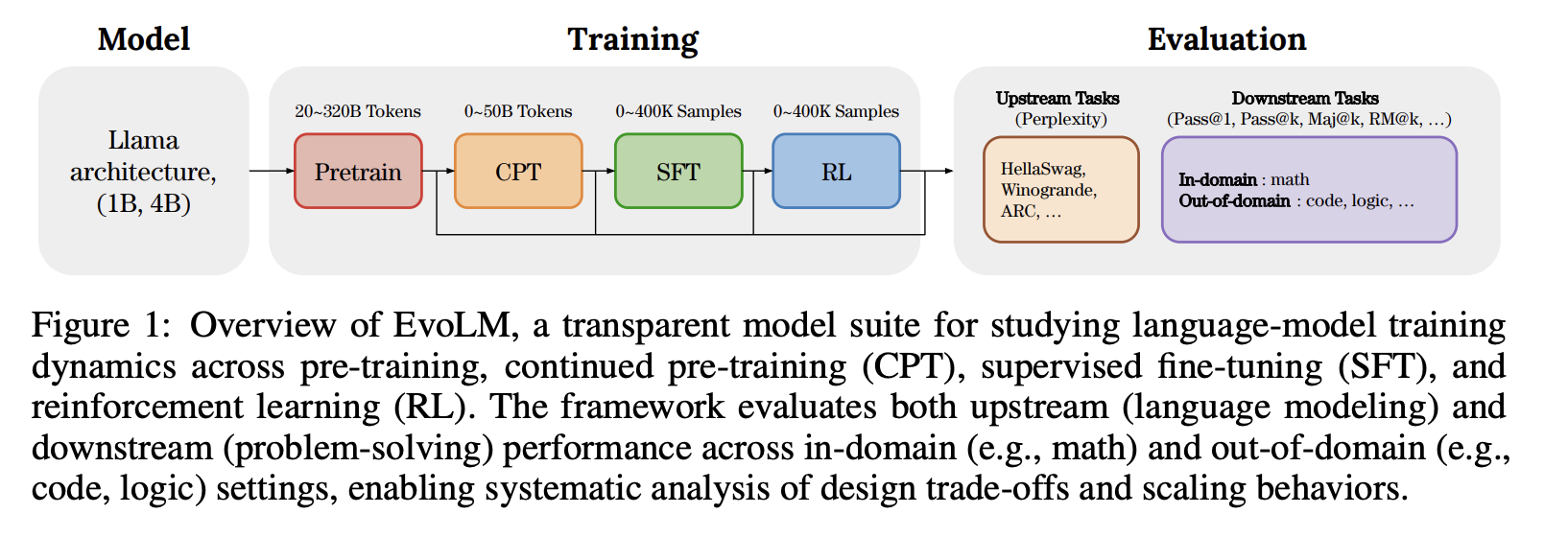
EvoLM: In Search of Lost Language Model Training Dynamics
Review
| 닉네임 | 한줄평 | 별점 (0/5) |
|---|---|---|
| 마스킹테이프 | 이번주에 소개되는 다른 논문과 비슷한 것 같음. 언제, 어떤 데이터를 학습하는 것이 중요하다는 커리큘럼 러닝 등에서 이미 나왔던 아이디어지만, 그것을 이론적으로, 분석적으로 확인하는 연구는 도움이 된다고 생각함. 데이터는 무한하지 않고, 좋은 데이터는 많은 양이 존재하지 않음. 그러므로, 가진 데이터를 가지고 어떻게 학습할까 고민하는 것이 다음 숙제라고 생각하는데, 그 방향성에 있어 도움이 될 수 있는 논문 갈래라고 생각함. | 4.2 |
| 귤 | 요즘 연구 흐름이 단순히 모델 성능을 올리는 것 뿐이 아니라 같은 성능을 더 적은 자원으로 효율적으로 달성하는 방법으로 초점이 점점 옮겨가는 듯 싶음. 그리고 훈련 자체를 어떻게 설계해야 효율적인가를 중점으로 생각해보면 좋을듯 | 4 |
| 동까스 | 다양한 방식(pre-training, CPT, SFT, RL) 별로 스케일링이 미치는 영향을 분석해서 참고해서 보기 좋을 논문이라고 생각함. 최적의 스케일링을 찾는게 올해 대세인가? | 3.9 |
| 수면장애 | motivation만 봤을 때에는 당연한 소리들의 나열이었지만, 실험 내용 및 contribution을 보니 정말 누군가는 진작에 했어야 (LLM 붐이 일기 시작할 때 쯤) 하는 연구이자, 정말 NIPS다운 연구인 것 같다! | 4 |
| 이어폰 | 새삼 분석 실험 이런 걸 중심으로 논문쓰려면 정말 많이 실험해야되는구나 싶다. 훈련 단계별 특성과 성능 끌어올리는 설정을 많이 알려줘서, 모델 파인튜닝 실험할 때 실용적으로 사용할 수 있어보인다 | 3.9 |
| 사과 | Motivation 자체는 당연한 결론이라고 할 수 있지만, 이걸 하나하나 조건을 변화시켜 가면서 스케일링을 한 점이 의미가 있는 논문임. 실험을 효율적으로 진행하기 위해 Saturation되는 peak지점까지 학습을 해서 최고의 성능을 달성하는 부분에 많은 참고가 될 수 있을 것 같음. | 3.7 |
| 7일 | 위 temporal dependence 논문은 하나의 파이프라인에서 데이터가 언제 학습됐는지를 봤다면, 이 논문은 여러 파이프라인 자체를 비교한 느낌. SFT는 도메인 적응이 중심이되고, RL은 출력의 안정성을 고려할 때 활용하다는 실험적인 인사이트를 얻을 수 있다 | 4.3 |
TL; DR
Language Model의 성능이 얼마나 큰 데이터셋으로 오래 학습했는가보다 어떤 단계에서 어떻게, 언제 학습했는가가 더 중요하며 CPT(Continued Pre-Training)가 지도 학습 및 강화 학습의 성능을 결정한다.
