Superposition Yields Robust Neural Scaling
Review
| 닉네임 | 한줄평 | 별점 (0/5) |
|---|---|---|
| 마스킹테이프 | 솔직히 말해서, 연구진이 대단하다. 보통 논문들은 결과를 보면 과정이나 motivation이 직관적인데, 이건 motivation은 직관적이어도 과정은 쉽게 떠올리기 어려움. 데이터를 다 써간다는 뉴스기사를 본적이 있는데, 더 큰 모델, 더 큰 데이터, 더 큰 연산량을 썼을 때 어떤 기대치가 나올지, 그럴만한 가치가 있는지. 기업 관점에서는 중요하다고 생각함. 그 내부 동작 과정을 설명하는 논문? 이라는 생각도 들었음. | 4.0 |
| 귤 | LLM을 기하학적으로 보는 관점이 낯설다! 일반적으로 모델의 제한된 크기 안에 많은 개념을 넣고싶으므로 superposition은 자연스럽게 발생할 수밖에 없을 것 같음. 그래서 이 중첩된 것을 어떻게 분리해서 해석할 수 있을지가 관건인거같다(by.SAE?). 처음에는 superposition이 적은게 좋은것일까 생각도 했는데, 이 경우 특정 feature가 오버피팅 될수도 있어서 마냥 줄이는거도 정답은 아닌듯 | 4.4 |
| 동까스 | 데이터는 어쩔 수 없이 한정되어 있으니 이러한 스케일링 방식의 연구들이 자주 나오는 것 같다. 앞으로 이런 연구들이 많이 나올듯! | 4.1 |
| 수면장애 | 왜 효준이가 다음주에 꼭 발표하고 싶어하는지 알겠다! 이제 LLM을 내놓는 빅테크들이 가용한 데이터가 사라지고, 자체수집한 신규데이터+기존 데이터를 최대한 잘 활용하는 방향으로 갈텐데 (+탄소 등 환경이슈로 큰 모델을 계속 돌리는 것도 부담이 될 것임) 그 관점에서 돋보이는 논문. Scaling Laws for Precision 랑 비슷하면서도 핀트가 달라서 재밌었다! | 4 |
| 이어폰 | LLM의 특성을 내부 표현에서 사용하고자 하는 논문들은 그 특성들이 weak superposition 관계임을 보여야 리뷰 때 덜 공격받는 걸 봐서 strong superposition에 대해서는 많이 생각해보지 못했던 것 같다. strong superposition 중심으로 본 논문같아 자세한 내용이 더 궁금하다 | 4.3 |
| 사과 | LLM이 학습을 거듭할수록 loss가 줄어드는 것은 당연한 현상이지만, 이걸 왜 그렇게 되는지 Dimension과 Superpositiond의 완전히 새로운 방법으로 접근한 것이 novelty가 좋다고 봄. 기존의 관점과 확연히 다른 관점이라 이 연구가 가지는 의미가 큰 것 같음. | 4.8 |
| 7일 | Plateau에서 외적으로 표현 변화가 보이지 않았던 이유가 이미 strong superposition 가정하에 새로운 feature를 계속 넣을 수 있었던걸까? 그리고 중간 layer 관점에서도 아무래도 feature dimension이 가장 높은 layer다보니 strong superposition이 가장 자유롭게 허용되는 공간인 듯. 다 연결이 되네! | 4.6 |
TL; DR
💡
Superposition은 Scaling law가 작동하게 한다!
저자: MIT
NeurIPS 2025 Best Paper Runner-up (2nd place)

Summary
Background (LLM, Neural model에서 아주아주아주아주 중요한 개념들!)
- Scaling law from OpenAI
- 한줄 요약: 모델, 데이터, 연산량이 커짐에 따라 loss가 일정하게 줄어드는 것이, 예측 가능하다!
