What Happens During the Loss Plateau? Understanding Abrupt Learning in Transformers
Review
| 닉네임 | 한줄평 | 별점 (0/5) |
|---|---|---|
| 마스킹테이프 | abrupt learning 이라는 단어를 처음 봄. 손실 하락이 정체되다가 갑자기 크게 일어나는 것은 다른 태스크 학습 때도 몇번 경험할 수 있었지만, 그 이유를 파악해보고 파헤쳐보는 연구는 처음 보는 것 같음. 반복적 토큰이 왜 발생하는지, attention map을 어떻게 탐색하고 개선하는지, 그리고 그것을 확인한 방법을 참고할만해보임. | 4.0 |
| 귤 | Mamba 같은 다른 아키텍처에서도 loss plateau와 같은 현상이 나타나는지 궁금함. Transformer의 plateau가 attention이 올바른 토큰 정렬을 찾아가는 과정에서 생기는 병목이라면, attention을 사용하지 않는 모델에서는 plateau가 더 약하게 나타나거나 아예 나타나지 않을 가능성도 있을듯 | 3.7 |
| 동까스 | loss plateau가 발생한다는 사실을 몰랐는데 plateau에서 학습 종료를 너무 일찍 해버리면 plateau를 뚫기 직전에 학습을 멈출 수 있겠다(다이아를 앞에 두고 광물캐기 멈추는 것처럼)라는 생각과 그럼 학습 종료 타이밍을 언제로 잡아야되지 라는 생각이 듦 | 3.7 |
| 수면장애 | 석사 1학기때 코드 연습하다가 실제로 repetition bias, loss plateau를 경험한 적이 있는데, 논문에서 오피셜하게 언급하니 신기하고 재밌게 읽었음 loss plateau는 Transformer 구조의 문제일 가능성이 크다!! 근 2년 이내로 추세가 mamba로 옮겨가겠구나 ! | 4 |
| 이어폰 | 훈련 초기 단계에서 훈련 데이터의 영향이 크다는 이번주 다른 스터디 논문과 연결지어 생각하게 된다 (training data temporal dependence 논문). 현상을 밝혀내는 데 집중하는데 현상들의 이유가 더 궁금해진다 | 3.7 |
| 사과 | Transformer 기반 모델들을 실험하면서 갑자기 loss가 증가하여 이상하다고 생각한 적이 많았는데, loss plateau임을 알 수 있었던 논문. 앞으로의 실험에서 loss 탐색 시점을 조절할 수 있을듯. | 4.7 |
| 7일 | Plateau 구간에서 겉으로 보이지 않는 representation 변화를 직관적으로 실험한 부분이 인상적임. MWS 태스크의 존재를 알게됐는데, 특정 task 성능이 갑자기 무너지기 직전의 signal을 탐지하도록 활용가능해보임. Catastrophic forgetting도 줄일 수 있지 않을까? | 4.4 |
TL; DR
💡
Transformer 모델 훈련 시 손실하락이 초기단계에서 정체되다가 갑자기 크게 일어나는 abrupt learning 현상 탐구
Summary
Motivation
- Transformers를 수학 혹은 알고리즘 태스크에 훈련할 때 보이는 abrupt learning (갑작스러운 학습) 현상
- : 모델의 성능이 오랫동안 정체되었다가 갑자기 급격하게 향상되는 현상