Summary
연구팀: Harvard, Stanford, CMU, EPFL 연구진
Motivation
- 현재의 언어 모델(Lauguage Model)의 학습(Training) 과정은 여러 단계로 나누어져 있어 각각의 단계에서의 영향을 알기가 어려움.
- Supervised Fine-tuning(SFT)와 Reinforcement Learning이 얽히면 더욱 결과가 복잡해짐.
- 모델의 언어 생성 자체의 능력과 Problem-Solving 능력은 별개의 문제로서, downstream performance improvement가 부드럽지 않음.
- 과도한 Pre-training과 Post-training을 조정하고, Continued Pre-training을 통해 forgetting을 제어할 수 있어야 한다는 것이 요점.
- 투명하지 않은 체크포인트, 모델 조건으로 공정한 비교 안됨.
- 기존의 모델 Training에서 Post-training 연구를 진행할 때, 모델 크기, Pre-training 데이터 크기, 데이터 구성요소를 엄격하게 통제하지 않는 문제
- Incomplete learning rate decay로 인해 최적이 아닐 수도 있는 중간 체크포인트(checkpoint)가 평가에 이용되어 공정한 비교를 방해하는 문제 발생.
Contribution
- 언어 모델의 능력을 체계적으로 처음부터 끝까지 분석
- Pre-training부터 Reinforcement Learning까지
- 언어 모델 자체의 능력(upstream task)와 문제 해결 능력(downstream task)를 모두 비교하고, in-domain과 out-of-domain의 일반화 능력 비교
