Chain-of-Model Learning for Language Model
Review
| 닉네임 | 한줄평 | 별점 (0/5) |
|---|---|---|
| 월드콘 | Motivation과 방법론이 좋은 인사이트를 준 것 같다. 효율성 측면은 추론 시간 / 호출 숫자 뿐만 아니라 파라미터에도 적용이 될 것 같은데, 큰 모델이 파라미터 일부만을 쓸 수 있다면 효율적임. | 4 |
| 파비아노카루아나 | 실험결과는 별론데, 아이디어는 정말 뛰어나다. 기존 모델을 잘 재활용하는 방법을 모델링하고, 실제로 적용하는 과정은 정말 논리적이다. | 5 |
| 키보드 | 너무 신기하다 이걸 어떻게 생각하지? 모델 구조 바꿔버리는 연구는 정말 신기하다. 그런데 생각보다 실험 성능이 향상되진 않아서 아쉽지만, 파라미터를 밑바닥부터 재학습 없이 확장할 수 있다는 건 확실한 이점인 듯함 | 5 |
| 우산안가져옴 | 트랜스포머의 고정된 구조로 인해 발생하는 한계를 해결하려는 시도들의 연구가 많이 나오는 것 같다. 모델 안에 중첩된 서브모델 체인을 구성한다는 아이디어를 생각해냈다는 점이 대단하다. | 4.5 |
| 꼬들목 | “ 8b짜리 학습할 때 3b짜리를 재활용하지 못하고 처음부터 다시 학습함” 이거 개인적으로 아쉬웠던 부분인데 motivation에 있어서 감격스러웠다. 생각보다 성능이 아쉽긴 하지만, 고무적인 연구다. 부럽다 똑똑해서 !!@@@ | 4.5 |
| 육사시미 | Chain-of-XXX 개념을 어디에나 적용할 수 있구나.. 특히 ‘얼마나 생각할지’를 모델 사이즈나 chain 차원에서 제어할 수 있을 것으로 생각됨. 이 아이디어를 기반으로 한 후속 연구가 많이 나올 것 같음 | 4.5 |
| 날씨:흐림 | 한 벡터를 여러 sub-representation으로 분해해서 layer 단위로 활성화하는 발상이 신선하다.. 뭔가 layer 단위의 분해학습인데 의존성이 강조된 느낌..? | 4.8 |
| 마우스 | 새로운 모델 구조를 수학적인 관점에서 제시하고, 기존 모델을 제어하는 방법을 제시하였다는 점이 novelty가 아주 큰 것 같다. | 5 |
TL; DR
💡
Representation을 sequancial한 sub-representation으로 나누면 기존 모델을 유지한 채 추가 학습도 가능하고, 확장도 가능하고 유연함!

Summary
Motivation
- Transformer의 scaling laws 덕분에 많은 기업들이 큰 모델을 만드는데에 전념하고 있으나, 아키텍쳐
확장에는 다음의 문제들이 있음- scale up할 때, 기존 scale을 유지하지 못하고 항상 처음부터 학습해야 함. 사람은 배울때 점진적으로 학습하는데 모델은 그렇지 못함.
- e.g. LLaMA-3-3b 학습하고, 8b짜리 학습할 때 3b짜리를 재활용하지 못하고 처음부터 다시 학습함
- 기존 LLM 아키텍쳐는 항상 고정된 규모의 파라미터를 사용해서, 문제 해결 능력에 따라 동적으로 사용하는 매커니즘이 부족함
- e.g. 3b모델도 잘할 간단한 instruction도 3000b 모델에 맡기는 건 비효율적임
- 작성자 코멘트) 이건 Speculative decoding에서 해결함.. 그래도 fundamental한 motivation은 맞는듯?
