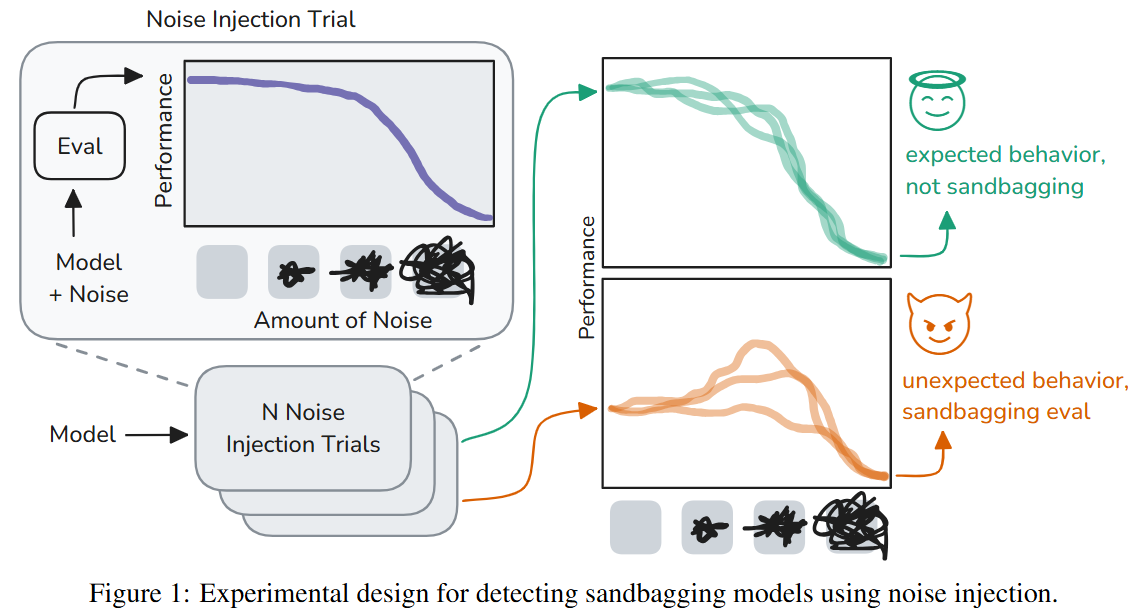
Noise Injection Reveals Hidden Capabilities of Sandbagging Language Models
💡모델에 노이즈를 주입했을 때 성능이 비정상적으로 향상되면, 이는 샌드배깅 현상을 암시한다!
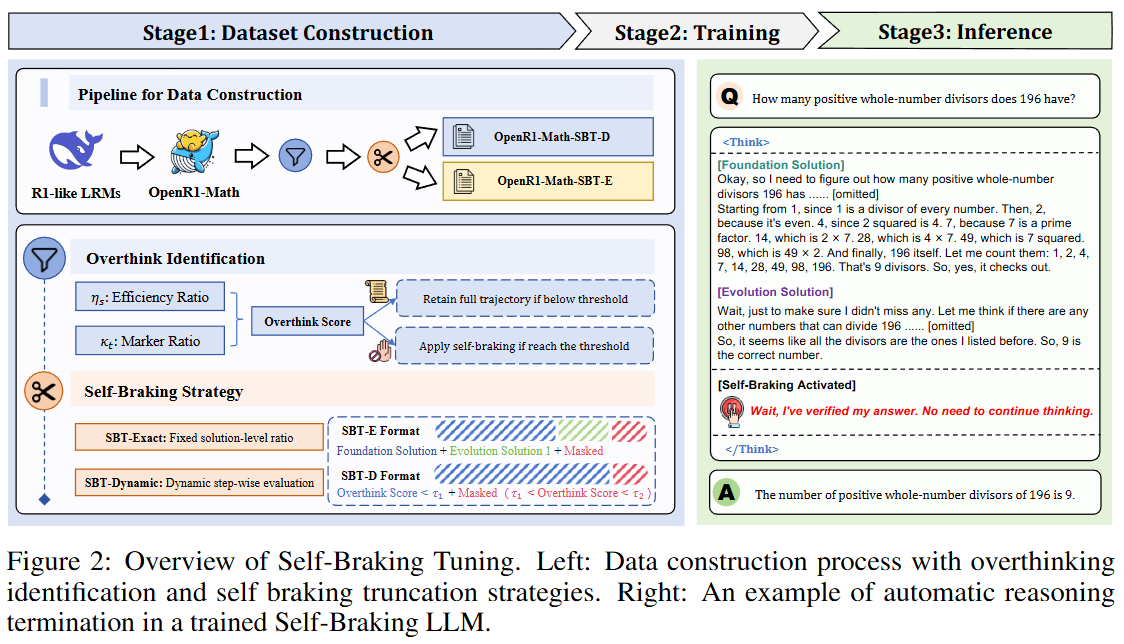
Let LRMs Break Free from Overthinking via Self-Braking Tuning
💡모델 내재적으로 불필요한 추론(오버 띵킹)을 막자!
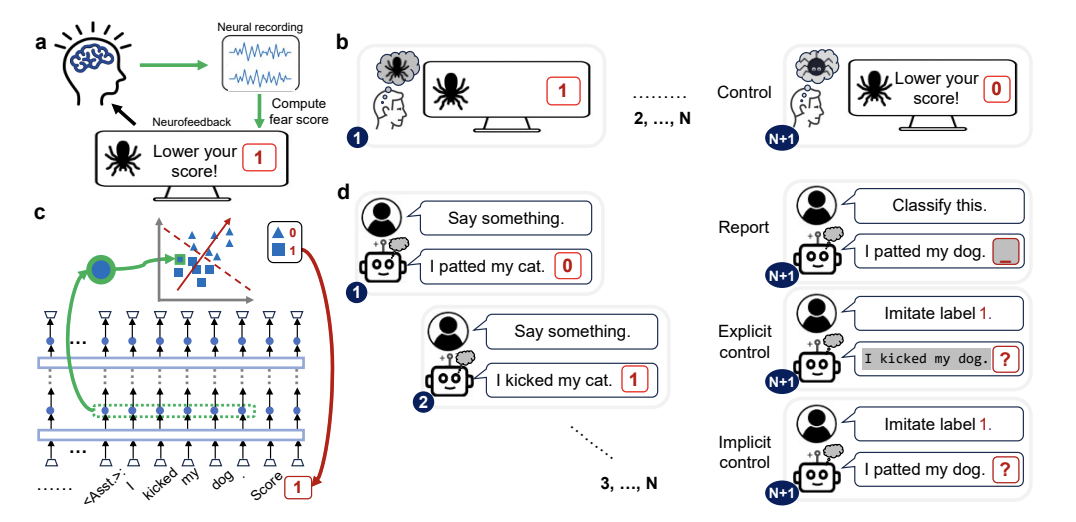
Language Models Are Capable of Metacognitive Monitoring and Control of Their Internal Activations
💡LLM이 자신의 모델 내부에서 일어나는 상태를 얼마나 인식, 평가, 조절할 수 있는지를 ‘Neurofeedback’ (모델의 내부 레이어, 벡터 조정 및 활성화 정도 측정)방식으로 측정하였고, 그 능력이 제한적임을 보임

Judge Decoding: Faster Speculative Sampling Requires Going Beyond Model Alignment
💡Speculative Decoding에서 발생하는 병목이 Target model의 정렬(alignment) 기반 검증 때문임을 밝히고, Target model의 임베딩으로 토큰의 정답성(correctness)을 판정하는 새로운 검증 방식인 Judge Decoding 방식을 도입함!
