Does Reinforcement Learning Really Incentivize Reasoning Capacity in LLMs Beyond the Base Model?
Review
| 닉네임 | 한줄평 | 별점 (0/5) |
|---|---|---|
| MNG | 직관적으로 생각했을 때, 강화학습은 하던 것 중에서 개선을 목표로 하는 일부를 더 잘하게 만드는 개념인 것 같음.(reward 설정에 따라서) 그런 측면에서, reasoning scope이 좁아지는 건 어쩔 수 없이 따라오는 게 아닐까? 하는 생각이 들었음. 오히려, 이걸 더 잘 활용하는 방향도 가능하지 않을까? | 4/5 |
| 방어냠냠 | LLM이 '현재 존재하는 대부분의 데이터'를 모두 학습했기 때문에 이미 world knowledge를 다 알고 있다고 생각함. 그렇기 때문에 당연히 'LLM이 가지고 있지 않은 추론 능력' 중에서 우리가 알고 있는 것은 없지 않을까? 즉, 기존 추론을 더 잘하게 하려는 방향으로만 RL이 되지 않을까? 한편으로는 "LLM이 가지고 있지 않은 추론 능력이 과연 진짜 필요할까?" 하는 생각도 들었다. 연구를 위한 연구 같음! | 3.8 |
| 오차즈케 | RL은 결국 '보상을 더 잘 받는 행동 방식'을 학습하는 단계이고, 모델의 근본적인 reasoning 능력은 대부분 pretraining에서 이미 결정되는 것 같음. 따라서 RL이나 SFT는 새로운 능력을 만드는 것이 아니라, 기존 능력을 어떻게 더 효율적이고 선호되는 방식으로 표현할지를 조정하는 역할에 가깝다고 느껴진다. | 4 |
| 야키토리 | RL reasoning은 뇌로 치면 이미 정해져 있는 뇌의 용량? 능력치?을 키우기 보단 뇌의 능력을 최대한 잘 활용하도록 돕는 역할(영화 루시 느낌)인 것 같다. 결론은 RL도 중요하고 모델 자체도 중요하다고 느꼈음 | 4 |
| 42REN | 특정 Task에 대한 정답과 보상을 제시하는 것이 결국 RLVR이 되는데, Reasoning Scope는 좁아질 수밖에 없다는 생각임. 그러나, 이걸 base model에서 꺼내쓴다는 문제 제기를 통해 기존 모델을 제대로 Training하는 방법을 찾아볼 수 있는 계기가 될 수는 있다고 봄. | 4.2 |
| 텀블러 | 어느정도 예상가능한 시나리오긴 한데, 결국 적은 k 샘플링에서 잘찾는게 RL의 목적 아닌가? 물론 고전적인 RL을 기대하는 것이라면 새로운 아이디어가 나오는게 좋지만, 지금 LLM에게 먹이는 RL은 더 잘하도록 지도하는 거라서,,, 지금은 RLVR이 제 역할을 그대로 순수하게 잘 이행하고 있다고 생각함! 인사이트는 좋음!! | 3.5 |
| 감자 | RL이 모델의 추론능력을 강화한다고 하는데, 논문 실험결과를 봐서는 새로 배우게 한다기보다 이미 아는 걸 더 잘하게 하는 느낌. LLM에게 아예 새로운 분야라면, 처음부터 RL하는 게 꼭 좋은 선택은 아니겠다 싶다 | 4 |
| 새우 | RL이 LLM의 ‘능력치’를 늘리기보다, 이미 학습된 world knowledge 안에서 reward를 잘 받을 수 있는 추론 패턴만 강화한다는 점을 논리적으로 잘 푼 논문인듯 | 4.1 |
TL; DR
💡
RLVR하면 sampling path에서 정답 path를 효율적으로 잘 찾긴 하는데, 원래 모델이 고려안하는걸 고려하는건 아님! 게다가 샘플링을 늘리면 오히려 reasoning scope가 base model보다 좁음!
my insight: 이것도 지식의 저주?!