- GPT-2는 0.7B 모델이지만, scaling law를 통해 다음 GPT-3은 175B로 아주 크게 확장함
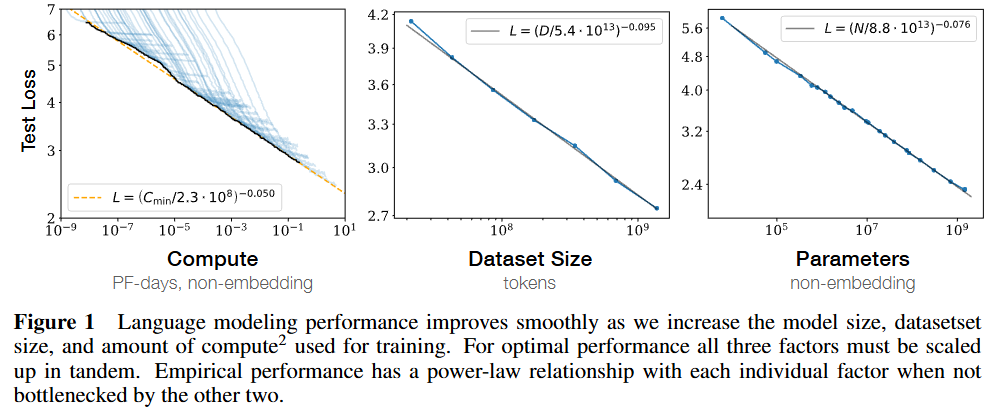
- 한줄 요약: 모델, 데이터, 연산량이 커짐에 따라 loss가 일정하게 줄어드는 것이, 예측 가능하다!
- Superposition from Anthropic
- 한줄 요약: m 차원 행렬에서 m보다 훨씬 많은 feature를 거의 orthogonal하게 나타낼 수 있다!
Motivation
- Scaling law는 성공적이지만, 왜 그렇게 되는지 명확히 설명되지 않음
- 임베딩과 관련이 될 수 있음에도, 이런 접근이 충분히 연구되지 않음
- 기존의 scaling law 연구들은 weak superposition상태를 가정하는데, 이건 실제 LLM 작동과 차이가 있음
- Research Qustion: How will superposition influence the loss scaling with model dimension?
- Superposition의 정도와 데이터 구조를 변화할 때, loss는 언제 power law를 따르는가?