- 본 논문은 훈련 시 이러한 현상의 보편적인 특성과 기본적 메커니즘을 밝히고자 함
Contribution
소형 Transformers를 간단한 알고리즘 태스크로 훈련하여 abrupt learning과 관련된 여러 현상 탐구하고자 함
- 사용 태스크: moving-window-sum (MWS)
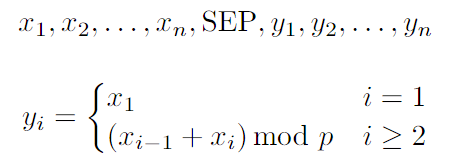
window size: 2 - 시퀀스가 주어지면, 이후 을 출력해야 함
- 는 0, 1, 2, …, 17 중 하나의 숫자
- 은 그대로, 는 를 (=17)로 나눈 나머지, 은 , …
- ⇒ ground truth가 잘 알려져 있는 태스크로서 모델의 훈련 진행 정도를 정확히 측정할 수 있음
- 시퀀스가 주어지면, 이후 을 출력해야 함
- 모델 아키텍쳐: 1-layer, 1-head Transformer
- 이 구조로도 주어진 태스크 완벽히 수행 가능
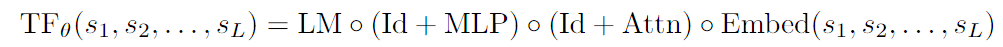
- : 입력 토큰 시퀀스
- : 2-layer NN
- : residual connection
- : linear layer, mapping hidden state to logits
- greedy decoding 사용
- ⇒ 작은 모델을 사용하여 모델 내부 메커니즘을 쉽게 분석하고 해석할 수 있음
- 이 구조로도 주어진 태스크 완벽히 수행 가능
- 훈련
- 의 전체 시퀀스에 대해 next-token-prediction cross-entropy loss 손실 최소화하도록 훈련
- 256개 훈련 샘플로 1 에폭 훈련
- 정확도 측정: output 부분인 의 개 토큰에 대한 예측 정확도 평균
- 의 전체 시퀀스에 대해 next-token-prediction cross-entropy loss 손실 최소화하도록 훈련
- abrupt learning
- 훈련 중 training loss가 sub-optimal 값에서 상당히 많은 step동안 유지되다가 급격한 정확도 증가와 손실 하락
- ⇒ optimal solution을 갑자기 학습하는 abrupt learning 현상 확인
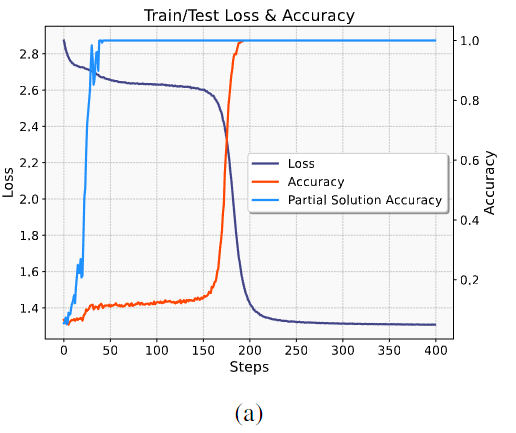
loss, accuracy
- attention map
- 실험 태스크에 대해서 최적의 attention pattern은 각 output token 가 자신을 계산하는데 관련있는 input token만을 attend하는 것
- 은 에 attend, 는 에 attend, …
- attention progress measure (APM) 사용해 attention pattern 변화 관찰
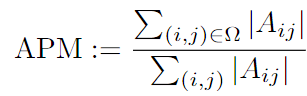
- : -th output token 계산할 때 -th token에 할당되는 attention score
- : 최적 attention map의 position pair set
- → 훈련 중 APM이 0부터 0.8 정도까지 단조 증가하며, 손실/정확도보다 완만한 변화 곡선 보임
- step 150 쯤에서 급격한 손실 하락 있는데, 그 이전부터 APM은 이미 상당히 증가함