Summary
Background & Motivation
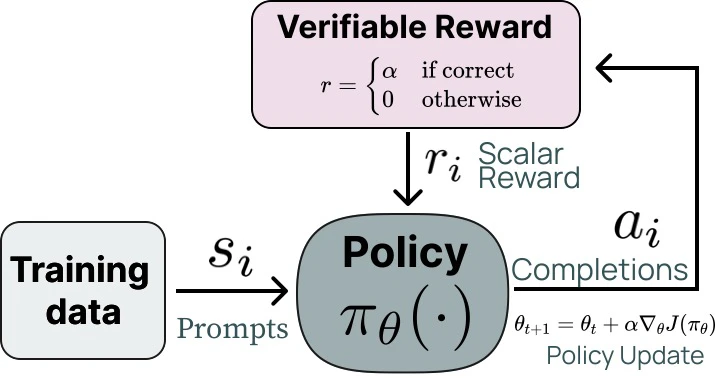
RLVR(Reinforce Learning with Verifiable Rewards)
- LLM의 next token prediction을 강화학습에서의 policy로 생각해보자!
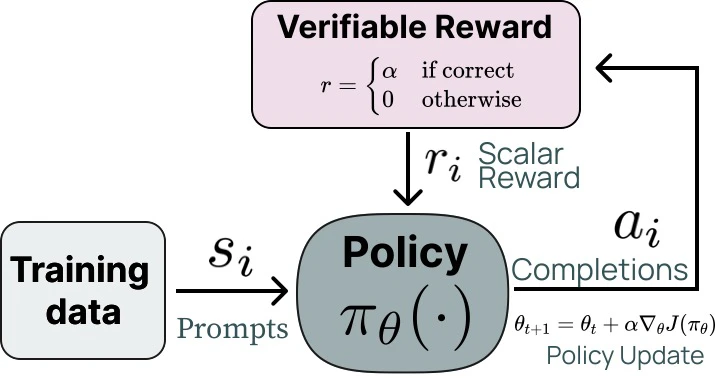
- 정답을 생성하면 reward를 주는 방식
- RLVR 알고리즘들은 PPO의 objective를 사용함
여기서 clip은 너무 과한 업데이트를 막는 threshold라고 보면 됨
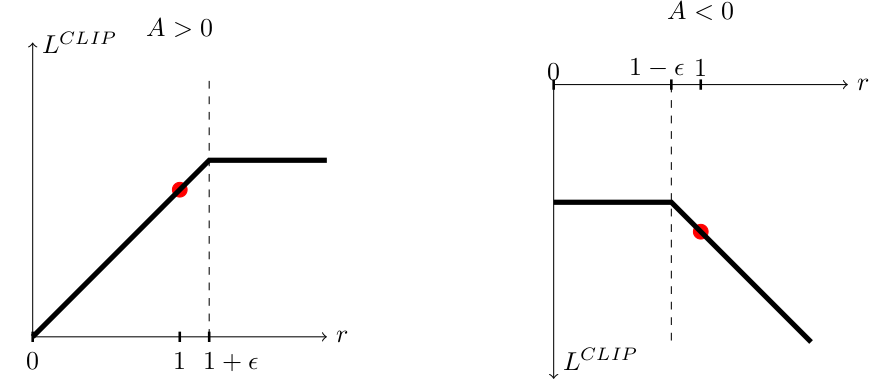
- 는 advantage로 평균적인 action보다 얼마나 더 좋은 action(생성)이었는지 곱해주는 것
- 문제의 난이도가 높았을때 맞추면 아주 굿굿!
- LLM의 next token prediction을 강화학습에서의 policy로 생각해보자!
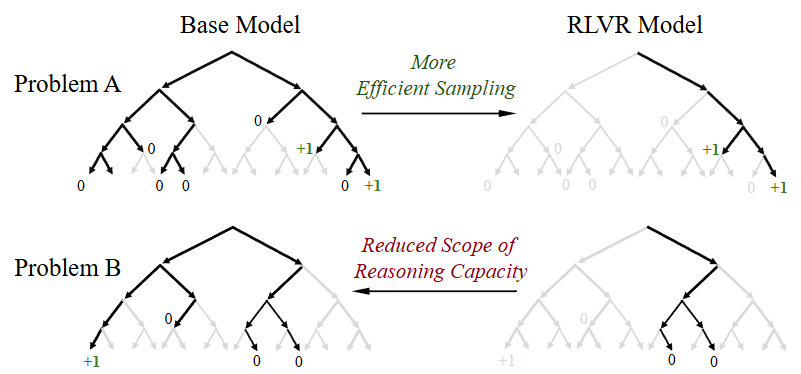
- 전통적인 강화학습은 새로운 전략, 아이디어들을 만들어내는데 (e.g. AlphaGo’s move 37),
LLM을 위한 RLVR도 LLM이 가지고 있지 않은 추론 능력을 새로 만들어 내는걸까?, 아니면 기존 추론을 더 잘 하는 것 뿐일까?