- Power law를 따를 때, 그 지수는 무엇인가? = 몇제곱에 비례하는가?
- Superposition의 정도와 데이터 구조를 변화할 때, loss는 언제 power law를 따르는가?
Contribution
- Anthropic에서 한 것과 유사하게 토이 모델을 써서, superposition과 scaling law 사이의 관계를 밝힘
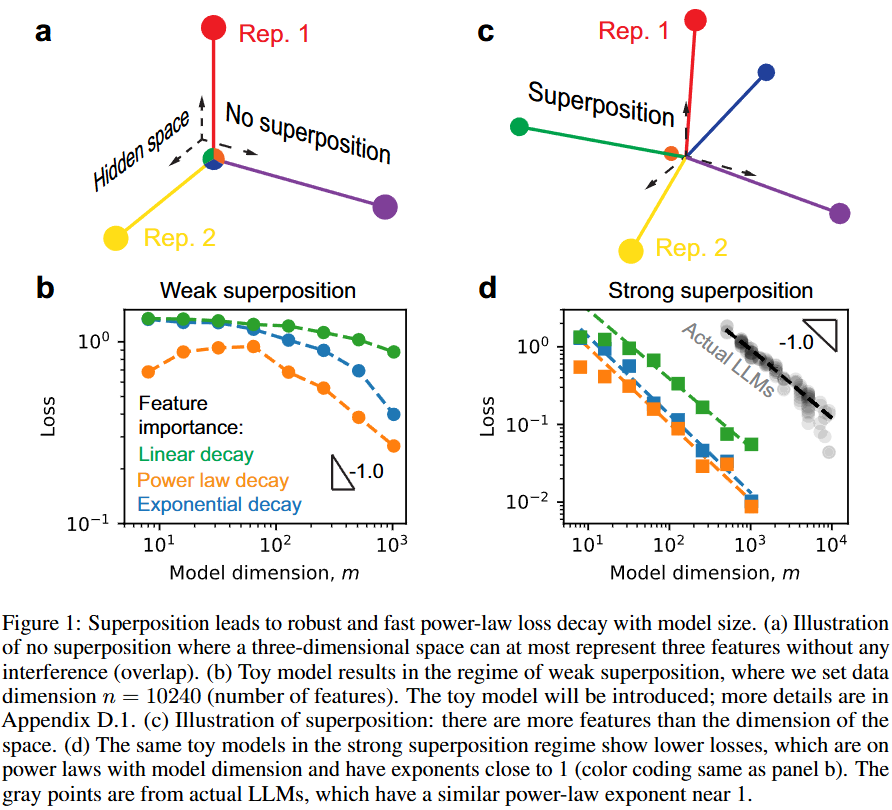
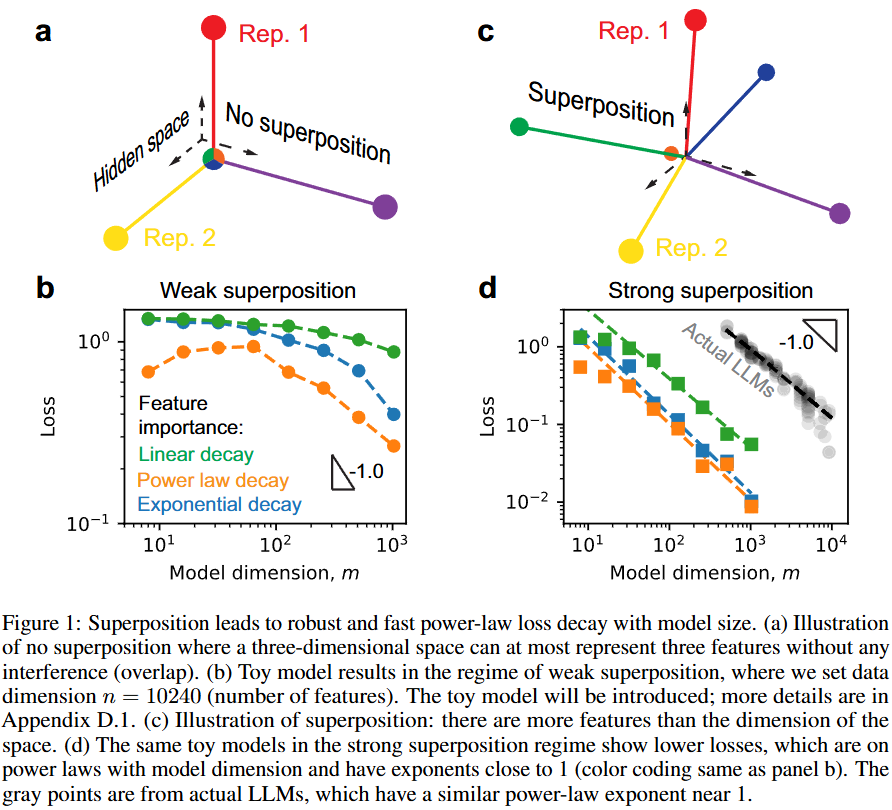
- Weak superposition(feature간 orthogonal, overlap 없음)에서는 Model dimension이 충분히 커야 loss가 일관되게 감소함
- Strong superposition(feature간 overlap 허용, 더 많은 feature 표현)에서는 일관되게 scaling law를 보임 (실제 LLM과 비슷)
Method
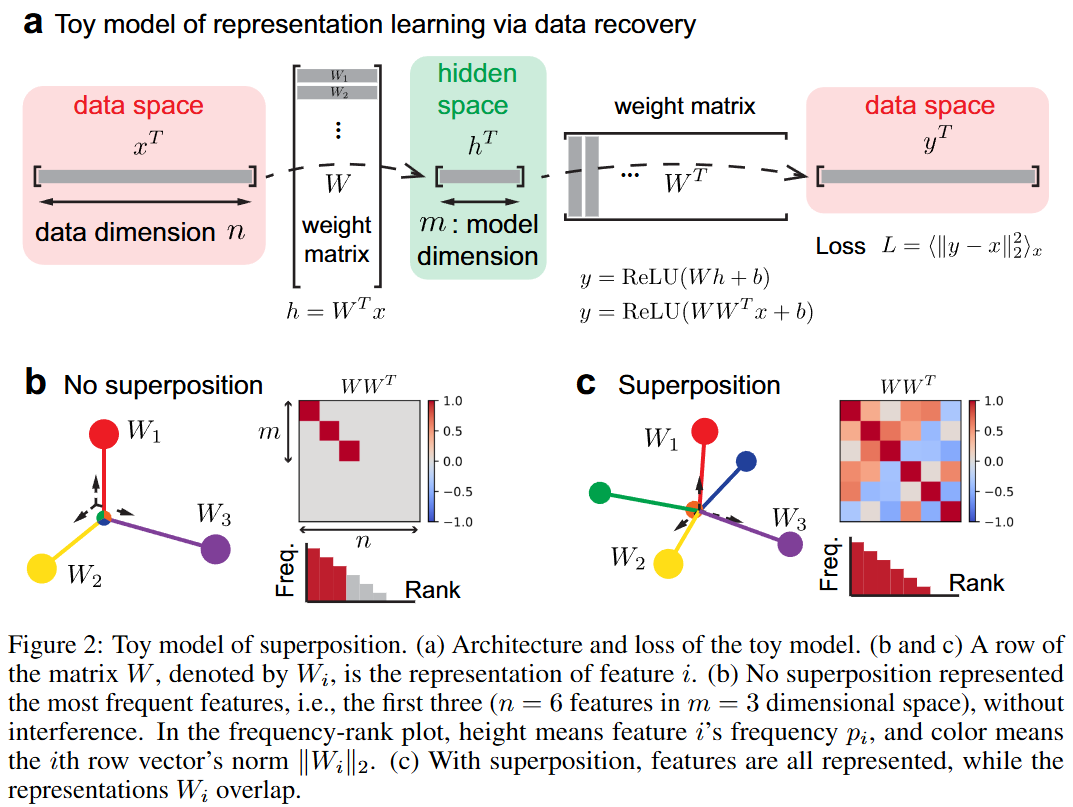
- 토이 모델로 실험
- 실험을 위해서, 모델의 차원보다 데이터의 feature 수가 많아야 함
- 각 feature들은 데이터 레벨에서 서로 다른 frequency를 가져야 함