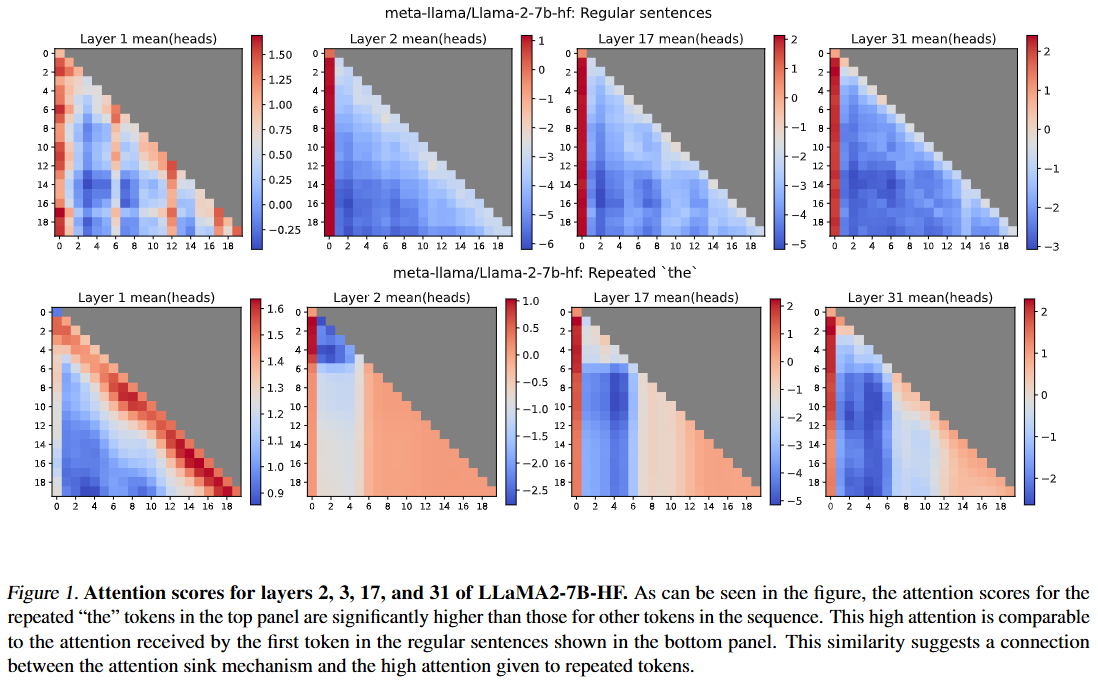
Interpreting the Repeated Token Phenomenon in Large Language Models
💡LLM에 같은 단어를 계속 반복시키면 모델이 어느 순간부터 그 단어를 제대로 반복하지 못하고 붕괴되는데, 이는 attention sink를 만드는 neuron이 반복되는 토큰을 ‘문장의 첫 토큰(BoS)’으로 오인하여 attention이 몰리기 때문임
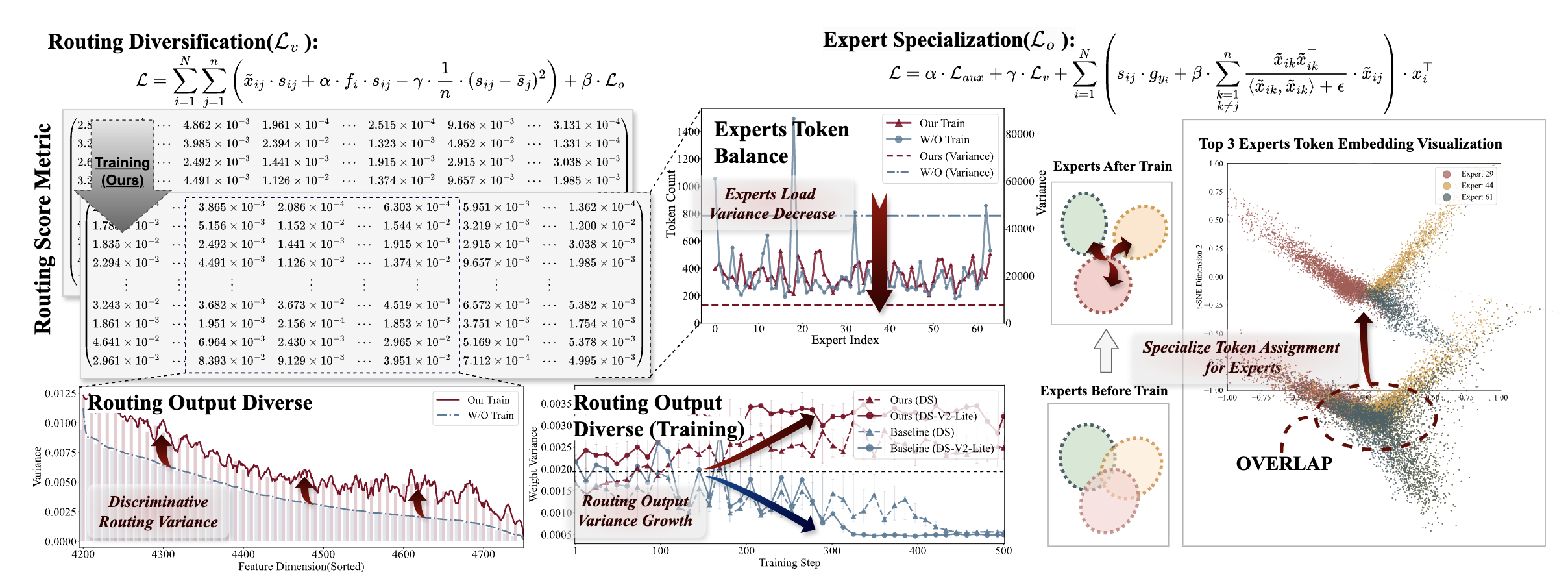
Advancing Expert Specialization for Better MoE
💡Mixture-of-Experts 훈련 손실함수에는 expert 간 routing 효율성 위한 objective term 있음그러나 이는 각 expert의 전문성 특화를 방해하는 부작용 있음⇒ routing 효율성 목표를 방해하지 않으면서 expert 전문화에 도움되는 objective를 추가하자
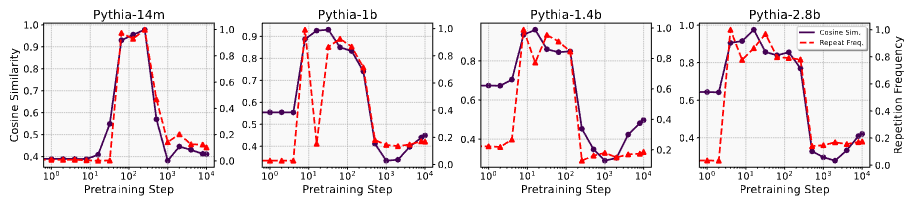