- ⇒ 손실 하락은 급격하지만 그 이전부터 attention pattern learning은 점진적으로 진행됨

attention progress measure
- 실험 태스크에 대해서 최적의 attention pattern은 각 output token 가 자신을 계산하는데 관련있는 input token만을 attend하는 것
- 사용 태스크: moving-window-sum (MWS)
Transformers 훈련의 초기 정체기 (early loss plateau period) 동안 모델은 종종
partial solution을 학습함- e.g., moving-window-sum 태스크에서 첫번째 입력 토큰 를 그대로 출력하면 되는 예측은 빠르게 학습하지만, 전체 손실은 여전히 높으며 이후 토큰에 대한 정확도 떨어짐
partial solution accuracy - 첫번째 출력 토큰 예측 정확도인 partial solution accuracy가 빠르게 증가
- 반면 전체 loss는 많은 훈련 스텝 이후 하락
- ⇒ 초기 정체기 동안 전체 loss는 크게 줄지 않지만 모델의 partial solution 학습 진행됨
- e.g., moving-window-sum 태스크에서 첫번째 입력 토큰 를 그대로 출력하면 되는 예측은 빠르게 학습하지만, 전체 손실은 여전히 높으며 이후 토큰에 대한 정확도 떨어짐
정체기동안 모델이 반복적 토큰을 출력하는 경향인
repetition bias가 강하게 나타남- repetition frequency: repetition bias 정량화 지표
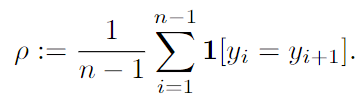
다음 토큰과 동일한 토큰 출력한 빈도수
- 결과
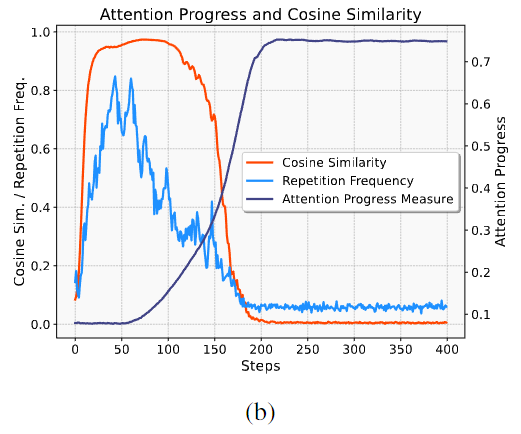
repetition frequency - repetition frequency가 훈련 시작 시 작았다가 처음 50 스텝동안 0.8까지 상승
- ⇒ 초기 정체기의 강한 repetition bias 확인
- repetition frequency: repetition bias 정량화 지표
output repetition bias는 다른 토큰에 대한 hidden representation이 거의 동등하게 되는
representation collapse를 동반함- 출력 위치 에서 hidden representation 간 pairwise cosine similarity:
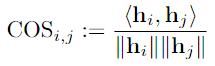
- : th 토큰의 hidden representation (logit 변환 직전)
- cosine similarity가 훈련 초기 단계에서 급격히 증가
cosine similarity - ⇒ partial solution에서 정확히 예측되는 첫번째 출력 위치를 제외하고는, 훈련 초기 단계에서 여러 출력 위치의 hidden representation이 거의 동등해짐
- 출력 위치 에서 hidden representation 간 pairwise cosine similarity:
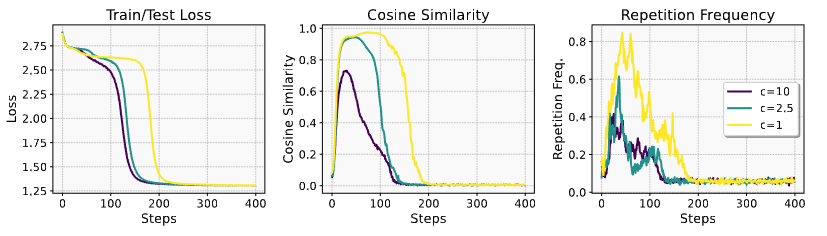