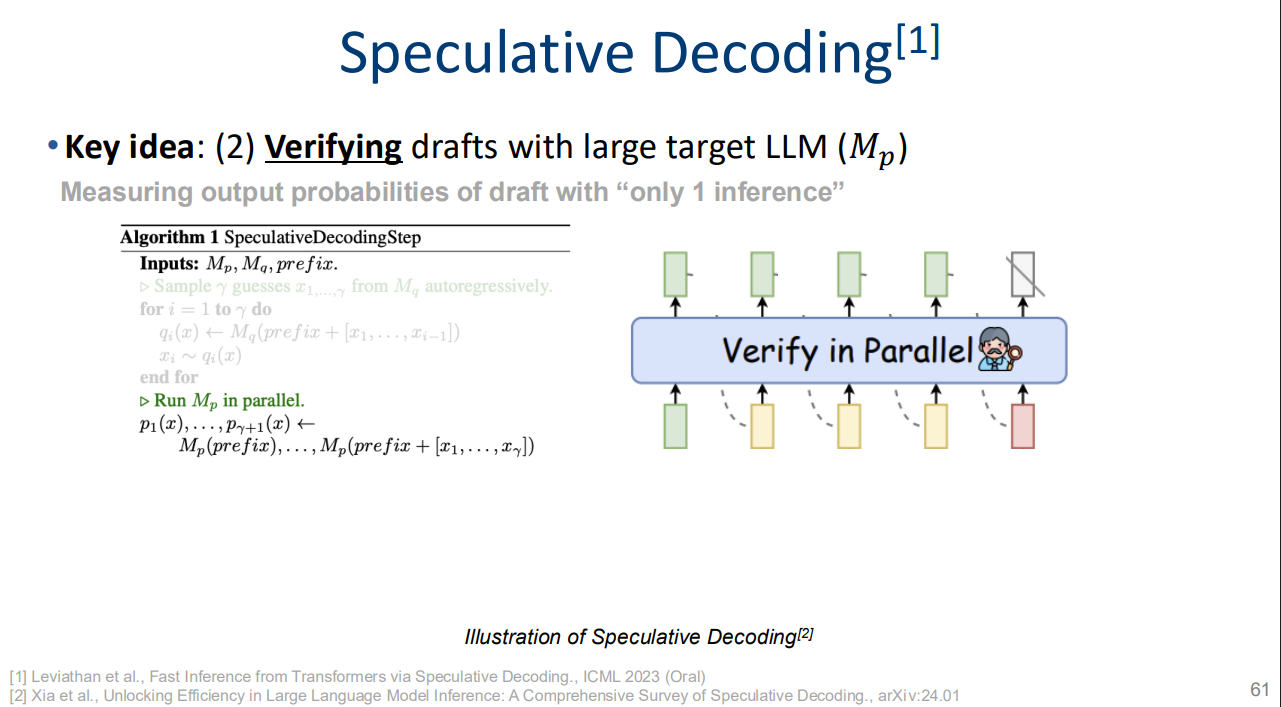
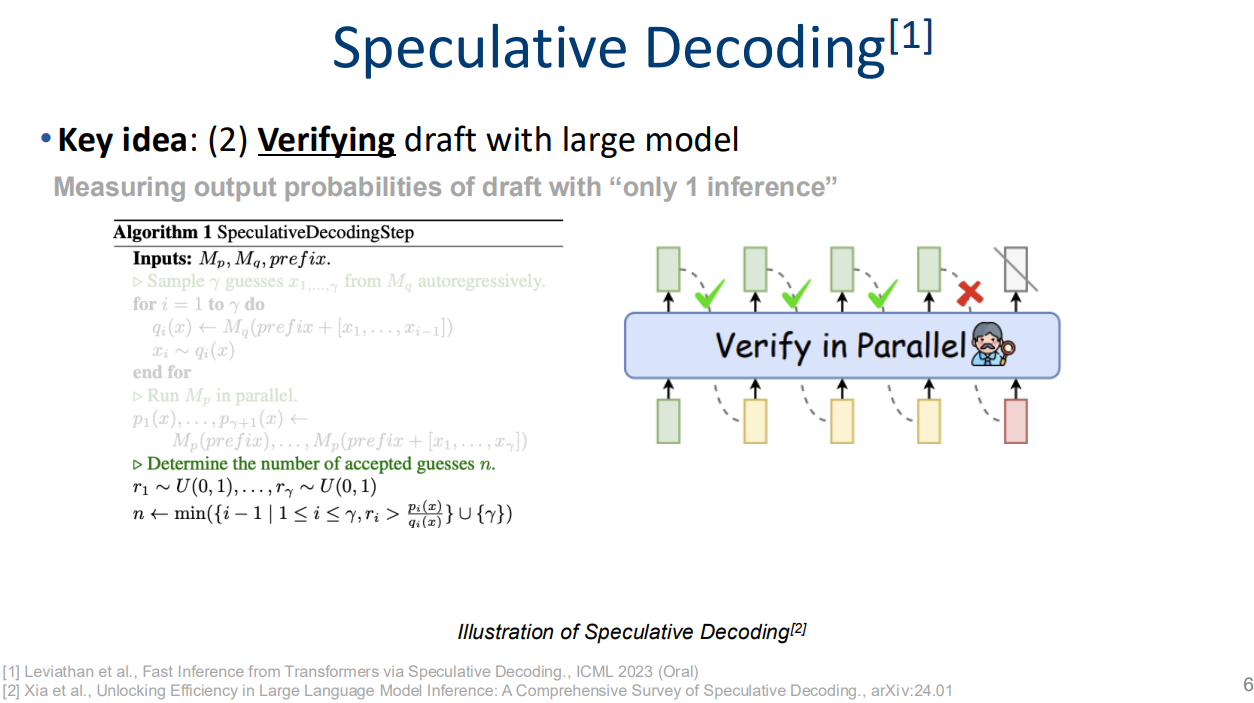
Speculative decoding
https://arxiv.org/abs/2211.17192, ICML 2023 Oral
- 간단하게 말해서! 작은 모델로 돌려본 다음에 큰 모델에서 검증하자!