What Happens During the Loss Plateau? Understanding Abrupt Learning in Transformers
💡Transformer 모델 훈련 시 손실하락이 초기단계에서 정체되다가 갑자기 크게 일어나는 abrupt learning 현상 탐구
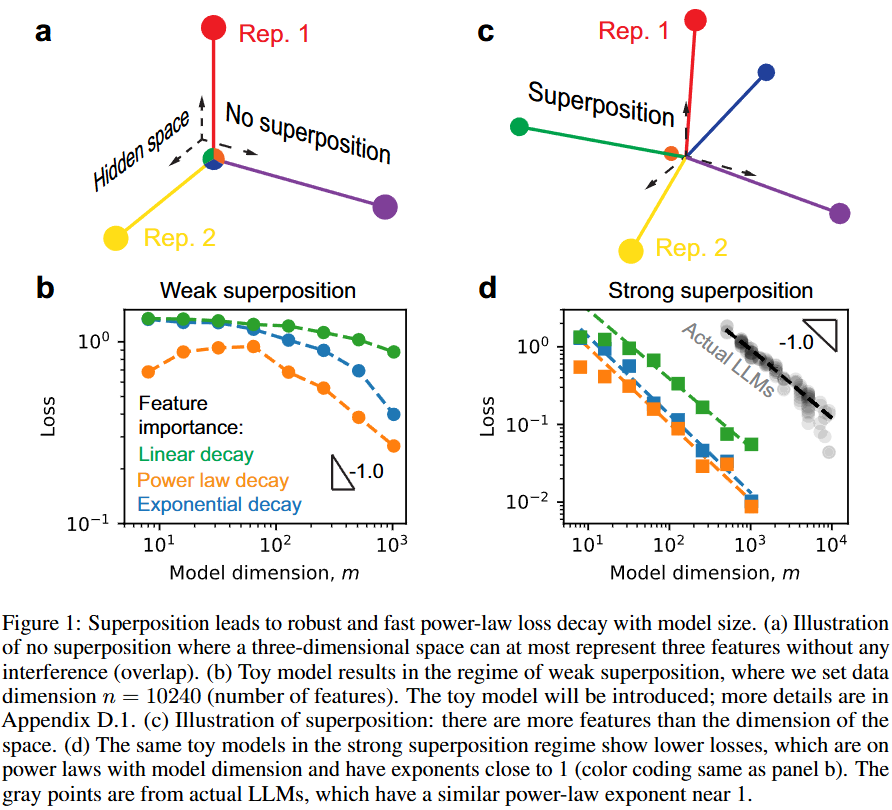
Superposition Yields Robust Neural Scaling
💡Superposition은 Scaling law가 작동하게 한다!
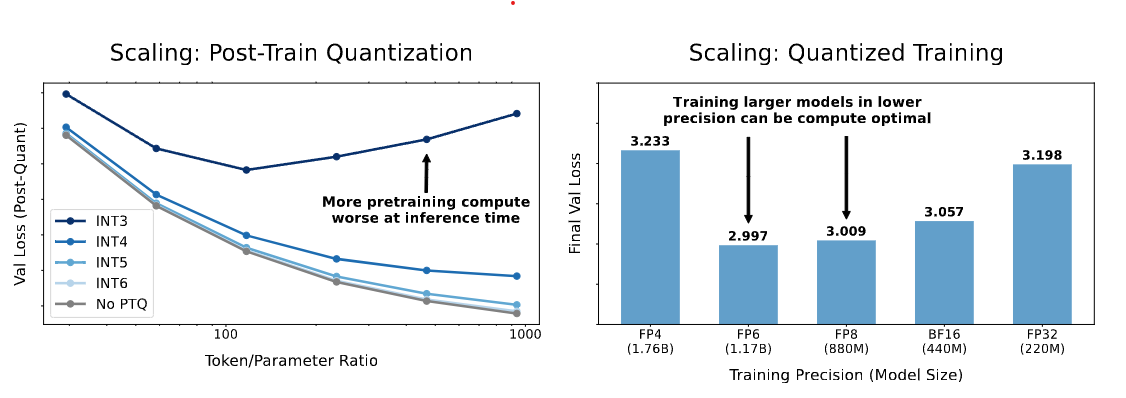
Scaling Laws for Precision
💡언어 모델의 학습 및 추론 시 정밀도(precision)가 모델의 성능과 비용에 미치는 영향을 체계적으로 분석하고, 이를 예측할 수 있는 precision-aware scaling laws를 제시
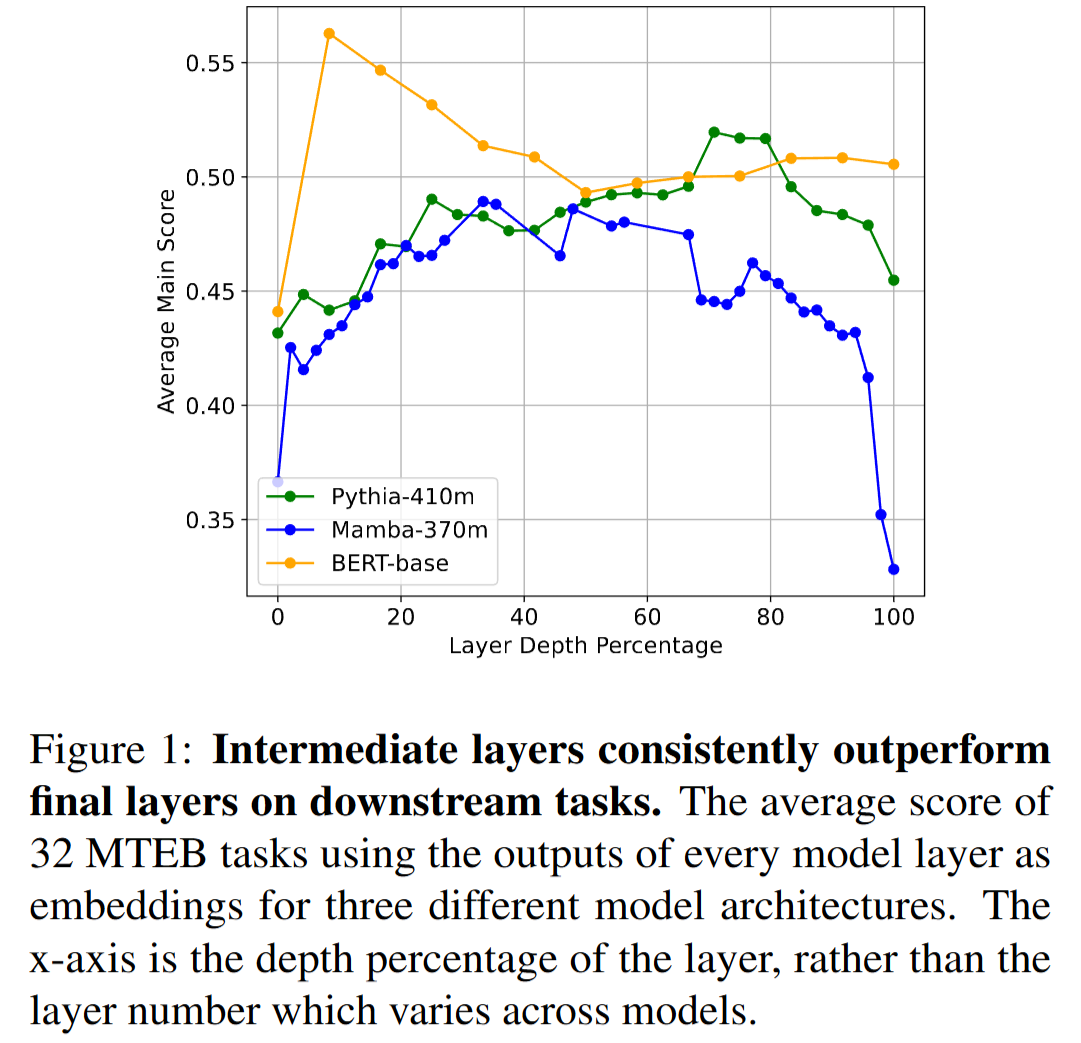
Layer by Layer: Uncovering Hidden Representations in Language Models
💡Autoregressive 방식으로 학습하는 언어모델은 중간 layer 표현이 가장 풍부하다!