- 으로 데이터 차원 n을 모델 차원 m에 꾸겨넣기 (n>>m)
- 이를 위해서 n차원 벡터를 랜덤하게 설정하고, 로 복구하는 학습을 진행함
벡터 설정
- i번째 feature가 발현될 확률을 로 정의하고, 발현됐을 때 강도를 0~2까지의 uniform distributrion으로 설정
- i가 커질수록 는 작아지도록 설계(데이터 분포 고려)
-
- 예컨대 흔한 개념은 가 클 것이고, 도메인 전문 지식은 가 낮음
- 중첩이 없을 때
- 가 m번째 row 까지는 orthogonal하고, 나머지는 0에 가까워질 것
- 중첩이 있을 때
- 가 non-zero row가 m보다 많을 것
- 비선형 함수 ReLU와 bias를 사용해 중첩이 더 잘 작동되도록 설정
- 이를 위해서 n차원 벡터를 랜덤하게 설정하고, 로 복구하는 학습을 진행함
- W training
-
- 는 learning rate, 는 weight decay
- 이면 greedy하게 i번째 feature를 감소시킴
- 이면 모든 가 1에 가까워짐 (모든 feature를 표현하려고 함)
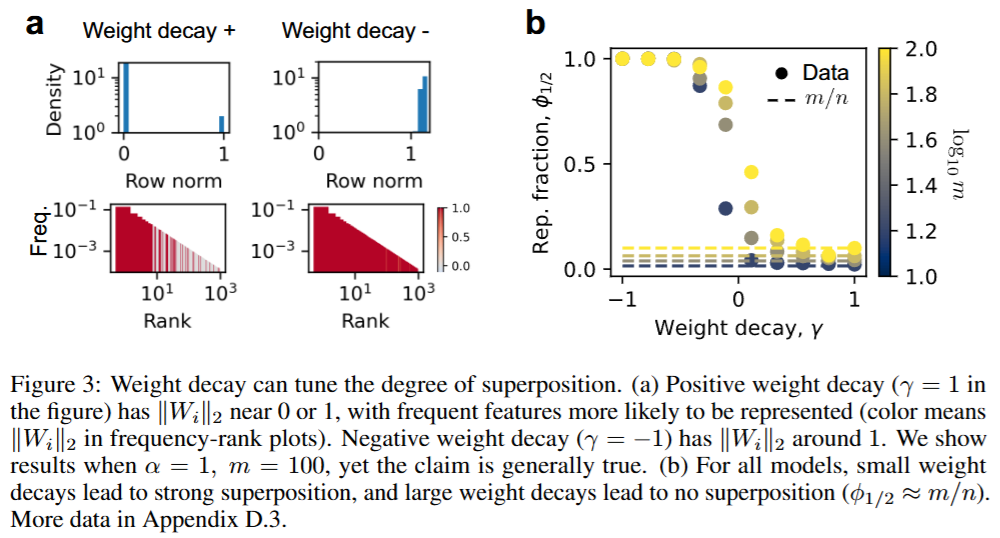
- W에서 표현된 feature의 비율을 다음과 같이 정의함
-