- e.g. 175b 모델 돌리기 전에, 3b짜리로 몇 토큰 inference해보고 175b llm 돌려서 큰 모델에서도 같은 출력 낼 것이었는지 검증하기

- 간단하게 말해서! 작은 모델로 돌려본 다음에 큰 모델에서 검증하자!
- scale up할 때, 기존 scale을 유지하지 못하고 항상 처음부터 학습해야 함. 사람은 배울때 점진적으로 학습하는데 모델은 그렇지 못함.
Contribution
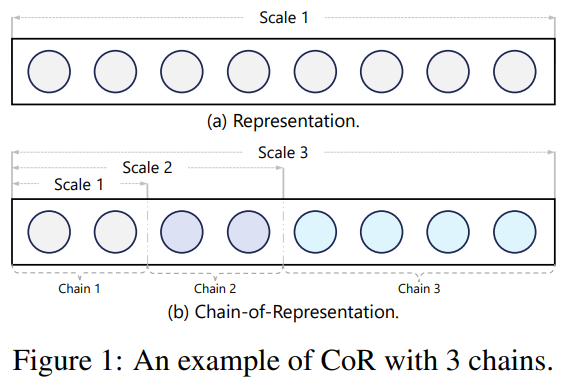
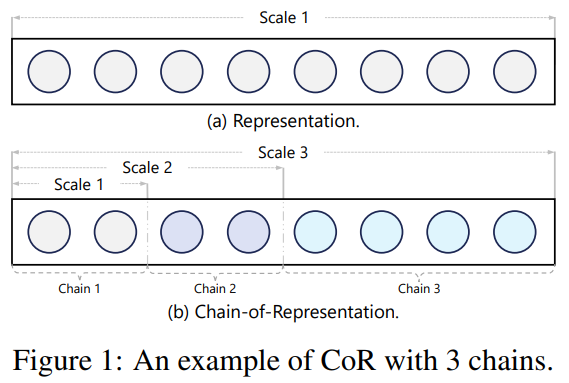
- Representation(hidden state)을 더 일반화하는 Chain-of-Representation(CoR) 제안
- representation을 하위 차원의 sub-representations의 조합으로 보자
- 여러 특징(chain)으로 지식(scale)을 표현하자
- CoR를 잘 모델링하기 위해 Chain-of-Model 제안
- 서로 다른 스케일에 걸쳐 인과적 의존성을 통합하자
- 각 레이어마다 Chain of Layer로 구성됨
- CoL은 다음의 특징이 있음
- 일반성(Generality): 기존의 트랜스포머 레이어는 Chain이 1인 CoL임!
- 인과성(Causality): Scale 의 특징을 얻기 위해 1~까지의 chain 파라미터만 활성화 하면 됨
- 구성성(Compositionality): 두 레이어가 CoL이라면 레이어 끼리도 CoL의 특징을 갖게 됨
- CoL은 다음의 특징이 있음
- 기존 LLM 프레임워크에 비해 성능응 비슷한데 확장성과 유연성에서 뛰어남
Chain-of-Model Learning
- Chain-of-Representation
어떤 표현 에 대해, 이는 항상 n개의 하위 표현들의 concatenation으로 동등하게 나타낼 수 있으며, 로 표기함. 여기서 이고, 임.