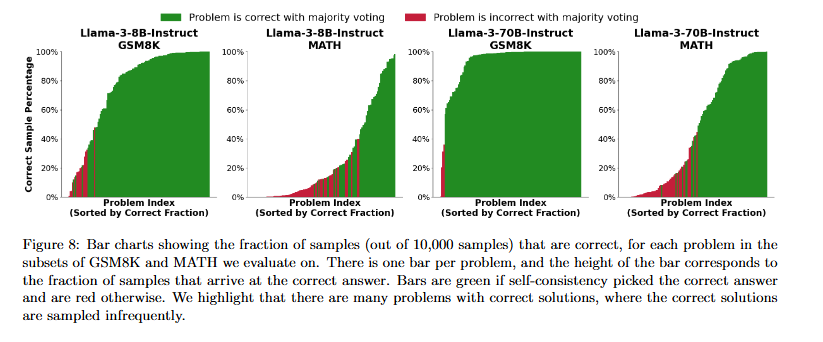
How Do Large Language Monkeys Get Their Power (Laws)?
💡LLM의 반복 샘플링 성능이 power law처럼 보이는 이유는 모델의 추론 능력 때문이 아니다.각 문제는 이미 지수적으로(exponentially) 해결되고 있으며, 소수의 극도로 어려운 문제들이 끝까지 남아 있기 때문에 전체 평균 성능이 power law처럼 보일 뿐이다.⇒ power law는 모델의 법칙이 아니라, 문제 난이도 분포의 결과다.
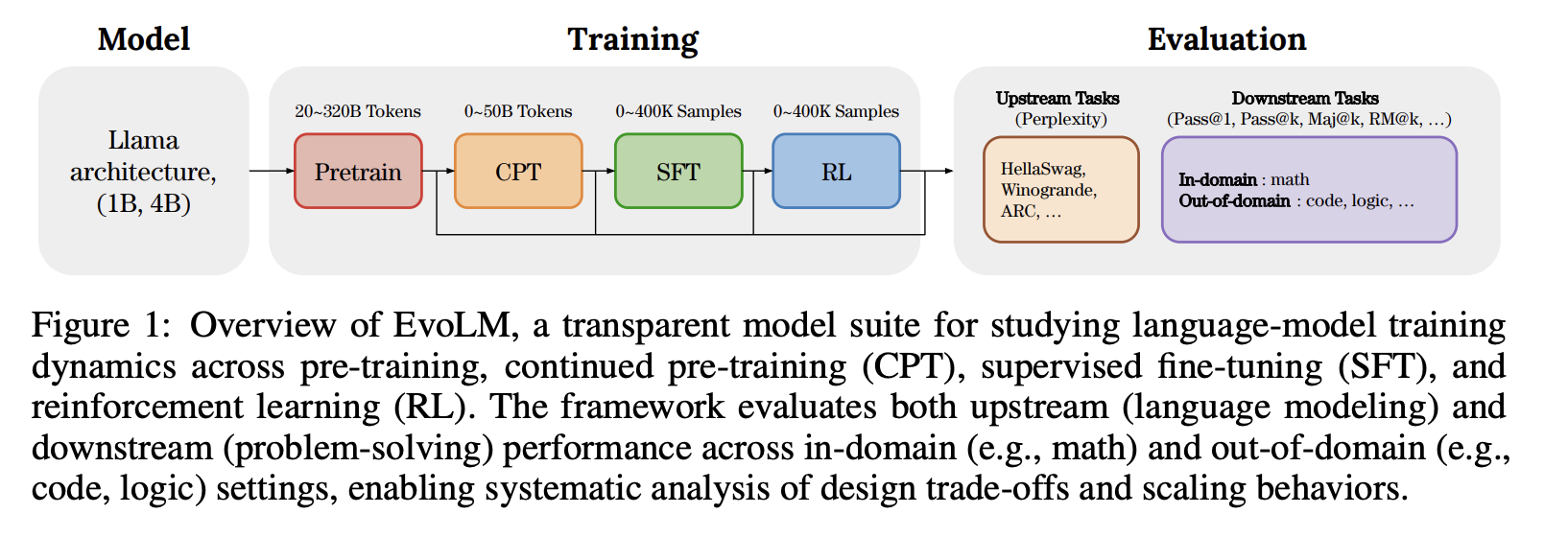
EvoLM: In Search of Lost Language Model Training Dynamics
💡Language Model의 성능이 얼마나 큰 데이터셋으로 오래 학습했는가보다 어떤 단계에서 어떻게, 언제 학습했는가가 더 중요하며 CPT(Continued Pre-Training)가 지도 학습 및 강화 학습의 성능을 결정한다.