- 처음부터 1B, 4B 파라미터 규모로 학습한 100+ 언어 모델과 학습 데이터를 공개
- Training Pipeline과 Evaluation Framework를 공개하여 모델의 학습 조건과 언어, 문제해결 능력의 후속 연구 가능
Experimental Settings
- Training Setup
- Pre-training 사용 데이터: FineWeb-Edu(교육 중심 웹 데이터셋)
- Continued Pre-training 사용 데이터: Fine-Math(tngkr-cnfhs wndtla epdlxj)
- Supervised Fine-tuning 사용 데이터: GSM8K, MATH 기반 QA
- RL 사용 데이터: SFT와 동일하나 disjoint하게 구성
- Evaluation Protocol
- Upstream Cloze Task (언어 자체 모델링 능력)
- 대화 능력을 제외하고 순수한 다음 토큰 예측, 상식-추론 기반 능력 평가
- 0-shot accuracy 방법 사용, 평가 성능을 여러 데이터셋에 대해 계산
- 데이터셋: HellaSwag, Winogrande, PIQA, OBQA, ARC-Easy, Challenge
- Downstream Cloze Task (생성 기반 문제 해결)
- 질문을 이해하고 해결 과정을 생성하여 정답 도출(문제 해결 능력)
- ID(In-Domain): 수학 및 추론 중심(GSM8K-Platinum, MATH)
- OOD(Out-of-Domain):
- CRUXEval: 코드 추론
- BGQA: 논리 추론
- TabMWP: 테이블 기반 추론
- StrategyQA: 상식·전략적 추론
- 정확도 평가 지표
- Pass@1 (Greedy)