이걸 Chain-of-Representation, CoR이라 정의함
- 각 chain은 CoR내의 하위표현 에 해당됨.
- 첫 개의 체인을 활성화해, 스케일 에 해당하는 정보를 인코딩할 수 있음
- 즉, CoR은 한 표현 내에서 n개의 정보를 인코딩할 수 있음
- n=1이면 CoR은 원래 표현과 동일
- Chain-of-Layer
- 번째 scale은 1~-1까지의 정보만 활용해야 함
- CoR의 인과 관계를 통합하는 Chain-of-Layer 제안
레이어 에 대해, 입력 x와 출력 y가 모두 CoR 와 로 표현될 수 있다고 가정. 각 가 오직 에만 의존하여 발현되는 를 Chain-of-Layer, CoL이라고 정의함
- 작성자 코멘트) RNN과 유사한것 같음
- Corollary(따름 정리)
- Generality
- 일반적인 트랜스포머 레이어는 chain이 1인 경우임. → 기존 모든 레이어는 CoL 형태를 만족함!
- 기존 chain 위에 추가 chain을 넣어서 이미 있는 모델에서 확장할 수 있음
- Causality
- 레이어 가 CoL을 만족한다면, 가중치 는 독립적인 가중치 로 분할할 수 있고, 각 는 를 기반으로 를 계산하는데 사용됨. 즉, 출력 를 얻기 위해 를 기반으로 를 계산해야 함.
- 이 CoL 설계에서 번째 scale을 계산할 때, 이전 scale의 정보를 통합하므로 catastrophic foggeting을 방지할 수 있음. 를 얻기 위해 만 계산하면 되므로, 파라미터를 동적으로 사용함.
- Compositionality
- 두 레이어 , 가 있고 x, y, z 모두 CoR로 나타낼 수 있다고 가정.
, 가 CoL이라면, 합성함수인 도 CoL을 만족함. 즉 는 에서만
의존함
- 여러 CoL을 쌓아도 전체로 보면 CoL이 유지됨 → 모델로 확장 가능
- 두 레이어 , 가 있고 x, y, z 모두 CoR로 나타낼 수 있다고 가정.
- Generality
- Chain-of-Model
L개의 레이어를 가진 모델 에 대해 모든 레이어가 CoL이라면, 이를 Chain-of-Model, CoM이라 정의함
- CoM이면 CoL과 마찬가지로 generality와 causality를 가짐.
- 모든 모델은 CoM(n=1)이고, 하나의 모델 내에서 다른 scale의 여러 하위 모델을 통합할 수 있으며, base model을 활용하여 확장할 수 있음. → 확장성, 유연성 확보
Architecture
- 이제 개념정리 했으니 실제로 모델에 적용해 구현해보자!
- Linear Layer
- 아래 그림에서처럼, linear layer에서 CoL를 만족하기 위해 condition을 걸어서 출력을 계산함
-
- Chain이라는 하이퍼 파라미터를 걸어서, 각 chain()이 이전 chain을 포함해 계산하도록 설정
- 일반 linear layer는 n=1인 경우임
- Chain-of-Linear라고 부름!