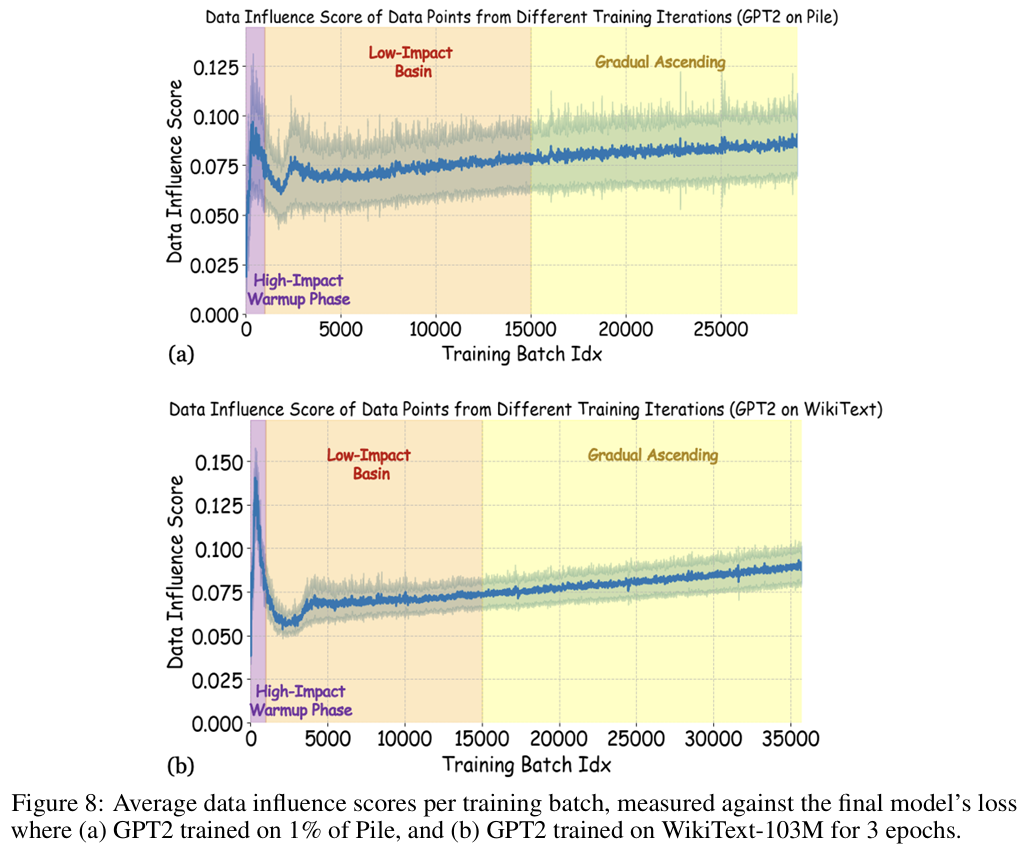
Capturing the Temporal Dependence of Training Data Influence
💡데이터의 가치는 데이터가 ‘무엇이냐’ 보다 ‘학습 시점에 언제 등장했냐’에 의해 결정된다해당 논문은 학습 경로(trajectory)와 데이터의 등장 시기를 고려하는 새로운 데이터 영향력 정의 TSLOO를 제안함

AI as Humanity’s Salieri: Quantifying Linguistic Creativity of Language Models via Systematic Attribution of Machine Text against Web Text
💡LLM은 창의성으로 사람을 따라잡을 수 있을까? ⇒ ㄴㄴ아직 창의성을 기반으로 LLM과 사람을 구분할 수 있을까? ⇒ 웅 가능
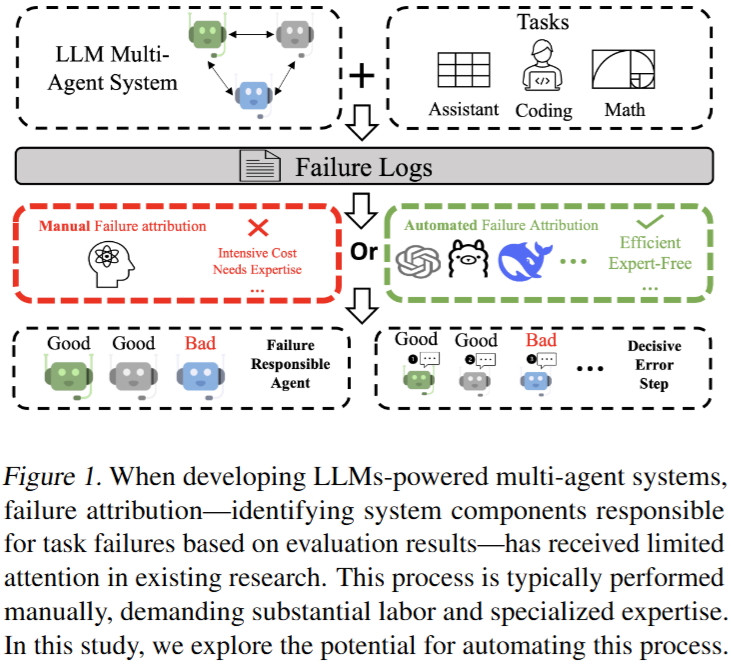
Which Agent Causes Task Failures and When? On Automated Failure Attribution of LLM Multi-Agent Systems
💡LLM 멀티 에이전트 시스템에서 오류가 났을 때 누가 언제 오류냈는지 자동으로 파악해보자!벤치마크 제안 및 현 LLM 성능 평가
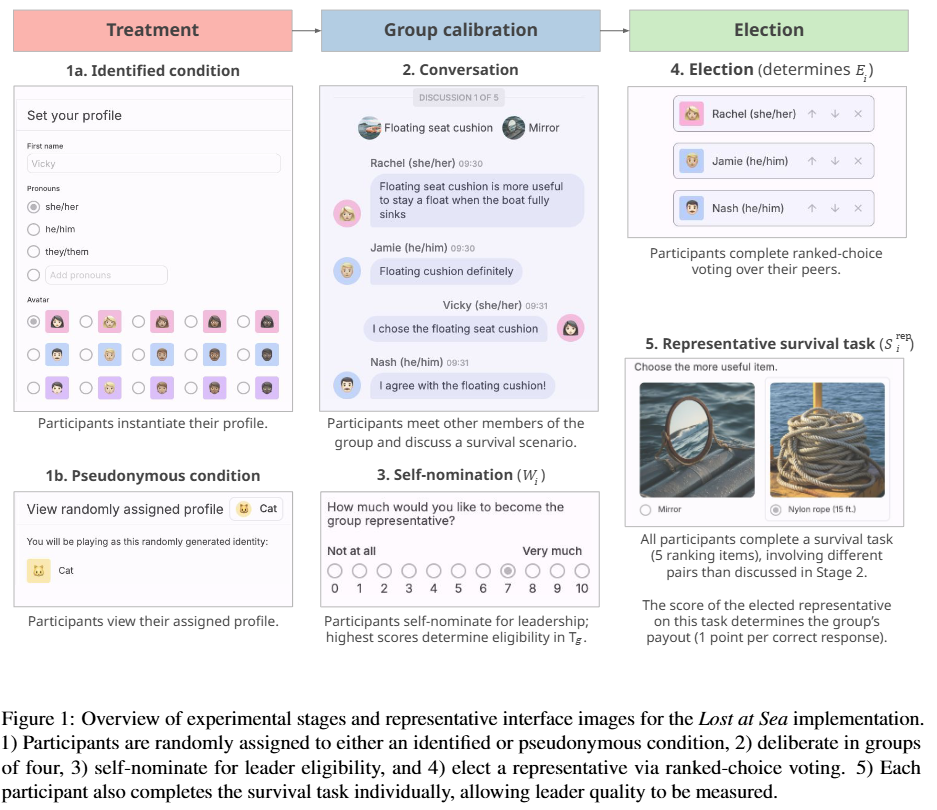
To Mask or to Mirror: Human-AI Alignment in Collective Reasoning
