Advancing Expert Specialization for Better MoE
Review
| 닉네임 | 한줄평 | 별점 (0/5) |
|---|---|---|
| 찰나 | 이 논문을 보고 처음 들었던 생각은, MoE, Agent 등 개념들을 사실 차이를 나보고 설명하라고 하면 명확하게 못할 것 같다는 생각이었음. 논문과는 좀 무관한 이야기긴 하지만, 그런 생각이 들게 하고 공부하게 만들어서 나에게는 좋은 논문이었음. MoE 자체는 꽤 오래된 방법이지만, 방법 자체가 실제 사례와 굉장히 관련 깊다고 생각하고, 성능 개선 방향 및 관련 연구로 참조하기 좋은 연구라고 생각함. | 4.3 |
| 와사비꽃게랑 | 하나의 문제를 여러 관점 및 역할으로 나누어 처리하자~ 라는 개념이 전체적으로 Attention head, MoE expert, multi-agent 등 여러분야에서 유사하다는 느낌이 들음. 단순히 요소들의 개수는 늘리는게 아니라 각각의 역할을 분리되게끔 명확하게 지정해주는게 중요한듯 | 4 |
| 메가커피 | MoE의 본질?을 지키기 위한 연구. 손실함수에 두 가지 항(orthogonality loss, variance loss)을 추가했음에도 불구하고 실험 결과를 보면 상당히 성능이 오른 걸 볼 수 있는데 motivation부터 결과까지 깔끔한 논문인 것 같다. | 4.2 |
| 요리괴물 | 논문이 매우 어렵다... 전반적으로 두 loss를 제안하는데 모든 태스크에 대해 각 전문가가 구별된 표현을 가지도록 하는것이 도움이 되는지 염려됨. Multilingual이나 의미 유사도고려하는 태스크 같은 경우...? | 4.2 |
| 새우깡 | 새로운 훈련목표 도입한 것도 의미있지만, 기존 훈련목표의 장점을 방해하지 않으면서 성능에 긍정적 영향 미친다는 걸 이론적으로도 실험 결과로도 잘 입증했다. 방법론 제안만 하고 끝나는 게 아니라 특히나 설득까지 공들여 한 논문 | 4 |
| 안성재 | MoE의 한계점을 정말 technical하게 잘 풀어낸 것 같네요. 이정도 테크니션이면 창의적이지 않아도 아무나 못하는 연구가 가능해서 그것대로 차별점이 드러나는 것 같아요. 생존입니다. | 4 |
| 스타벅스 | MoE의 취약점을 체계적이고 수학적으로 분석한 연구입니다. 단순히 요소의 개수 늘리고 크기만 늘릴게 아니라 체계적으로 표현 분석이 중요함을 알 수 있음. | 4.5 |
| 고구마맛도리 | 기존 MoE의 한계점을 명확하게 정의하고, 이를 objective로 잘 구현해낸, 깔끔하고 군더더기 없는 좋은 연구! 특히 MoE 아키텍처를 건들이지 않고도 좋은 성능을 뽑아낸 게, 이 논문의 최고 강점이라고 생각함니다 | 4.2 |
TL; DR
💡
Mixture-of-Experts 훈련 손실함수에는 expert 간 routing 효율성 위한 objective term 있음
- 그러나 이는 각 expert의 전문성 특화를 방해하는 부작용 있음
- ⇒ routing 효율성 목표를 방해하지 않으면서 expert 전문화에 도움되는 objective를 추가하자
Summary

1. Introduction
Background
- LLM 규모 증가에 따라 추론 비용이 급격히 증가되므로 실용적인 배포와 효율성이 저해됨
- Mixture-of-Experts (MoE) 아키텍처는 입력에 따라 하위 전문가(expert) 집합만을 활성화하여 이 문제를 완화
MoE 추가 설명
- 특정 레이어 또는 연산(e.g., linear layer, MLP, attention projection)을 여러 “expert” subnetwork로 분할
- 각 expert subnetwork가 독립적으로 연산 수행하고, 연산 결과를 종합하여 MoE 레이어의 최종 출력 생성