- → base model과 RLVR model이 어떤 문제를 잠재적으로 해결할 수 있는지에 대해 reasoning capacity boundary를 측정해보자!
- 매우 충분한 sampling속에서 정답을 생성할 수 있는지 측정, 평가!
Key Findings
- 현재의 RLVR 모델들의 추론 범위는 base model보다 작다
- RLVR 모델이 생성하는 reasoning path들은 base model들에 이미 존재한다
- RLVR 알고리즘들의 성능들은 다 비슷한데, optimal이랑은 거리가 멀다
- RLVR과 distillation은 근본적으로 다르다
Experiments
Experimental setup
- 수학 task는 SFT 없는 모델들 쓰고, 나머지 task는 SFT된 모델 씀
- Start model에 RL을 적용한 후 전후 비교!
- Deep analysis는 4장의 심층 분석에서의 세팅임! main result는 아님

| Task | Start Model | RL Framework | RL Algorithm(s) | Benchmarks |
|---|---|---|---|---|
| Mathematics | LLaMA-3.1–8B / Qwen2.5–7B/14B/32B Base / Qwen2.5-Math-7B | SimpleRLZoo, Oat-Zero, DAPO | GRPO | GSM8K, MATH500, Minerva, Olympiad, AIME24, AMC23 |
| Code Generation | Qwen2.5–7B-Instruct / DeepSeek-R1-Distill-Qwen-14B | Code-R1 / DeepCoder | GRPO | LiveCodeBench, HumanEval+, MBPP+ |