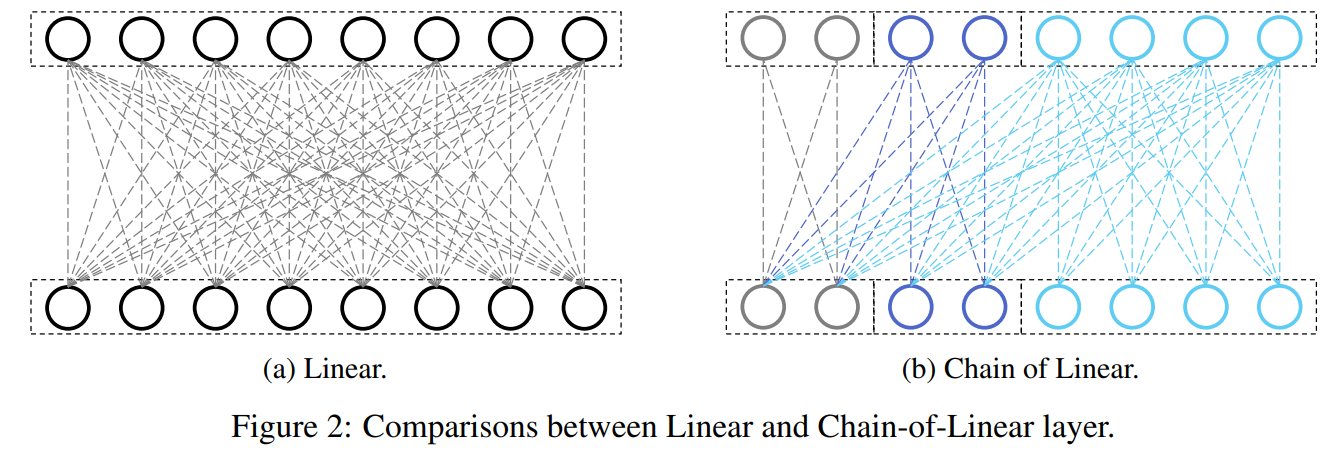
- 아래 그림에서처럼, linear layer에서 CoL를 만족하기 위해 condition을 걸어서 출력을 계산함
- Transformer
- Multi Head Attention
- 각 임베딩에서 CoR을 지원하기 위해, Key, Query, Value, Output 변환 행렬을 모두 Chain-of-Linear 레이어로 바꿈
- 에서
단일 헤드내에서 chain이 2개 이상일 경우 chain간의 정보가 혼합되어 CoL이 아니게 됨. 그래서 각 헤드가 특정 chain만 계산하도록 함!- e.g. 어떤 헤드는 1~2까지만 계산하고, 어떤 헤드는 3~4까지, 다른건 5~8까지 이런식으로
- Chain-of-Attention
- Feed-Forward Network
- 간단하게 각 linear를 CoL로 대체하고, 위의 Chain-of-Attention과 같은 하이퍼파라미터 Chain(representation에 대해 Chain 어떻게 쪼갤지, e.g. 2, 2, 4) 사용!
- Normalization
- 각 체인별로 정규화함
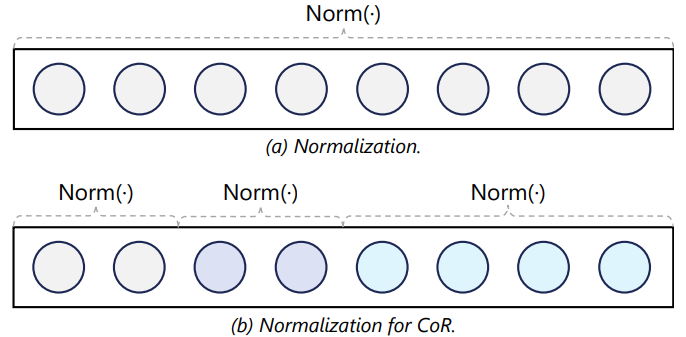
- Embedding
- Scale 에서 인코딩할 때는 1~의 chain에 해당하는 임베딩만 사용함
- Multi Head Attention
- KV sharing
- 어텐션에서 각 chain마다 key, value를 가져서 서로 다른 scale을 연결할 때 align이 잘 안됨
- e.g. 작은 모델로 추론하다가 확장된 모델로 추론할 때, context에 대한 key, value를 다 새로 계산해야 함
- KV sharing으로 해결함!