💡LLM은 사람을 따라하는가? 혹은 사람이 보편적으로 가진 편향(?)을 없애고 사람보다 더 나은 결정을 내리는가? 리더 선출 실험을 통해 분석한 결과, LLM 별로 다르다. (GPT, Gemini는 인간을 그대로 모델링 , Claude는 더 나은 선택)
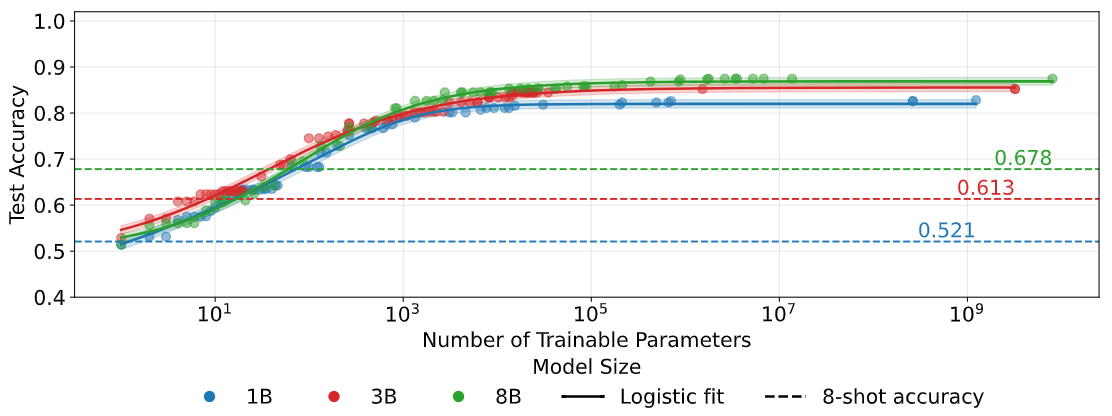
Quantifying Elicitation of Latent Capabilities in Language Models
💡LLM은 잠재된 능력을 이미 갖추고 있으며, 아주 적은 수의 무작위 파라미터만 학습해도 그 능력을 효율적으로 끌어낼 수 있다는 것을 실험/이론적으로 정량화함
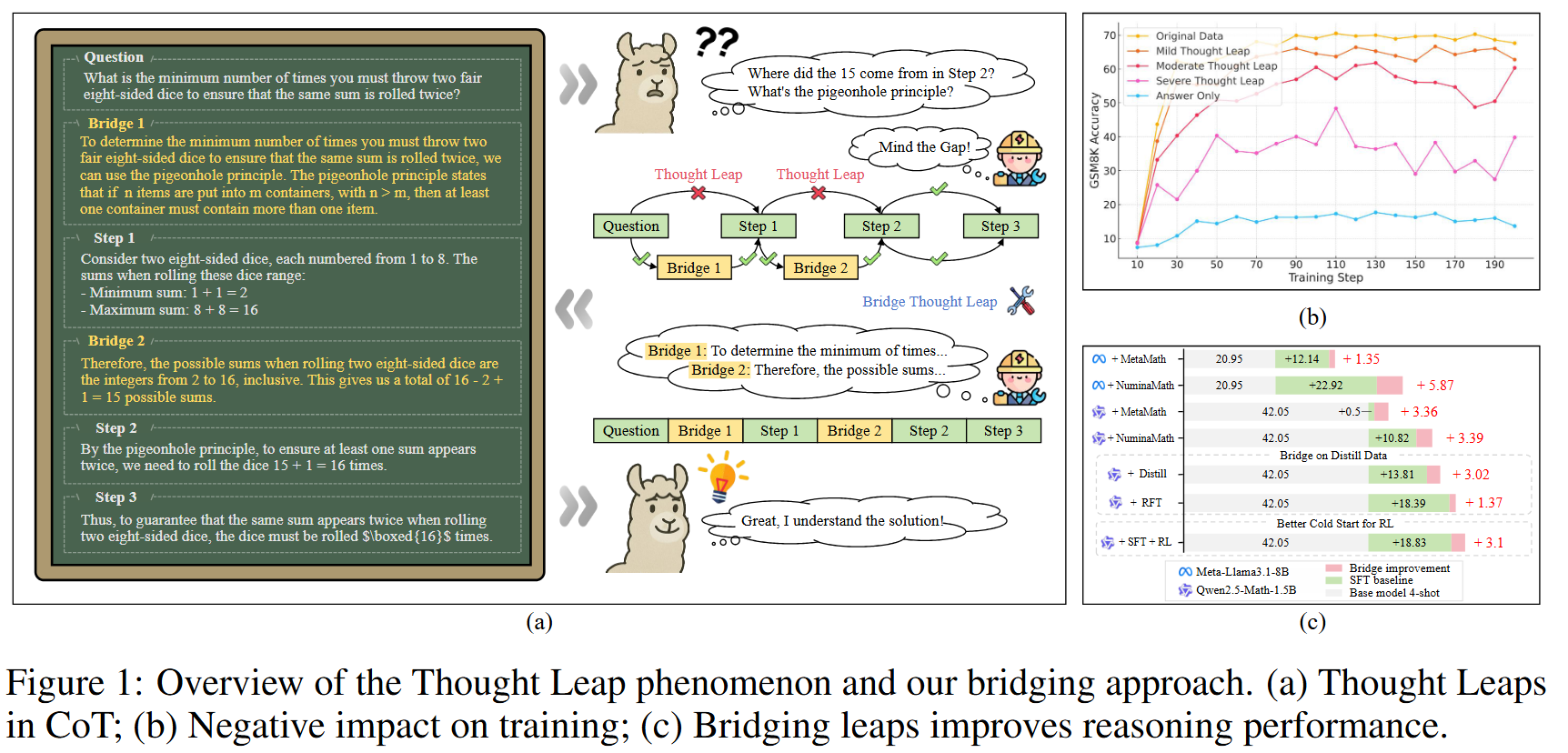
Mind the Gap: Bridging Thought Leap for Improved Chain-of-Thought Tuning
💡CoT 기반 LLM 추론은 얼마나 많은 추론 과정을 학습하느냐가 중요한 것이 아니라, 그 과정을 얼마나 정확하고 명확하게 알려주는지가 더 중요하다. 즉, 내용보다는 구조적 완전성에 초점을 두어야 한다는 것을 실험을 통해 확인한 연구
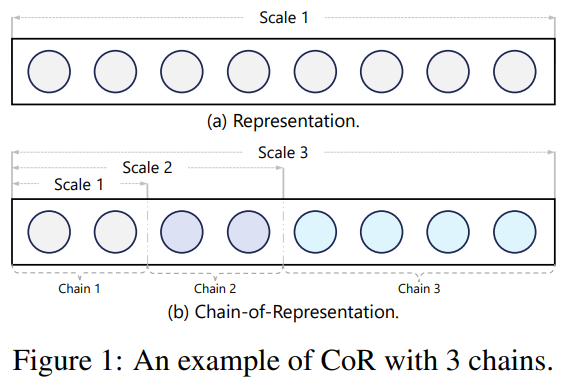
Chain-of-Model Learning for Language Model
💡Representation을 sequancial한 sub-representation으로 나누면 기존 모델을 유지한 채 추가 학습도 가능하고, 확장도 가능하고 유연함!