| Visual Reasoning | Qwen2.5-VL-7B | EasyR1 | GRPO | MathVista, MathVision |
| Deep Analysis | Qwen2.5–7B Base & Instruct / R1-Distill-Qwen–7B | VeRL | PPO, GRPO, Reinforce++, RLOO, ReMax, DAPO | Omni-Math-Rule, MATH500 |
Evaluation protocol
- Metric: pass@k를 사용
- 기존 샘플링 방식들은 평균적인 행동만 평가하고, 충분히 시도했을 때 풀 수 있는지는 고려 안함
- 모델로부터 k개 출력 샘플링하고, 하나라도 맞으면 pass@k = 1, 다 틀리면 pass@k = 0
- → 모델이 k번 시도 안으로 풀 수 있는 문제인가? 를 알 수 있음
- 벤치마크 전체로 보면 평균 pass@k는 모델이 k번 시도했을 때 풀 수 있는 문제의 비율
→ Reasoning coverage
- 수학에서는 k번 시도하면서 숫자 찍어서 맞출 수 있어서 CoT를 수동으로 검사했다고 함
샘플링 설정
- Temperature = 0.6
- Top-p = 0.95
- max token generation length = 16,384 tokens
Evaluation Results
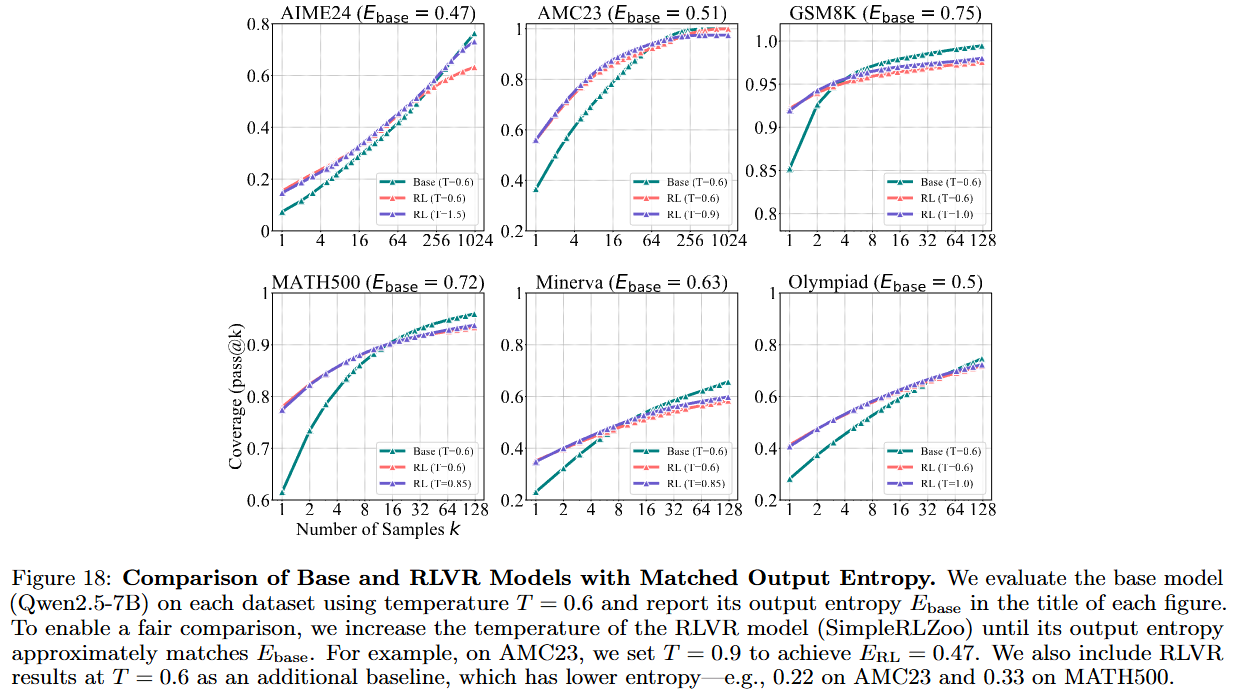
수학 task
- k가 작으면 RLVR한 모델이 더 잘하는데, k 높아지면 coverage가 역전됨!
- RLVR이 새로운 추론 패턴을 학습시킨 것이 아니라, 모델이 이미 가지고 있던 패턴을 더 자주 꺼내 쓰도록 분포를 조정한 것!
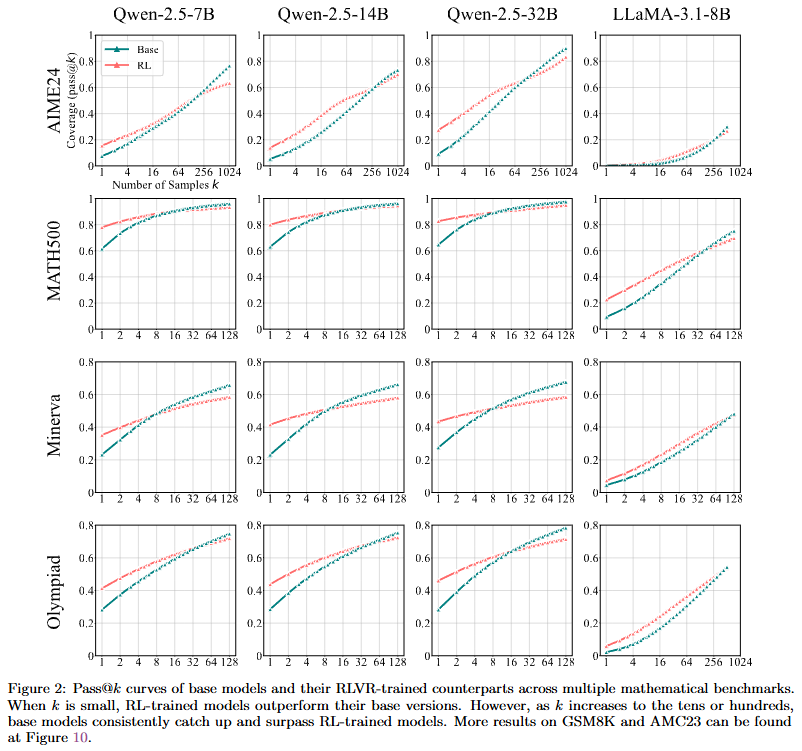
이미 잘하는 base model 예시 (figure20, 21)
- base 주제에 이정도 길이와 퀄리티의 추론을..?