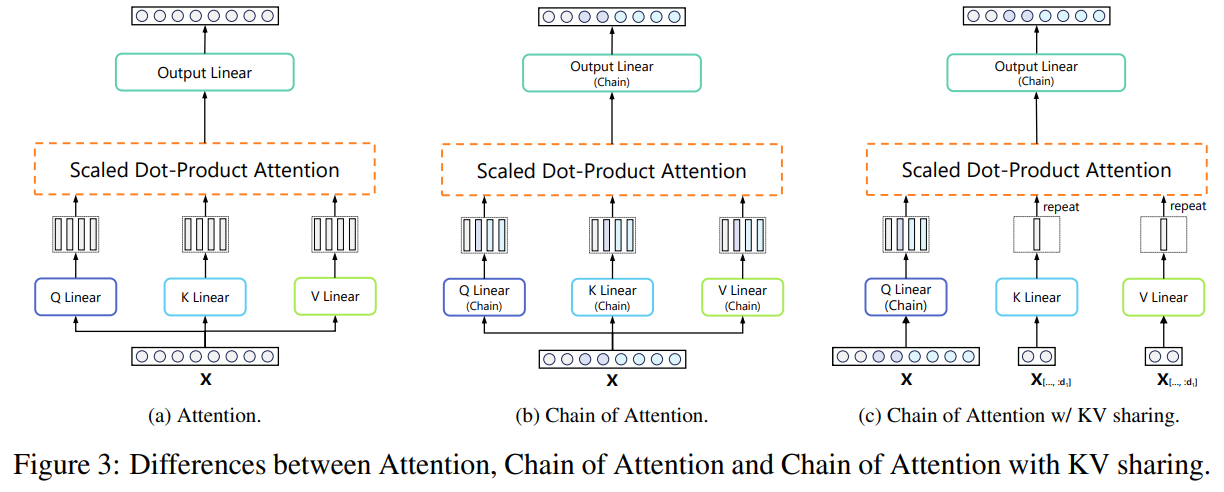
- 모든 key, value값이 첫번째 chain에서 계산 한 후, 모든 chain에서 공유됨
- key, value의 수가 head보다 적으면, 값을 반복시켜서 때움
- 이렇게하면 성능이 살짝 낮아지기는 하는데, prefilling이 빨라지고, 서로 다른 스케일의 LM으로 끊김없이 전환하면서 생성할 수 있음!
- 이를 Chain-of-Language-Model Air, CoLM-Air라고 부름(shairing 안하는게 CoLM)
- 어텐션에서 각 chain마다 key, value를 가져서 서로 다른 scale을 연결할 때 align이 잘 안됨
- Objective Function
- 일반적인 cross-entropy손실을 objective로 쓸 수 있지만, multi scale prediction을 하려면 각 scale마다 classification head(representation→vocab 행렬)을 써야함
- 그래서 각 scale을 계산하는 multi-chain cross-entropy loss를 제안함
-
- 근데 loss 계산하는건 계산량이 커서, fine-tuning할때만 사용함
Experiments
- Setup
- 0.2T의 corpus로 pre-training
- 32개의 Nvidia A100 40GB GPU 사용(부럽다)
- baseline 모델은 =32 세팅, 나머지는 Llama-3.2-1B랑 동일한 구성
- CoLM 시리즈는 , 사용
- Chain-of-Linear가 파라미터를 적게 차지해서, dimension을 늘림
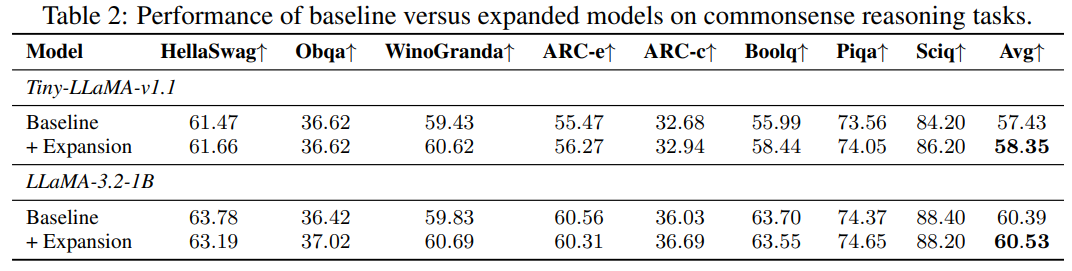
- 상식 task에서 zero-shot setting으로 실험
- Results
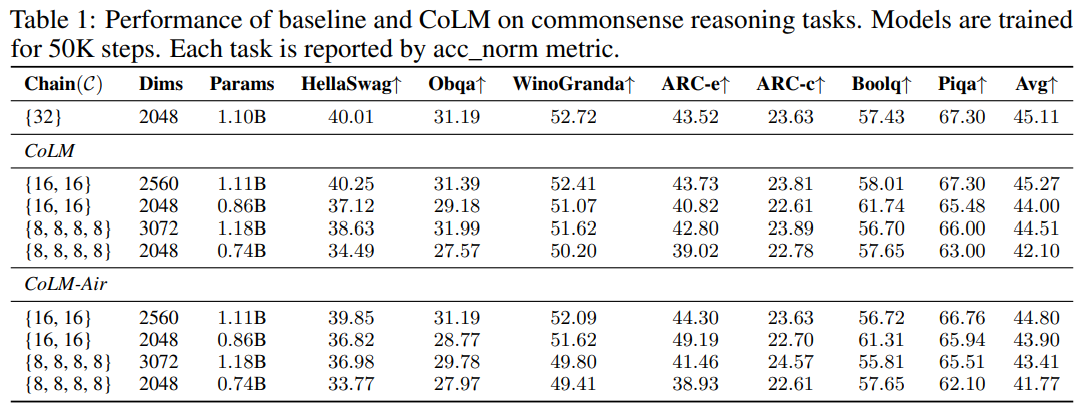
- KV sharing을 하면 성능 살짝 떨어짐
- 의외로 16, 16 세팅이 8, 8, 8, 8보다 나음
- 다만 더 많은 chain을 사용하면 하위모델을 더 많이 제공할 수 있음 (8, 16, 24)
- 모든 모델은 chain이 1인 CoLM이므로 chain을 더 붙여서(dimension을 늘려서) 확장할 수 있다!