- Temperature = 0
- 단일 정답이 맞으면 정답으로 간주
- Maj@16
- Temperature = 1
- 16개 샘플 생성
- 다수결 결과로 정답 판단
- RM@16
16개 중 ORM 점수가 가장 높은 응답 선택
ORM점수: Skywork-Reward-Llama-3.1-88-v0.2에서 제시되었으며 생성된 해답에 대해 스칼라 점수 부여하여 정답 여부뿐 아니라 풀이의 일관성 반영
- Pass@16
16개 중 하나라도 맞으면 성공
- Pass@1 (Greedy)
- Upstream Cloze Task (언어 자체 모델링 능력)
Scaling Studies Across Three Training Stages (Methods)
Scaling Up Pre-Training Compute
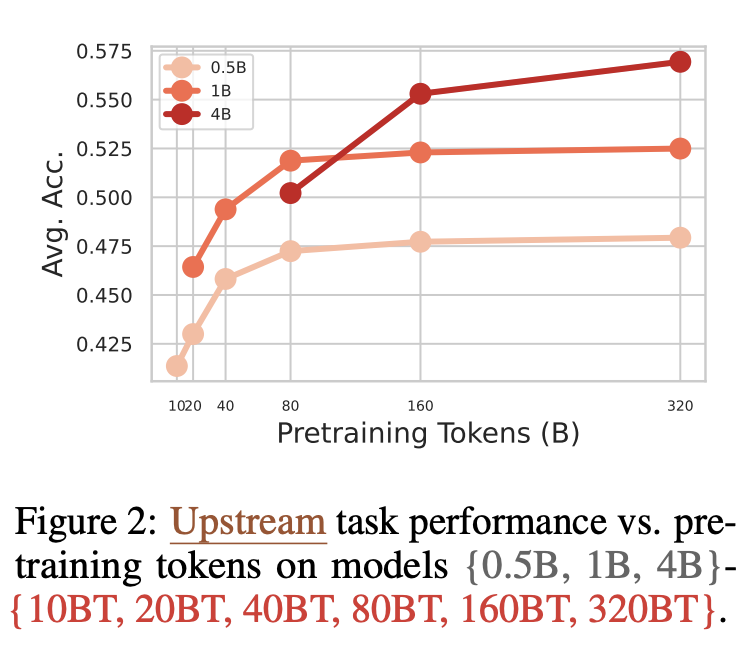
- Pre-training의 양이 모델의 성능이 미치는 영향을 알아보기 위하여 0.5B, 1B, 4B모델로 token의 양을 10B부터 320B token까지 pre-train함.
- 처음에는 점차 비례하여 증가하다가, 모델 크기의 80배에서 160배가 되는 시점에서 Accuracy의 증가폭이 점차 감소
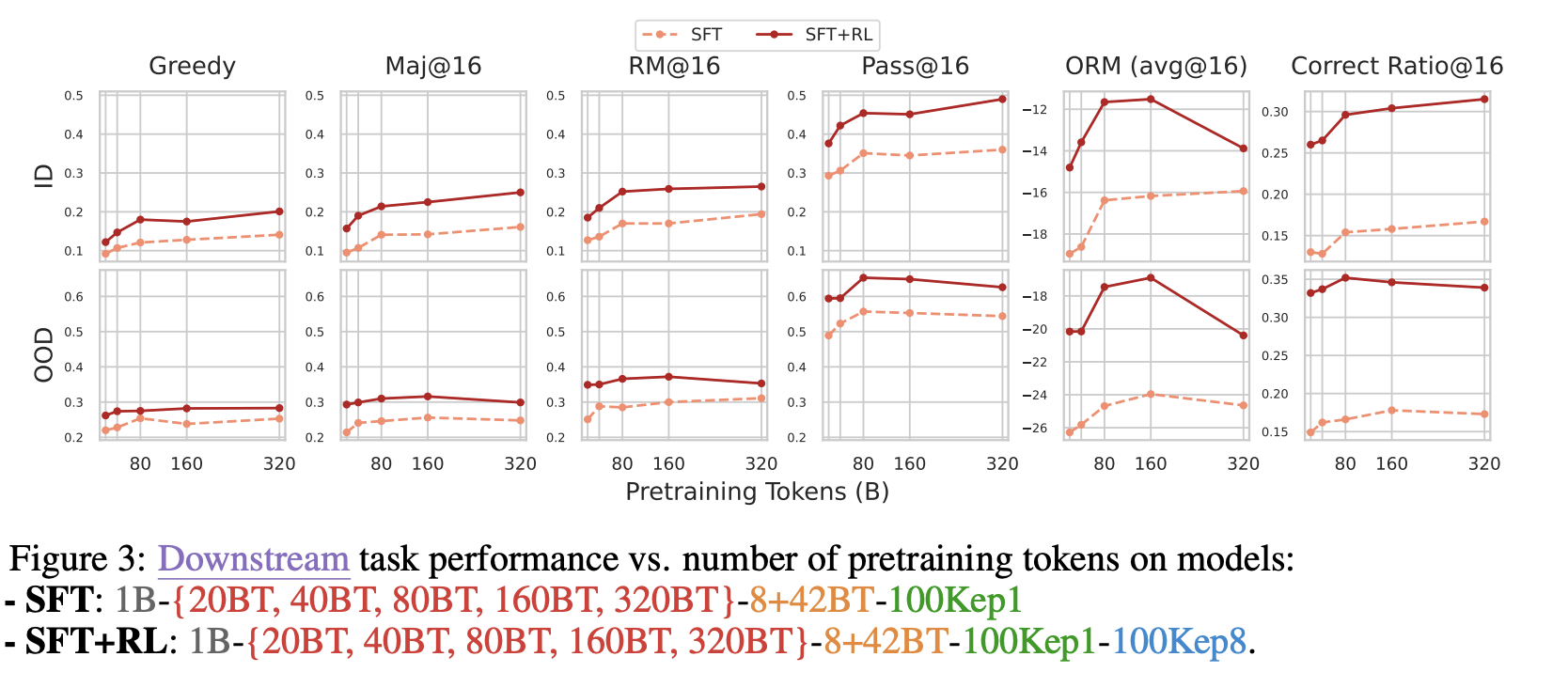
- SFT 모델과 SFT-RL 모델을 모두 비교하였을 때, 80B Token까지는 뚜렷한 성능 향상을 보이다가 그 이후에는 뚜렷한 변화 없음
- ID Maj @ 16의 경우 20BT까지 8%에서 15%로 급격하게 상승하다가 이후 320BT까지 17%로 큰 변화 없음