코드 생성, visual reasoning task
- 역시 낮은 k에서는 RLVR 모델이 우수하나, k가 많아지면 base모델의 coverage가 넓어짐
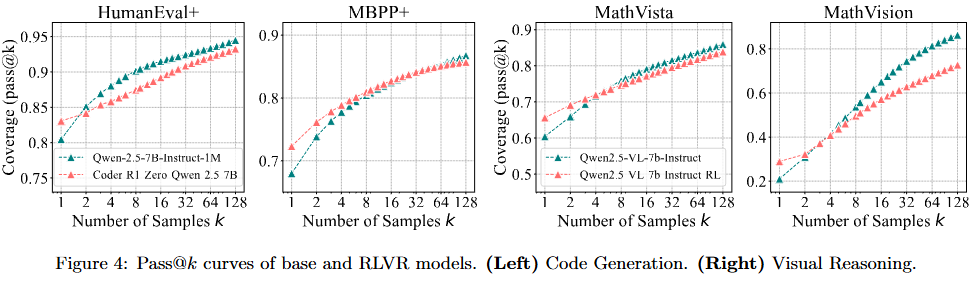
Deep analysis
- 왜 base model의 coverage가 역전할까? 왜 RLVR은 새로운 path를 확장하지 못할까?
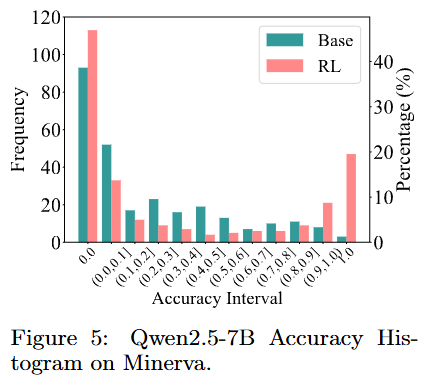
Accuracy distribution analysis
- RLVR 모델이 생성한 것이 전체적으로 accuracy가 높음
- 근데 이상하게도 accuracy 0인것도 RL 모델이 더 높음
Perplexity analysis
- RL이 생성한 추론의 perplexity가 basemodel에서 낮음
- Base model도 할 수 있는, 알고 있는 추론 경로였던 것!
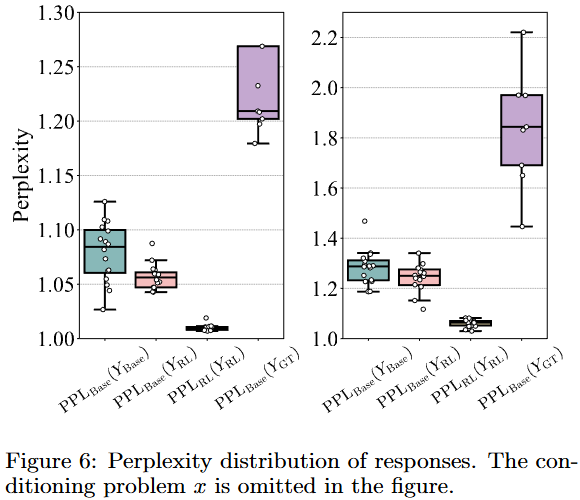
- RL이 생성한 추론의 perplexity가 basemodel에서 낮음
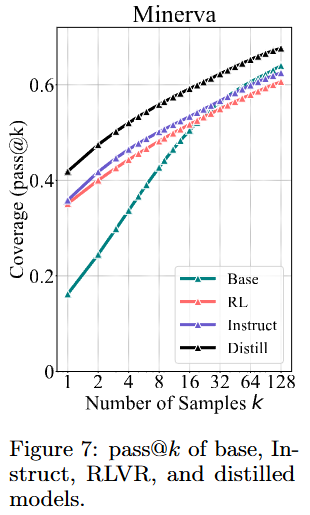
Distillation은 다르다!
- DeepSeek에서 distill받은 DeepSeek-R1-Distill-Qwen-7B과 Qwen2.5-Math-7B(base), Qwen2.5-Math-7B-Oat-Zero(RL)를 비교
- K를 늘려도 coverage가 제일 높음 → 선생님한테 배우면 모르는 것도 알게 된다!