- {32, 8} 세팅으로 0.8B 파라미터 추가함
- 기존 지식 보존하면서 학습도 빠르게!

- 동적으로 추론하기
- 작은 모델로 배포할 수 있음!
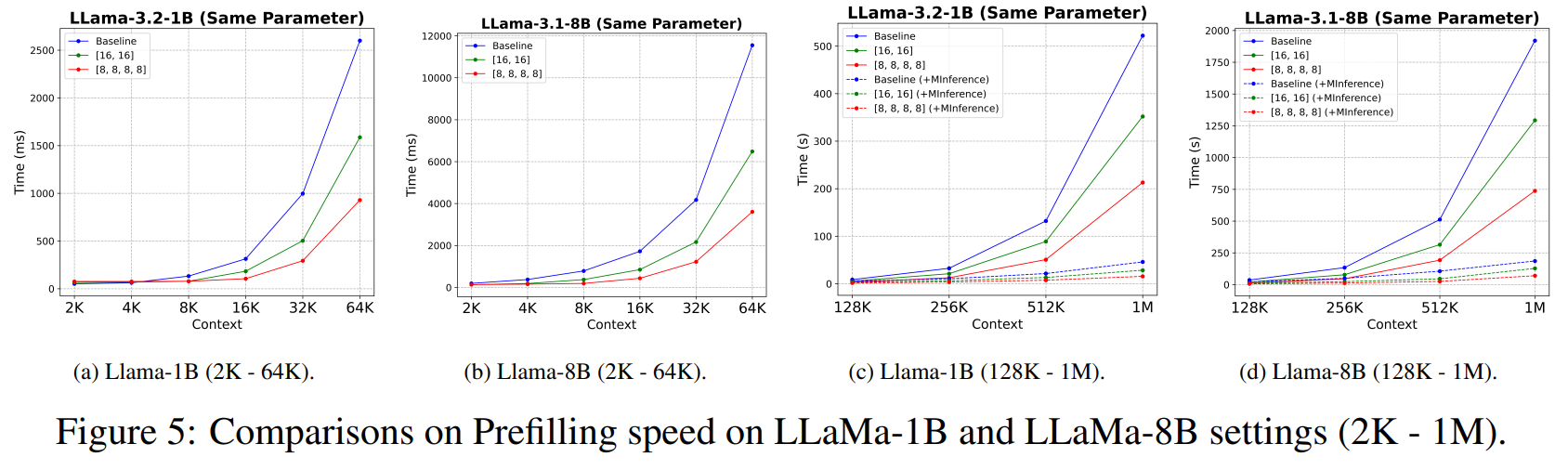
- CoLM-Air를 사용했을 때, 첫번째 chain에서 모든 key와 value를 계산해서 prefilling을 아주 빠르게 함
- MInference는 추론 기술인데 추가로 적용해도 같은 양상

- fine-tuning할때, 마치 base-model을 확장한 것처럼 후속 chain만 fine-tuning 가능함
- 이는 치명적인 망각을 막음!
- 일부만 fine-tuning해도 성능이 꽤 올라감
- 심지어 이것도 LoRA랑 호환됨