- 전체적으로 Reinforcement Learning (RL)을 추가하였을 때, 추가하지 않은 경우보다 성능이 높지만 이 경우 역시도 80BT 이후에 뚜렷한 상승을 보이지 못함
- Out-of-Domain (OOD)의 경우에는 160B Token 이후에 오히려 Accuracy가 감소하는 결과를 보임
- Degradation을 일으켜 오히려 생성 품질이 떨어짐
⇒ 결론: General Model Pre-training이 과도하면 오히려 성능이 떨어지는 결과를 초래하며, 항상 많은 Pre-training이 좋은 결과를 내는 것은 아님
Scaling Up Continued Pre-training (CPT)
160B Token으로 Pre-trained된 1B Model에 Continued Pre-training을 하지 않는 경우부터 50B Token으로 Pre-train하는 경우까지 비교
- Continued Pre-training (CPT)를 거듭할수록 Upstream Task (일반 언어 성능)은 감소함(Catastrophic Forgetting)
- 문제 해결을 위해 Replay 전략을 사용
- 소량의 Pre-training data를 랜덤하게 섞어서 사용
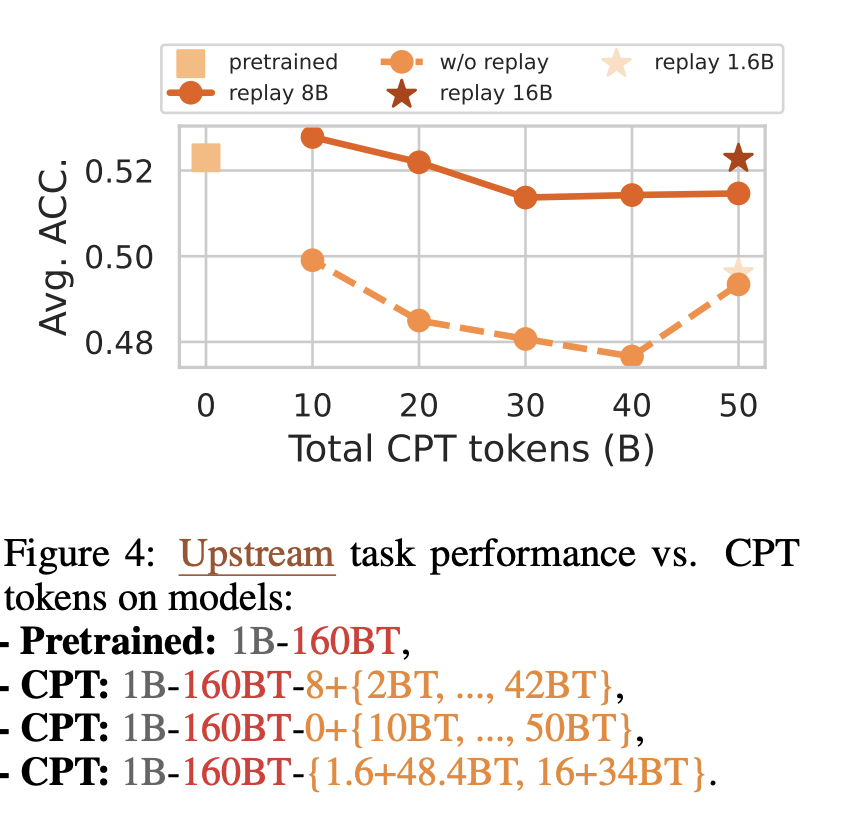
- 8B Token만큼 Replay했을 때가 하지 않았을 때보다 전체적으로 성능이 높음을 보여줌

- 그러나 Too much replay(16B Token)에서는 성능이 떨어짐
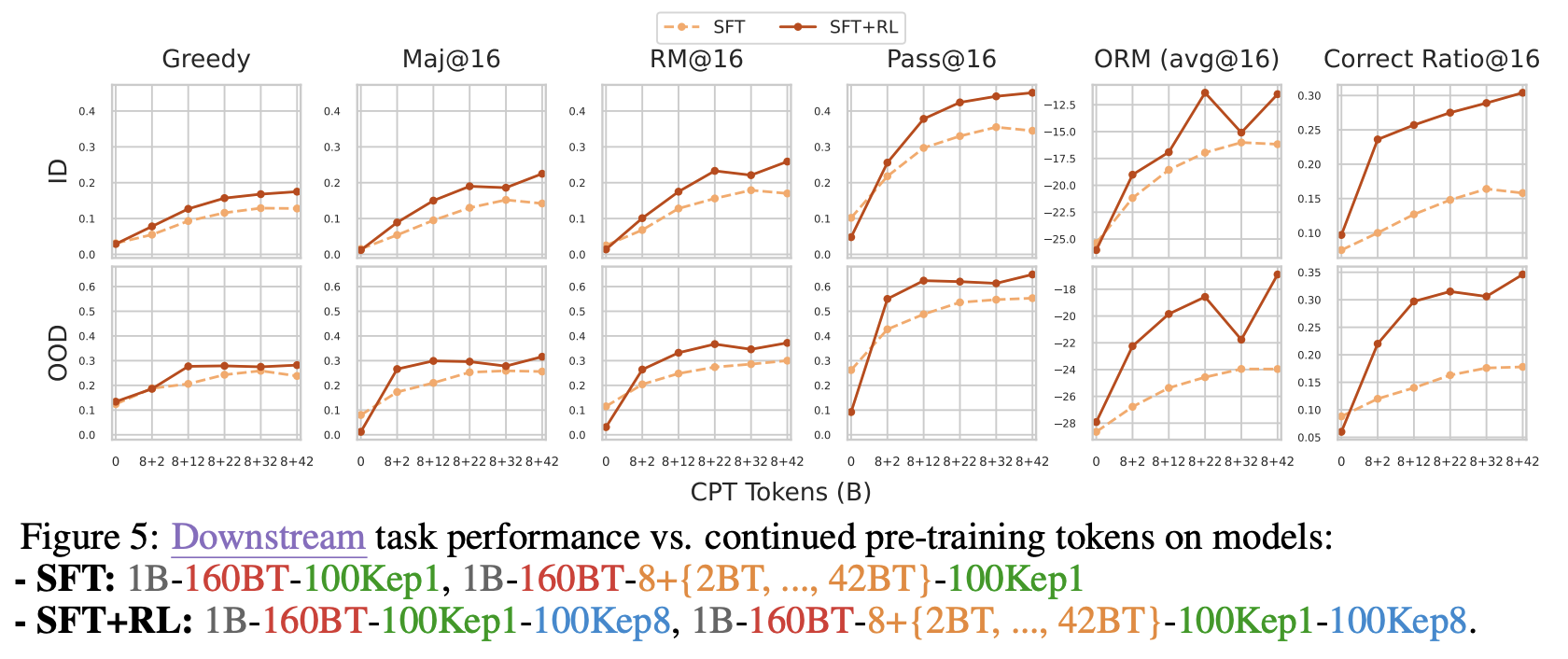
- Downstream Task에서는 CPT Budget이 증가할수록 In distribution (ID)와 Out-of-distribution (OOD)에서 모두 2B에서 32B Token까지는 성능이 급격히 상승