- 주어진 입력에 대해 모든 전문가를 사용할 수도 있고 (dense experts), 일부 top-k experts로 구성된 subset만 사용할 수도 있음 (sparse experts)
- 본 논문에서는 sparse 설정 사용
- 특정 레이어 또는 연산(e.g., linear layer, MLP, attention projection)을 여러 “expert” subnetwork로 분할
- 계산 비용이 모델 크기에 비례적으로 증가하지 않아 더 큰 사이즈의 모델 사용 가능
- 일반적으로 MoE 시스템 사전훈련 시 파라미터 활용 극대화를 위해 토큰이 전문가에 보다 균등하게 분배되도록 하는 load balancing objective 사용
Motivation
- load balancing 목표는 사전훈련동안 활성화되지 않는 전문가를 방지하는 데 효과적이나, 다운스트림 태스크 위한 사후훈련에서 모델의 효과적인 적응을 막음
- 입력과 상관없이 균일하게 routing하도록 유도하여 전문가 간 토큰 분포가 중복되는 현상이 많이 발생
- 이러한 중복은 전문가 representation이 서로 비슷해지도록 하여 각 전문가의 기능 전문화를 방해
- 전문화 부족으로 인해 모델을 다운스트림 태스크에 파인튜닝 시 성능 저하
- load balancing 목표가 expert와 routing 관점 각각에서 갖는 문제
- expert 관점에서 문제: 각 전문가의 고유한 행동 발달 방해
- router 관점에서 문제: 전문가의 전문화가 약화될수록 전문가 간 차이가 감소 → token-to-expert 할당이 점점 균일해짐
- → 전문화 감소와 라우팅 균일화는 점점 서로를 강화하며, 이는 전문가 표현과 라우팅 품질을 저하시킴
- ⇒ MoE 훈련의 auxiliary loss (보조 손실)에서 기인하는 uniformity constraint에서 전문가 전문화를 분리해야 함
Contribution

- auxiliary loss의 load balancing 유지하면서, 전문가 전문화와 라우팅 다양화를 촉진하는 프레임워크 제안: 두가지 상호보완적 objective 도입
objective(1)expert specialization: 각 전문가가 서로 다른 토큰 처리에 특화되도록 하여, 전문가 간 고유한 표현 개발 촉진
objective(2)routing diversification: 라우팅 분산을 강화하여 차별화된 라우팅 결정을 유도함으로써 token-to-expert 할당의 정밀성 향상
- ⇒ 이러한 목표를 공동 최적화하여 MoE 훈련 시 모델 성능과 라우팅 효율성 간 trade-off 완화
- 제안 프레임워크 도입함으로써 다음을 달성
- enhanced expert-routing synergy: 공동 목표로 전문가 중복을 최대 45% 감소, 라우팅 점수 분산을 150% 증가 → 더 명확한 전문가 전문화와 차별화된 전문가 라우팅 달성
- stable load balancing: 새로운 objective 도입함에도 모든 모델에서 RMSE 8.63 미만으로 베이스라인과 동등한 load-balancing 성능 달성
- improved downstream performance: MoE 아키텍처 수정 없이 11개 벤치마크에서 23.79%의 상대적 성능 향상을 달성, 92.42% 태스크에서 모든 베이스라인 능가
2. Motivation
Preliminaries of MoE
- MoE layer (notations)
- experts
- input token sequence,
- routing score matrix, : 각 토큰에 대해 처리할 상위 k개 expert를 할당하기 위한 score matrix