다양한 RL algorithm 실험
- 다른 algorithm을 써도, step을 더 깊게 학습시켜도, 결국 양상이 비슷해짐
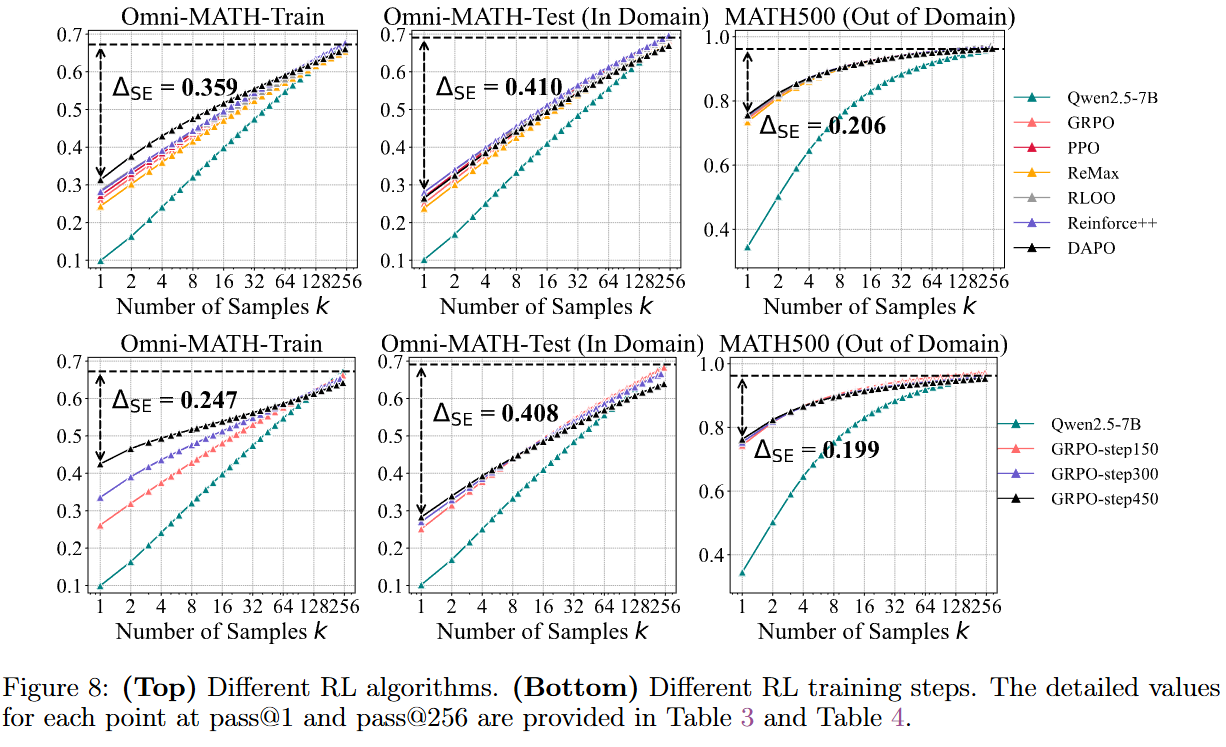
RL이 문제인거야? RL 안에서 어떻게 해결 못해?
- Training step 늘려도 안됨
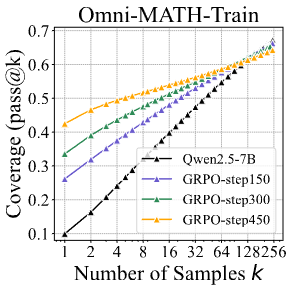
- 훈련할 때 샘플링 늘려도 안됨
- base model에서 멀어지지 않게 KL loss 넣어도 안됨
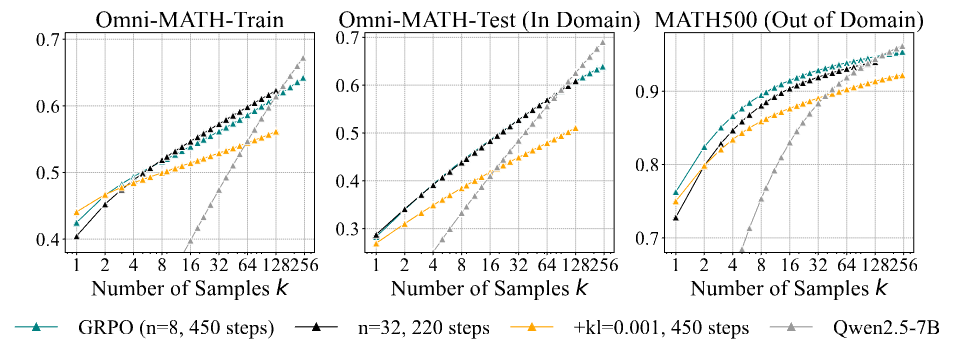
- 보니까 RL 모델은 training할수록 엔트로피 낮아지네, temperature를 높여보자! → 안됨