attention map learning이 repetition, representation collapse과 loss plateau 형성에도 중요한 역할 함을 보임- 최적의 어텐션 맵을 향해(또는 반대로) 편향시켜 반복, 표현 붕괴, 손실 정체가 감소(또는 증폭)되는지 확인
- 에 대해 attention mask 를 로 설정: 나머지 경우
- 기존 attention을 이 attention mask와 hadamard 곱 함으로써 변형하여 훈련과 추론에 사용
- 이면 optimal attention map 방향으로 편향시키고, 이면 반대 방향으로 편향시키는 것
- : hidden state 간 평균 코사인 유사도와 repetition의 감소, 보다 빨리 수렴함
- : representation collapse 상태에 모델이 보다 오래 머물고 보다 이후에 수렴, repetition frequency 또한 정체기동안 크게 유지됨
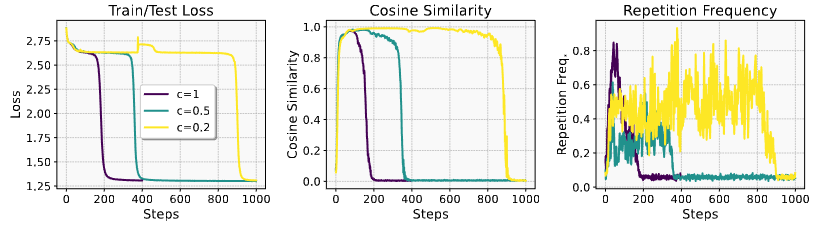
- ⇒ attention map learning이 repetition, representation collapse, loss plateau 형성에 중요한 역할 함
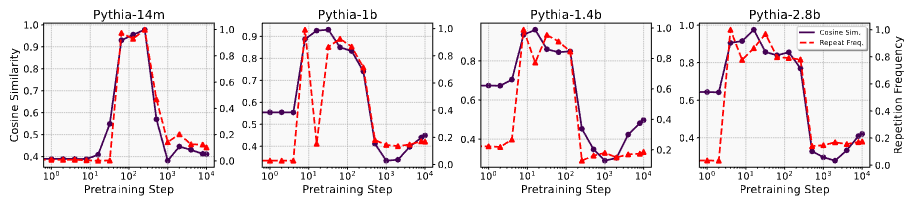
소형 Transformer만이 아니라 실제 LLM의 사전훈련 초기 단계에서도 이러한 repetition bias, representation collapse가 나타나는지 확인
- LLM: Pythia, OLMo-2 (open-source)
- task: ARC-Easy 테스트 데이터에서 랜덤 선정한 100개 질문 (초등학교 수준 과학 객관식 질문)
- 각 질문에 대해 8개 토큰을 생성하게 하고 hidden representation의 pair-wise cosine similarity 계산
- 14M, 1B, 1.4B, 2.8B Pythia 모델의 초기 훈련 단계에서 출력 시퀀스의 repetition bias 발견
- 초기화 시 평균 코사인 유사도가 비교적 낮으나 (0.4~0.65), 모든 사이즈의 모델에 대해 몇 스텝만 학습해도 0.9 이상으로 급격히 증가
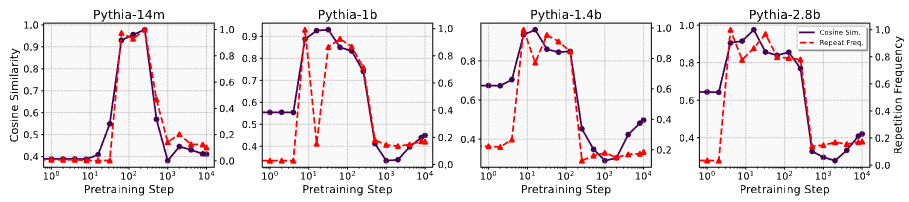
- OLMo-2 7B 모델에서도 Pythia와 유사한 representation collapse 현상 관찰
- 150스텝의 초기 훈련 단계에서 representation 평균 코사인 유사도는 0.93
- 600스텝에서는 0.43으로 감소
- ⇒ repetition bias, representation collapse가 LLM 초기 사전훈련 단계에서 실제로 발생하는 현상임
Conclusion
- Transformer 훈련의 초기단계에서 repetition bias와 representation collapse가 발생하며, 이는 loss plateau와 밀접한 관련이 있음
- loss plateau가 최적의 attention map 탐색하는 과정일 가능성 있음
- 본 논문의 발견에 이어 representation collapse와 같은 현상이나, attention map의 느린 learning의 원인에 대한 향후 연구가 유망