- : 번째 토큰에 대한 번째 expert의 routing weight
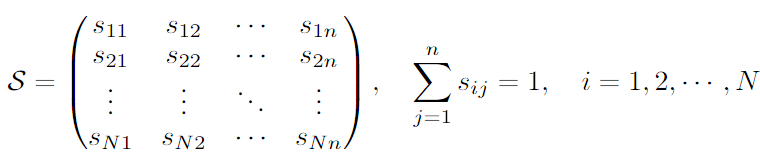
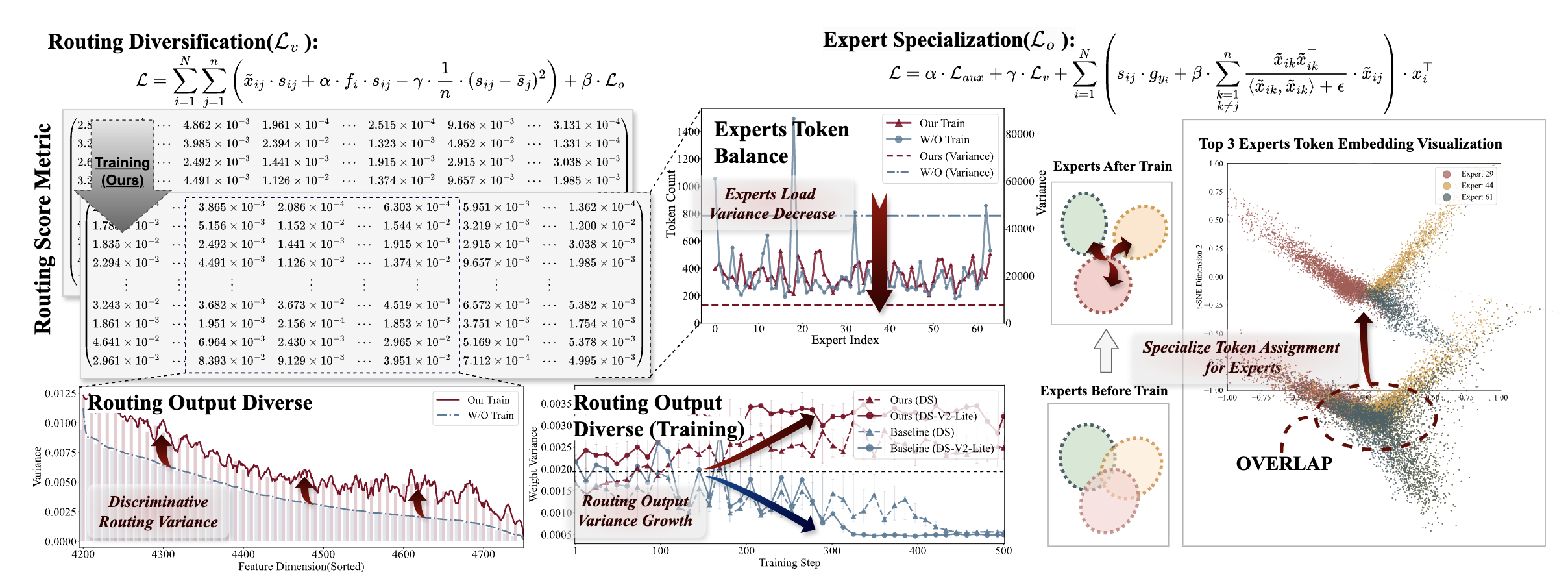
- : 각 expert에 할당된 토큰의 비율
- : 번째 expert에 할당된 토큰의 수
- total loss function,
- main task loss, : MoE layer의 output으로부터 계산되는 손실
- auxiliary loss,
- : auxiliary loss 도입 계수
- : 번째 expert에 대한 total routing score
- 즉, 번째 expert에 할당된 모든 토큰의 routing weight 합산
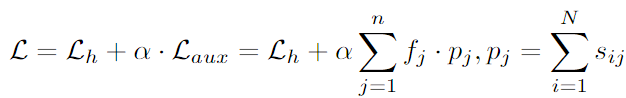
auxiliary loss, L_aux : 각 expert에 할당되는 토큰 수(f_j)가 균등해야 최소화됨
→ load-balancing objective term (각 전문가에 비슷한 수의 토큰이 할당되도록 함)
Observations
obs(1)expert overlap: auxiliary loss 도입이 전문가 간 토큰 분포를 균등하게 만들며, 이는 각 전문가 간 구별성을 감소시킴- auxiliary loss는 expert의 파라미터 와 독립적 → 번째 expert의 gradient는 다음과 같음:
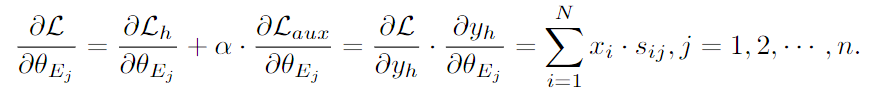
- : MoE layer output
- → total loss로 인한 expert의 파라미터에 흘러들어가는 gradient에는, 입력 토큰 들이 관여함
- load-balancing routing을 강제하는 auxiliary loss는 훈련 과정에서 전문가에 걸친 균등한 토큰 분포를 유도함
- → 입력 토큰들이 관련 적은 expert에 할당될 수 있으며, 이는 의도치 않은 전문가에 대한 gradient flow를 이끎
- auxiliary loss는 expert의 파라미터 와 독립적 → 번째 expert의 gradient는 다음과 같음:
obs(2)routing uniformity: 훈련 진행에 따라 routing output이 점차 균등(uniform)해지며, expert weight 분포가 균일해짐- routing의 output은 score matrix → routing parameter 과 관련한 gradient는 다음과 같음:
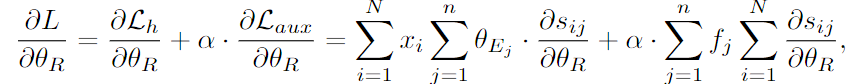
- : 토큰 에 대한 expert 의 output
- : expert 가 선택되는 빈도수
- → routing 관련 gradient는 주로 expert output과 expert에 걸친 토큰 분포에 영향받음
- 는 의 uniformity를 지향하는, 균형잡힌 토큰 할당을 독려하는 손실이지만 가 미분 불가능하여 직접 최적화하기 어려움
- 이에 미분 가능하며 와 양의 상관관계 갖는 (expert 의 total routing score) 사용하여 routing network의 gradient를 계산
- → 의 최적화는 의 uniformity를 촉진하며, 이는 또한 의 uniformity를 이끎
- ⇒
obs(1)에서 본 것과 같이, 부정확한 전문가에 토큰 할당하는 것은 전문가 간 gradient가 중복되도록 하며, 이는 (expert output) 간 유사도를 증가시킴
- routing의 output은 score matrix → routing parameter 과 관련한 gradient는 다음과 같음:
obs(3)expert-routing interaction:obs(1)은 전문가 특화,obs(2)은 routing uniformity 관련 관찰이었음 → 앞서 관찰한 현상들이 훈련 중 상호작용하여 모델의 성능 하락 이끎obs(1)에서 관찰한 전문가 측면 방해는 모호한 전문화 낳음- 이로 인해 토큰 분포가 균일해져 전문가 구별을 더욱 감소시키는 gradient 유발
- 전문가 유사성은 다시 routing에 영향 미침 (
obs(2))- 전문가 간 output이 점차 유사해지면서, routing network는 전문가 간 차별화 신호를 식별하기 어려워짐
- 이로써 점차 랜덤하게 top-k expert를 선택하게 하고, 토큰과 최적의 전문가가 정렬되지 못하게 함
3. Method
- ⇒ 전문가 간 중복과 routing 균등화를 완화하는, loss function 설계
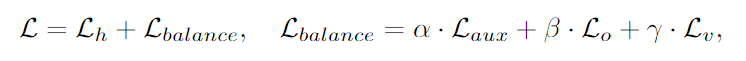
- : 기존 auxiliary loss
- : 새롭게 도입된 orthogonality loss와 variance loss
- : coefficients
Implementations of losses and
- expert specialization: orthogonalization objective 가 전문가 간 독립적인 표현 개발 촉진
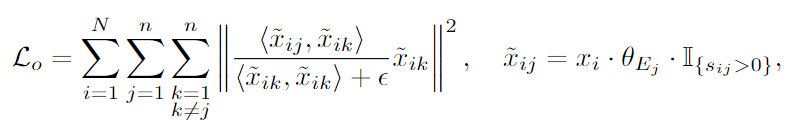
- : top-k routing 이후 토큰 에 대한 expert 의 output
- → 입력 토큰에 대한 각 expert의 output 간 projection 합산이 최소화되도록 함 (orthogornalize)
- 이로써 각 전문가가 서로 구별된 표현 갖도록 함
- routing diversification: variance-based loss 가 보다 다양한 routing 결정과 전문가 전문화를 독려
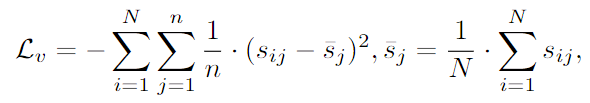
- : 데이터 배치에 걸친 expert 의 평균 routing score
- → routing score의 분산을 최대화하여, token-to-expert 할당이 균등하지 않도록 함
Compatibility of multi-objective optimization
- 전문가와 라우팅 관점에서 두 손실이 호환 가능함을 보임
- expert perspective
- auxiliary loss 와 variance loss 가 expert 파라미터 에 직접 기여하지 않음 → 전문가 파라미터에 대한 전체 손실의 gradient에는 태스크 손실 와 orthogonality loss 만 관여:
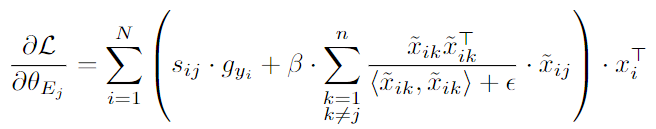
- : 모델 output에 대한 태스크 손실의 gradient
- → routing score 와 expert representation 에 영향 받음
- ⇒ 훈련 진행됨에 따라 expert weight의 분산이 증가하고, gradient는 각 토큰에 대해 다른 방향을 더욱 선호하도록 유도함
- auxiliary loss 와 variance loss 가 expert 파라미터 에 직접 기여하지 않음 → 전문가 파라미터에 대한 전체 손실의 gradient에는 태스크 손실 와 orthogonality loss 만 관여:
- routing perspecitve
- routing 파라미터 의 gradient에 가 직접 기여하지 않음 → 라우팅 파라미터에 대한 전체 손실의 gradient는 expert representation , expert load , routing weights 에 영향 받음:
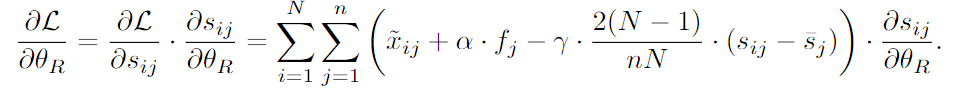