- norm이 1/2보다 크면 표현됐다고 가정
Experiments
Weak Superposition
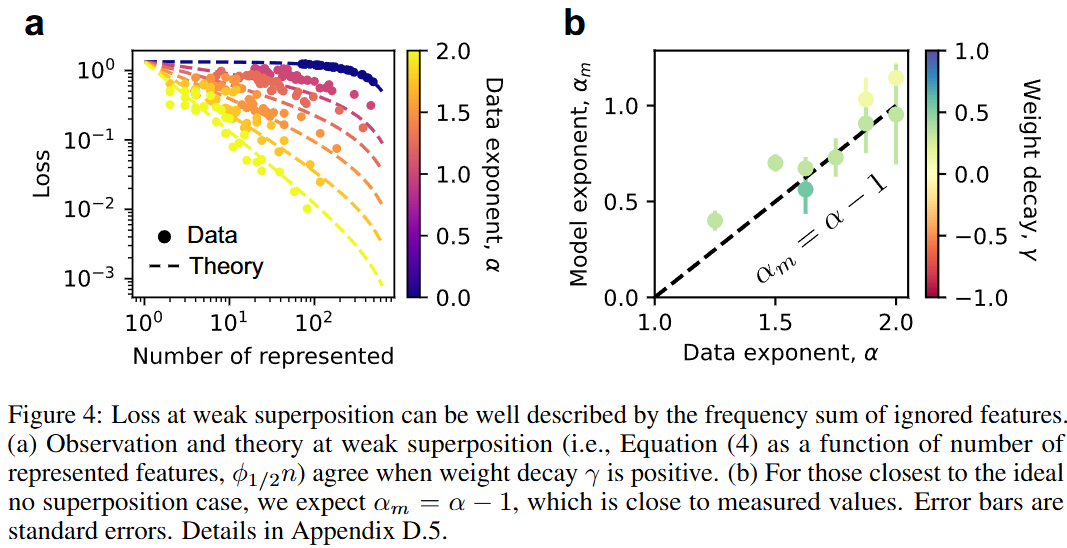
- 데이터 분포가 power law를 따르면, m+1번째 feature부터 출력은 다 0이 되고 그대로 loss로 나타남
- m번째 feature까지 orthogonal하게 표현하기 때문!
- 그럼 loss는 m+1~n번째 feature에 해당하고, 로 나타낼 수 있음
- 일 때, 모델 loss 은 의 power law가 될 것임()
- Power law in, power law out!
- 데이터 분포가 power law를 따르면, m+1번째 feature부터 출력은 다 0이 되고 그대로 loss로 나타남
Strong Superposition
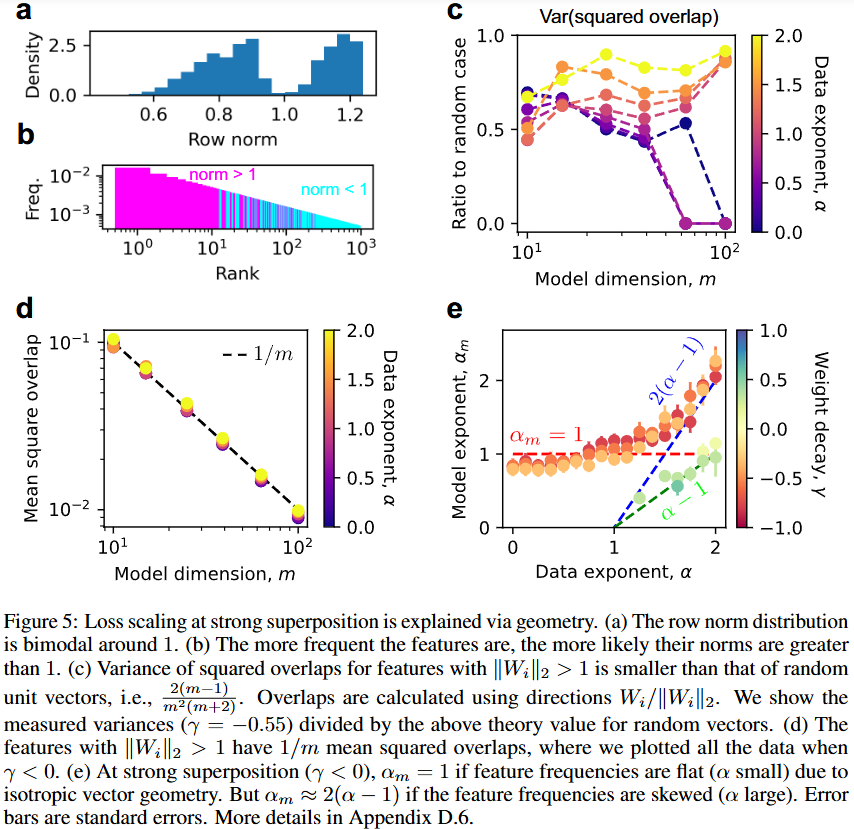
- a에서 row norm은 1보다 큰 애들과 1보다 작은 애들로 구분됨
- b에서 보면 중요한 개념일수록 norm이 큼
- 간단한 이론적 loss 계산
- m개의 모델 벡터들이 단위 구에 iid로 균일하게 분포되어있다고 가정
- loss는 벡터 사이의 overlap으로 측정됨