- 32B이후에는 CPT의 성능 향상 효과가 제한적임
⇒결론: Domain 특화 Post-training은 충분한 CPT에 의해 뒷받침 되어야 원하는 성능을 얻을 수 있으며, CPT 데이터가 증가함에 따라 ID(In-distribution)과 OOD(Out-of-distribution) 모두에서 이익을 얻을 수 있음
Scaling Up Supervised-Fine-Tuning (SFT)
SFT가 Training 및 모델 성능에 미치는 영향을 알아보기 위해 Epoch과 Dataset size를 변화
- Epoch
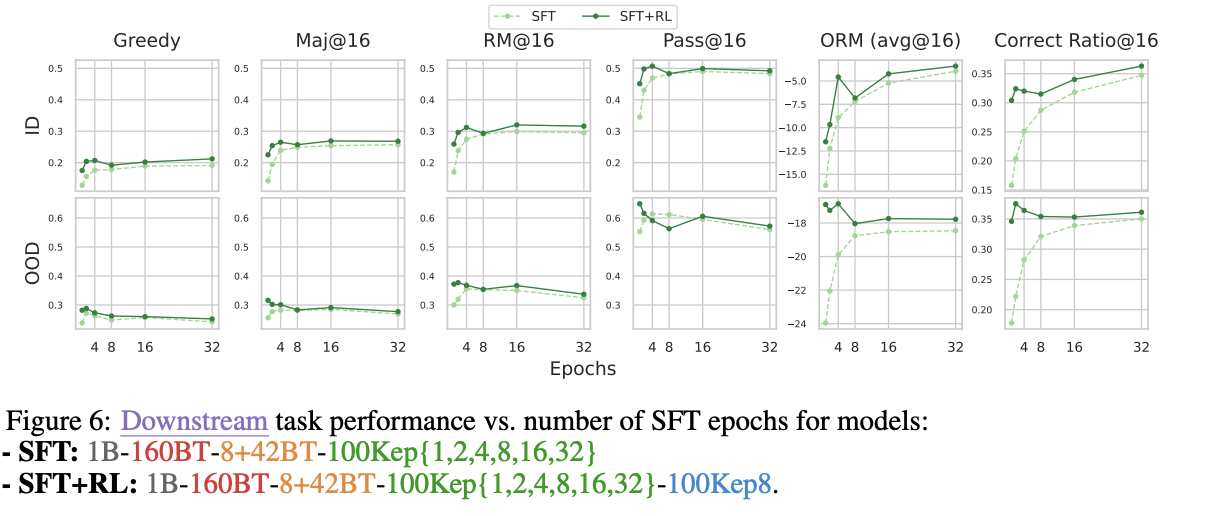
- 1, 2, 4, 8, 16, 32 epoch으로 각각 training하였을 때, ID(In-distribution) metric이 꾸준하게 증가하는 추세를 보이다가 8 epochs 근처에서 정체됨
- OOD의 경우 2-4 epochs에서 peak였다가 감소하는 것으로 보았을 때, over-specialization이 일반화 성능을 해침을 알 수 있음
- 3 Epochs에서의 SFT가 가장 적합함을 보여주고 있으며, 과도한 SFT Epoch로 인해 뒤의 Reinforcement Learning (RL)의 이점을 사라지게 만듦
- SFT Dataset Size의 변화
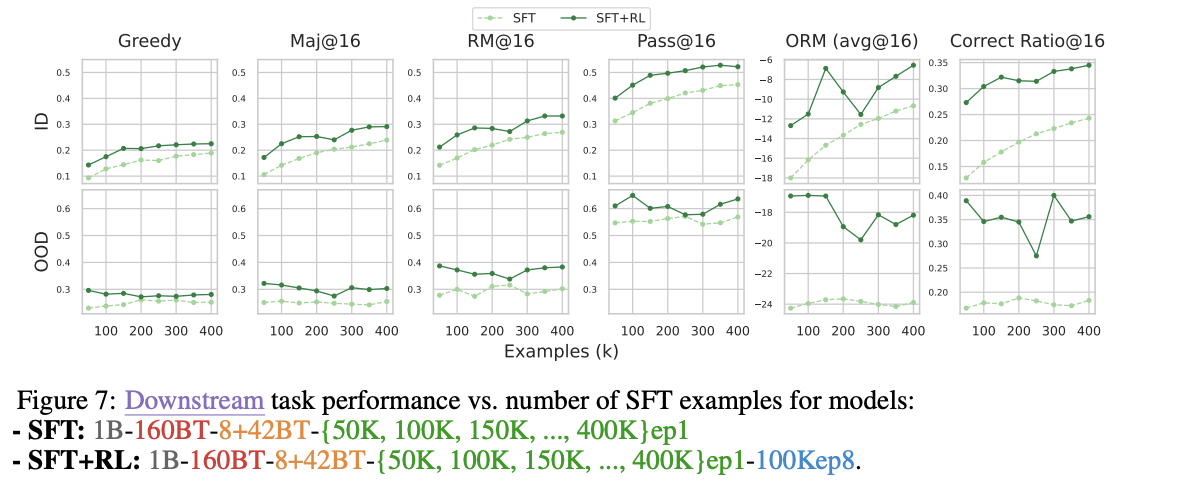
- SFT 데이터의 크기를 50K, 100K, 150K, …, 400K까지 늘려보면서 실험
- ID의 성능은 Dataset Example이 증가하면 계속 증가하는 양상
- OOD의 성능은 들쭉날쭉하고 심지어 하강하는 경우도 있었음