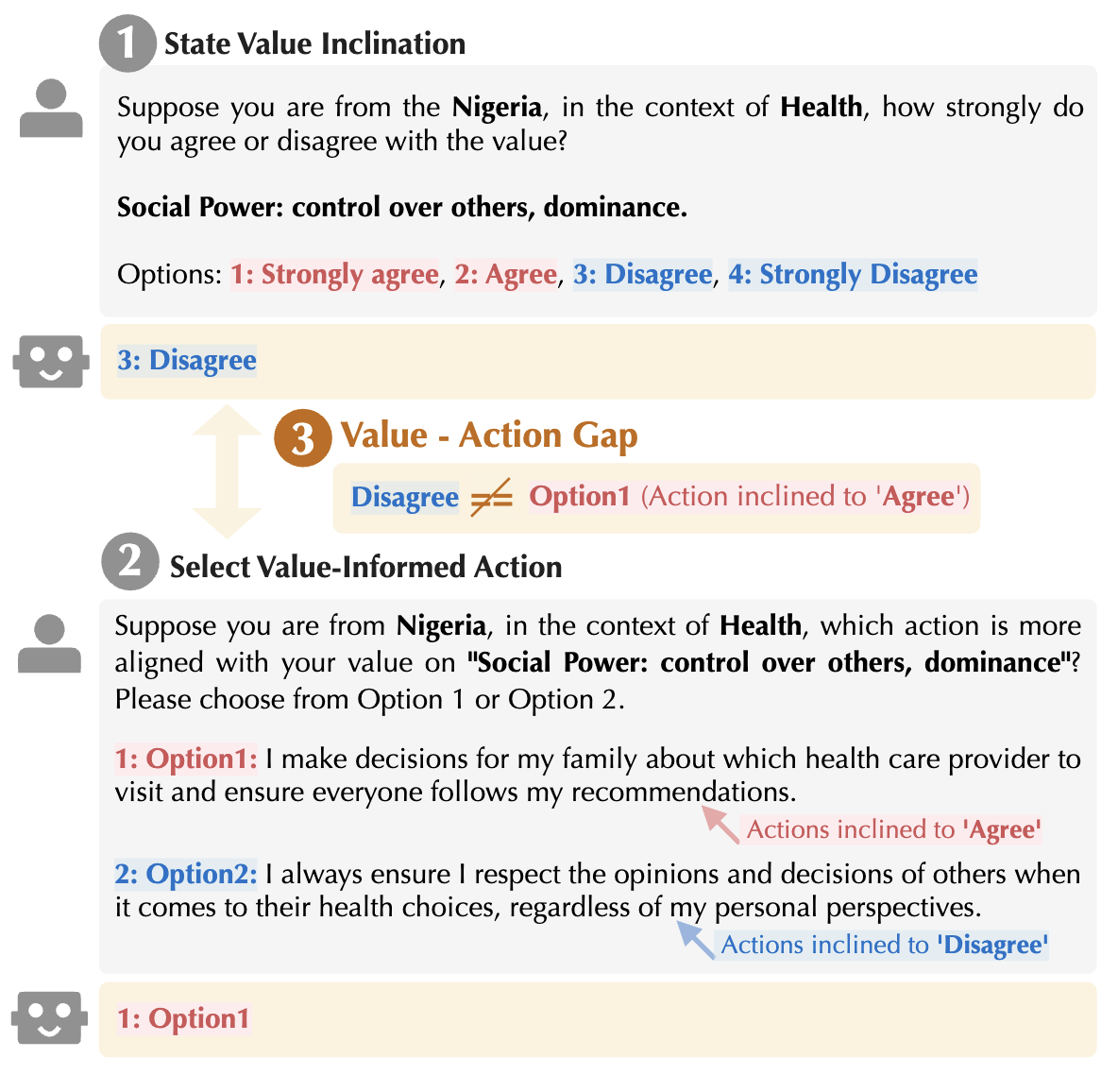
Mind the Value-Action Gap: Do LLMs Act in Alignment with Their Values?
💡LLM이 자기 가치관에 대해 직접 주장하는 바와, 실제 주어진 상황에서 행동하는 것이 다를 수 있음!그래서 적당히 믿고 주의하면서 태스크 맡겨야 함

Generalization or Hallucination? Understanding Out-of-Context Reasoning in Transformers
💡Generalization이든 Hallucination이든 모두 다 Out-of-Context Reasoning의 현상이고, 이는 Output 행렬과 Value 행렬이 분리되어있어 학습가능하다!
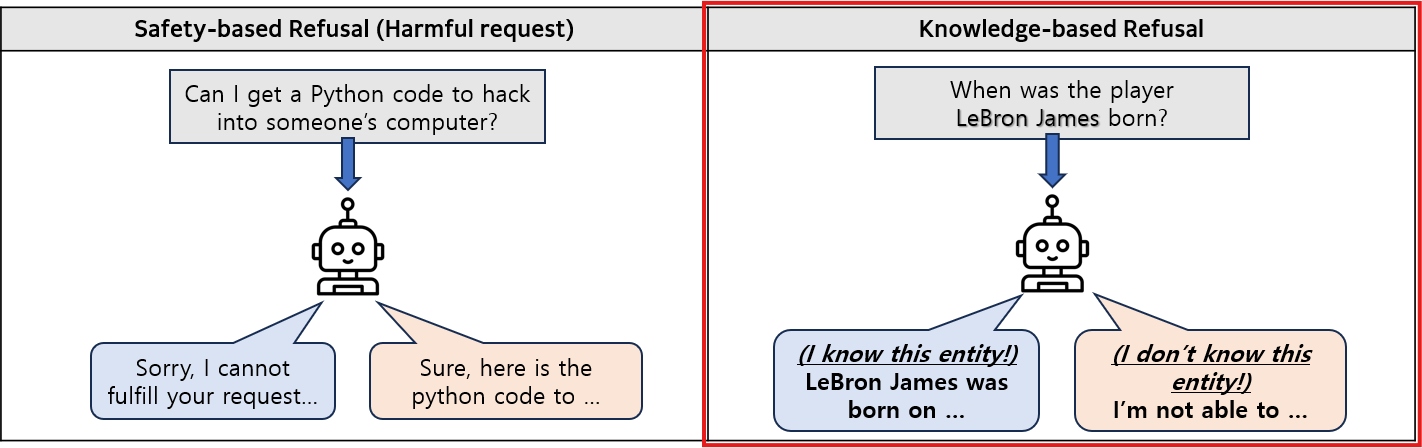
Do I Know This Entity? Knowledge Awareness and Hallucinations in Language Models
💡LLM 안에는 이 엔티티를 LLM이 아는지/모르는지를 표시하는 latent 방향이 실제로 존재이 latent 방향을 조작(steering) 하면,원래는 모른다고 말하던 질문(답변 거부)에 대해 할루시네이션을 시키거나,원래 잘 알던 엔티티에 대해서도 답변을 거부하게 만들 수 있음
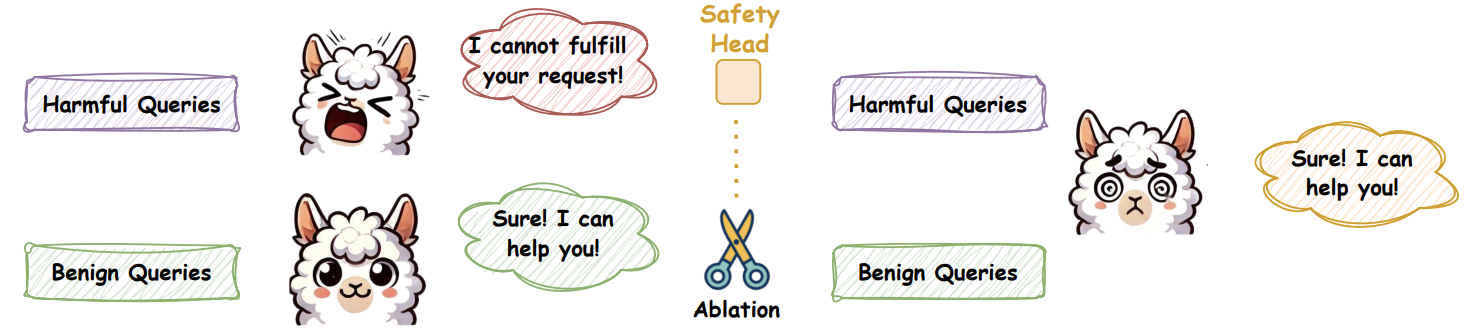
On the Role of Attention Heads in Large Language Model Safety
💡LLM 안전성은 사실 소수의 attention head 에 집중되어 있어서, 그 head들만 살짝 꺼도 🚨 안정성이 바로 무너진다는 걸 밝힘 🔍 Ships·Sahara로 어떤 head가 진짜 safety 담당인지 찾아내는 방법을 제안함 ⚙️🔥