- overlap의 distribution은 평균 과 분산 을 가짐
- 즉 loss는 1/m scaling을 가짐
- 간섭을 상쇄하려면 max overlap을 줄여야 함
- v>m인 unit vector(표현해야하는 feature)
- overlap의 하한은 다음과 같이 표현됨
-
- v>>m이 일 때 는 으로 수렴
- 제곱 겹침의 평균은로 수렴
- overlap의 하한은 다음과 같이 표현됨
- v>m인 unit vector(표현해야하는 feature)
- data가 고루 분포되어 있으면 scaling을 가짐
- data 분포가 비등방성에 가까우면(), loss는 의 power law를 갖게 됨
- a에서 row norm은 1보다 큰 애들과 1보다 작은 애들로 구분됨
LLM
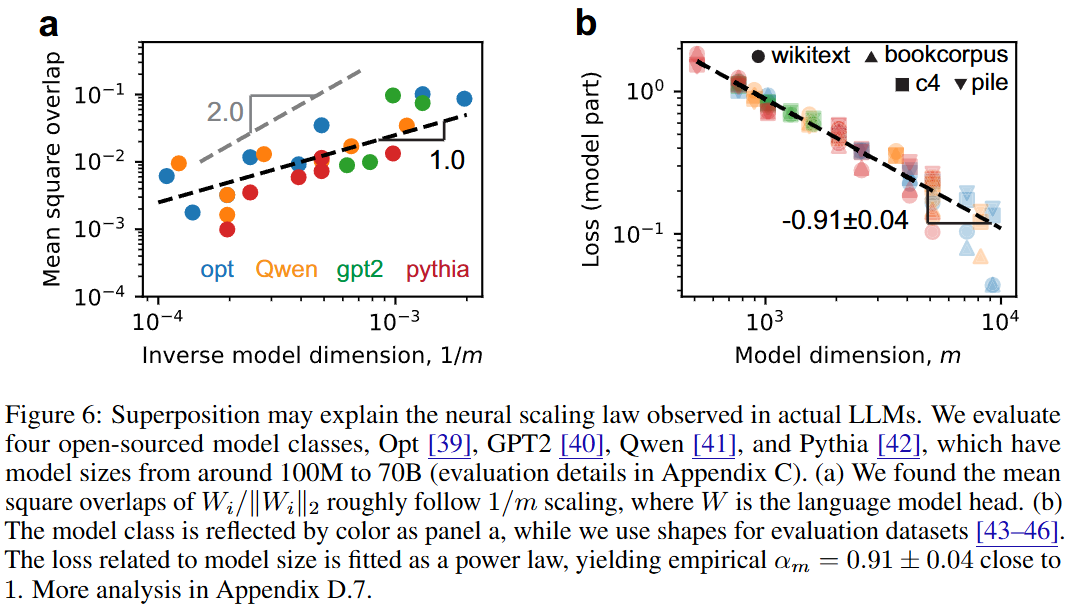
- data dimension n을 vocab size로 두고, 출력 layer를 로 둠
- 그림 a에서 강한 중첩에서와 마찬가지로 LLM은 1/m scaling을 따름
- → LLM은 강한 중첩에서 작동한다!
- 그리고 Cross Entropy Loss도 max overlap(~1/m)과 비슷하게 scaling됨 (그림 b)