- 후의 Reinforcement Learning (RL) 단계에서의 성능 향상에 제약이 될 수도 있는 사항임
Scaling Up Reinforcement Learning (RL)
RL Epochs와 RL Dataset Size를 변화시켰을 때의 Accuracy의 변화를 알아봄
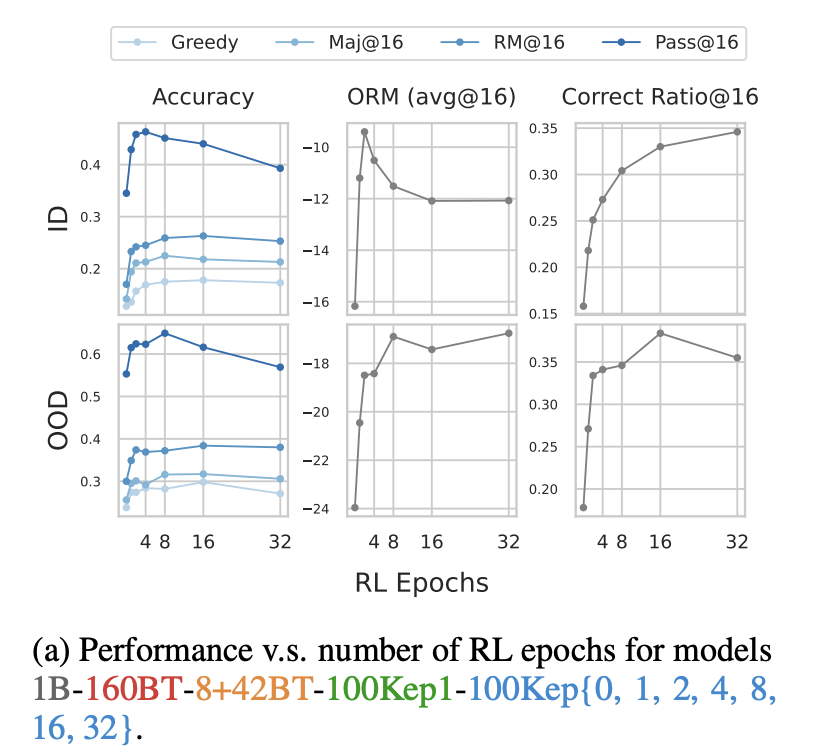
- RL Epoch의 변화
Greedy, Maj@16 , RM@16 성능은 8–16 epoch에서 peak 후 정체
- Correct Ratio@16→epoch가 늘어날수록 계속 증가
- Pass@16→4 epoch 이후 급격히 감소
- RL은 epoch이 과도하게 늘어날수록 출력 다양성을 감소시키고, 1-2개의 정답만 계속 생성하게됨
- Maj @16 vs Greedy
- SFT-only 모델은 Maj@16이 Greedy보다 성능이 저조한 경우가 있음
- RL을 적용한 모든 경우에서 Maj@16이 Greedy보다 우수한 성능
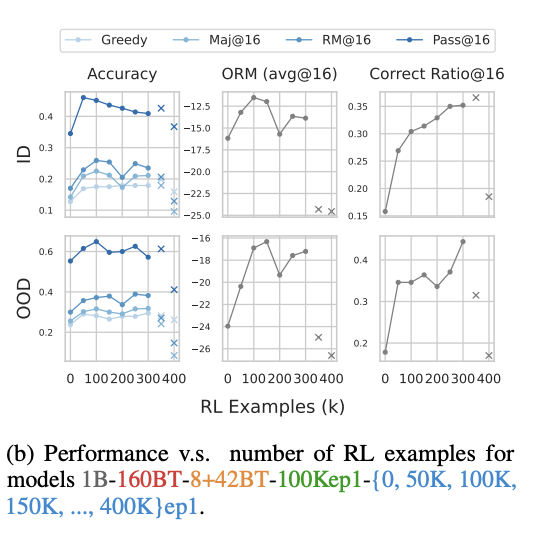
- RL Dataset Size의 변화
- RL Epoch을 8로 고정하고, 데이터의 크기를 0부터 400K까지 조정해 가며 관찰
- ID와 OOD 모두에서 Accuracy가 150-200K까지 증가하다가 정체
- Pass@K는 오히려 일찍 정체되고 하락하기까지 함
- Pass@K: 여러 샘플 중 하나라도 정답이 있으면 맞는 것으로 인정, 출력의 다양성이 중요
- RL 데이터가 많아질수록 다양성이 감소하여 같은 답만 계속 내놓게 됨
- 새로운 문제를 맞히는 능력이 증가하는 것이 아닌, 이미 맞힐 수 있을 만한 문제를 더 정확하게 맞히는 방향으로 학습이 되는 것