- → 훈련 진행됨에 따라 expert load가 균형 잡히고 routing weight 분산 증가
- 전문가 표현 orthogalize가 routing gradient의 직교화를 낳고 routing weight 분산을 증가시킴
- → 훈련 진행됨에 따라 expert load가 균형 잡히고 routing weight 분산 증가
- routing 파라미터 의 gradient에 가 직접 기여하지 않음 → 라우팅 파라미터에 대한 전체 손실의 gradient는 expert representation , expert load , routing weights 에 영향 받음:
- ⇒ expert parameter 는 의 gradient에 대해서만 영향 받고, routing parameter 은 모두에 영향받지만 두 loss의 목표가 충돌하지 않음 (전문가 표현 직교화와 라우팅 점수 다양화)
- 두 목표를 충돌 없이 공동 최적화할 수 있음
- expert perspective
4. Experiments
Experimental Setup
- datasets
- 훈련: Numina, GLUE, FLAN collection의 traning set
- 테스트
- math: GSM8K, MATH500, Numina
- multi-domain tasks: MMLU, MMLU-pro, BBH, GLUE, LiveBench, GPQA
- code generation: HumanEval, MBPP
- baselines (MoE training strategies)
- Aux Loss, GShard, ST-MoE, Loss-Free Balancing
- metrics
- accuracy
- expert load balancing (MaxVioglobal)
- clustering quality (Silhouette Coefficient)
- expert specialization (Expert Overlap)
- routing stability (Routing Variance)
- setup
- 3 에폭으로 훈련 (~550 steps)
- LoRA 기반 파인튜닝 (router layer, expert layer 모두에 LoRA 모듈 사용하여 공동 최적화 함)
Performance in Downstream Tasks

- 제안 방식이 전문가 전문화 유도하여 다운스트림 태스크에서 효과적으로 향상된 성능 보임
- ⇒ expert orthogonality와 routing output diversification이 다운스트림 태스크 성능에 긍정적 영향 미치는지 확인
Load Balancing

RMSE: 두 curve 간 유사도 차이 지표
- 만 사용하는
only aux와w/o lv( 만 사용),w/o lo( 만 사용) 간 load balancing 성능 추세가 거의 동일- 성능 커브 간 차이 지표인 RMSE 또한 0.03 미만이어서 상당히 유사
- ⇒ 가 의 load balancing에 영향 미치지 않음을 보임
Behaviors of Experts and Routing

- 처음 두개 그래프는 전문가 직교성, 마지막 그래프는 라우팅 출력의 다양성 나타냄
- 처음 두 그래프 → 가 전문가 직교성을 직접 촉진하며, 도 이에 기여함
- 마지막 그래프 → 가 라우팅 출력 다양성을 직접 향상하며, 도 이에 기여함
- ⇒ 가 전문가 직교성, 라우팅 점수 다양화를 공동 촉진할 수 있음을 보임
Ablation among Losses

- 의 결합이 다운스트림 태스크에서 모델 성능을 상당히 향상시킴
- 또한 각 손실이 개별적으로 도입될 때도 성능 개선 보임
- ⇒ 다운스트림 태스크에서 가 모두 모델 성능을 개선하며, 이들의 결합이 서로의 효과를 증진시키는 시너지 효과 냄을 보임