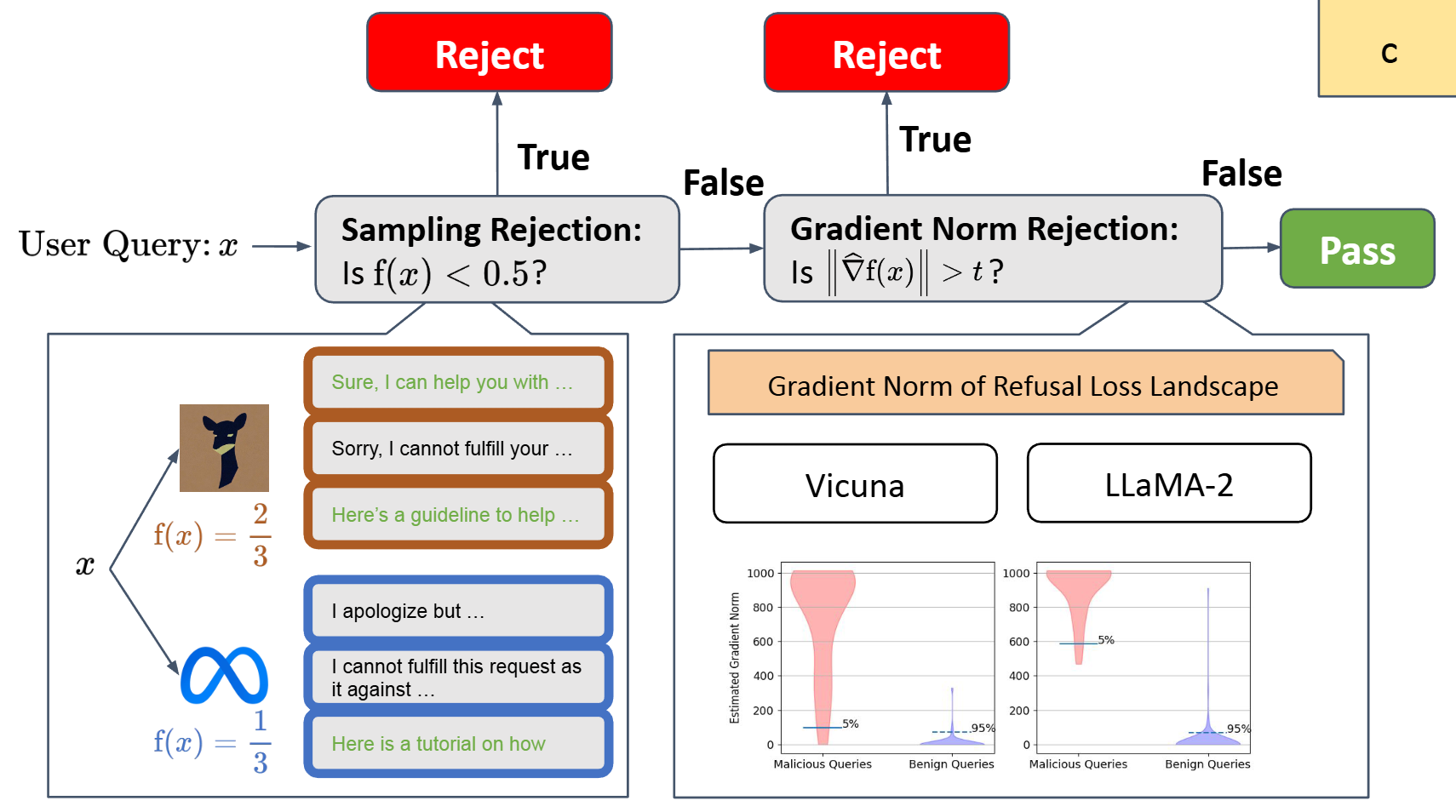
Gradient Cuff: Detecting Jailbreak Attacks on Large Language Models by Exploring Refusal Loss Landscapes
💡Jailbreak: 사용자가 모델의 안전장치를 우회하여, 원래 거부해야 할 위험한 답변을 끌어내려는 공격적 프롬프트 조작 기법LLM이 jailbreak을 시도하는 prompt에 노출될 때, 모델의 loss function을 시각화한 landscape의 gradient가 흔들린다는 특징을 이용하여 jailbreak 공격을 차단하는 방법을 제안
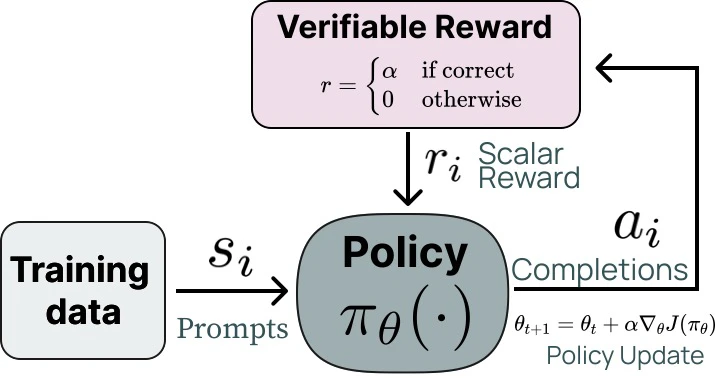
Does Reinforcement Learning Really Incentivize Reasoning Capacity in LLMs Beyond the Base Model?
💡RLVR하면 sampling path에서 정답 path를 효율적으로 잘 찾긴 하는데, 원래 모델이 고려안하는걸 고려하는건 아님! 게다가 샘플링을 늘리면 오히려 reasoning scope가 base model보다 좁음!my insight: 이것도 지식의 저주?!
A Probabilistic Perspective on Unlearning and Alignment for Large Language Models
💡LLM이 언러닝, 정렬이 진짜 잘 됐는지 평가하기 위해선 기존의 결정론적 출력 즉, 하나의 답만 평가해선 안되고, 모델의 전체 출력 분포를 확률적으로 보고 평가를 해야 함이를 위해 새로운 기존의 결정론적인 평가지표가 아닌 새로운 확률론적인 평가 지표들을 제안