SFT와 RL의 데이터 분할
500K 데이터 중 랜덤으로 추출한 100K의 데이터를 (10 / 90, 30 / 70, 50 / 50, 70 / 30, 90 / 10)비율로 나눔
100K가 peak로 성능 정체가 시작되는 시점이므로 데이터 크기를 100K로 선택
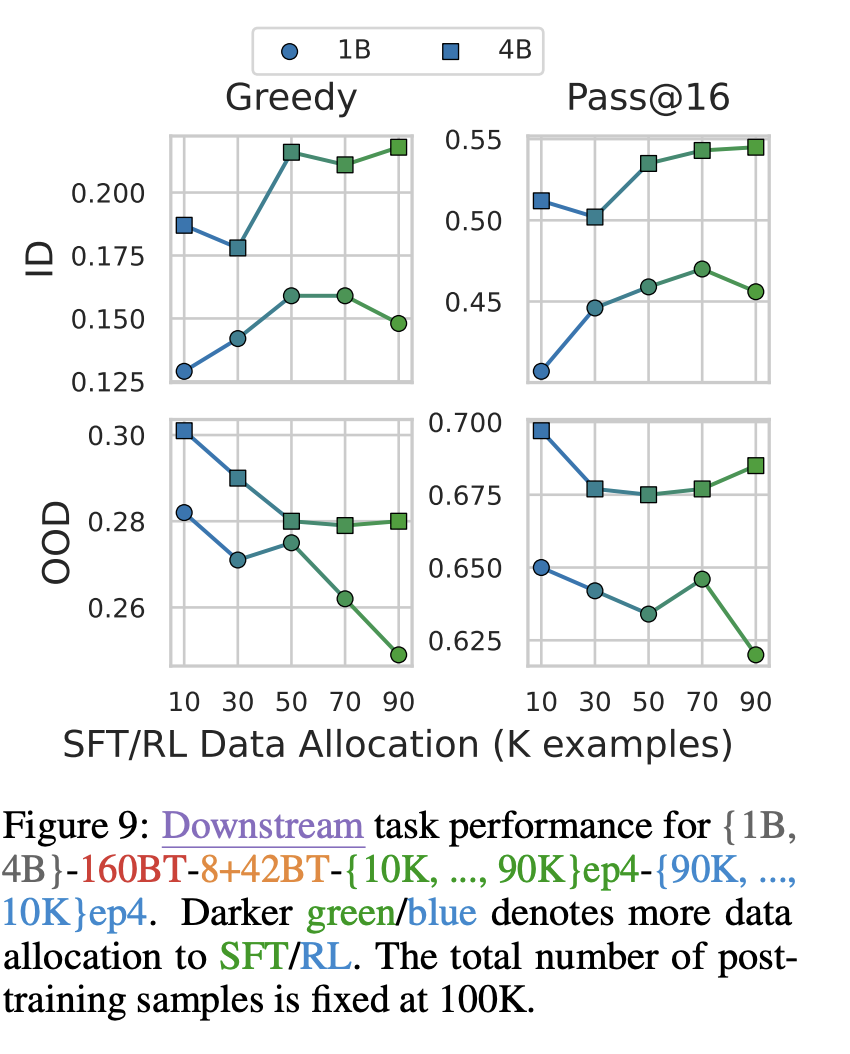
OOD 성능의 경우 SFT가 70K일 때, 갑자기 감소하는 것을 확인할 수 있음. 이에 SFT보다는 RL의 비중이 중요하고, RL이 90K인 시점에서 OOD의 성능은 가장 우수⇒OOD의 성능은 RL이 결정
여기서는 ID와 OOD의 성능이 trade-off관계임을 알 수 있음
Conclusion
- 무조건 모델 학습에서 Scale을 키우는 것만이 정답은 아니다
- Token 수, SFT 데이터셋 크기, RL을 늘리면 성능은 처음에는 증가하나 일정 지점 이후 정체
- 과도한 학습은 성능 정체 및 학습 비용만 증가
- 심지어 성능이 저하되는 경우도 존재
- Domain-specific Continued Pre-training (CPT)은 필요하지만 적절하게 사용해야 함
- CPT는 Downstream(특정 task 문제 해결) 성능의 핵심 기반
- CPT를 무분별하게 늘리면 Catastrophic Forgetting 발생
- Replay 데이터와 균형
- SFT와 RL은 서로 다른 역할
- SFT: In-domain 성능을 끌어올리나, 과도할 경우 일반화 성능 저하
- RL: 기존 정답에 대한 confidence를 강화하며, OOD에 유리
- RL이 과도할 경우 출력 다양성 감소, Pass@K 하락 등 단점