An Analysis for Reasoning Bias of Language Models with Small Initialization
Review
| 닉네임 | 한줄평 | 별점 (0/5) |
|---|---|---|
| 맹구 | memory와 reasoning은 다른 것이라고 시작하는 것 같음. 이번주 다른 논문에서 결국 LLM은 memory 기반 추론을 하는 것이다 느낌의 결론이 나왔는데, 이 논문은 더 디테일하게 확인해보려고 한 것 같다. LLM도 결국 Transformer니까, 이런 실험도 가능하구나 라는 생각을 하게 되었음. 꼭 큰 모델의 결과와 과정에 집착할 필요는 없구나 라는 생각이 들기도 함! | 4.2 |
| 계란초밥 | reasoning bias를 공론화(?)하고, 이를 위해 reasoning과 memory를 명시적으로 구분 및 분석한 논문! 구분 기준이 명확하고, 실험 설계도 개연적이고 논리적이며, 임베딩단에서 보이는 경향도 잘 표현했다. | 4.3 |
| 국밥 | LLM이 추론을 하는지 암기를 하는지는 데이터나 아키텍쳐만의 문제가 아니라는 것을 실험적으로 잘 풀어낸거같다. 임베딩 분리 실험도 직관적이라 좋다. Query마다 다른 KG가 주어지면..? 이건 암기보다는 구조적인 일반화가 유리해보이는데 small init이 맞을 듯 | 4.4 |
| 햄버거 | 모델의 reasoning/ memorization 편향이 초기화 스케일에 의해 달라질 수 있다는 점을 명확하게 보여준듯. 결국 학습 초기의 세팅이 이후 학습 과정에서 모델의 “성향”이나 수렴 방향을 크게 좌우할 수 있으므로 모델의 목표 특성에 맞춰 초기화 설계를 적절히 적용할 수 있을듯 | 4.4 |
| 피자 | 모델의 초기 학습 세팅 및 Scale, 데이터셋이 학습의 진행 방향마저도 크게 영향을 미친다는 내용을 Embedding Space로 증명함으로써 크게 의미가 있는 연구라고 보여짐. | 4.1 |
| 치킨 | 요즘 학습 단계별 스케일링 관련 논문들이 많이 보이는데 결국 정해진 학습 비용 내에서 자원 대비 효율을 극대화하기 위해서겠지? reasoning bias를 입증해낸 실험이 명확하게 이해가 되서 좋았던거 같다 | 4.6 |
| 페브리즈 | memory와 reasoning이 다른 것인지, 다르다면 뭐가 우선인 것인지 논의하는 논문 중에 하나. 한편으로 이 주제로는 최대한 큰 모델을 많이 학습시키고서 실험하고 논의하는 게 맞지 않나 싶기도 하고.. | 4.2 |
TL; DR
Transformer 기반 모델에서 초기화 Scale에 따라서 추론을 먼저 배우는가, 암기를 먼저 배우는가의 편향이 존재한다!
Summary

연구진: 미국 Duke University, 중국 상하이교통대
Cite: 4
- 트랜스포머 기반 언어 모델에서 Parameter Initialization Scale에 따라 학습이나 LLM의 Task Preference의 영향에 대해 조사함
- Small Initialization Scale에서는 모델이 Reasoning Task를 잘 수행하도록 Encourage되었음
- Large Initialization Scale에서는 모델이 Memorization Task를 잘 수행하도록 Preference가 유도됨
⇒ 초기화 스케일에 따라 모델의 ‘학습 성향(bias)’가 변함
- 실제 데이터셋과 Anchor Function으로 이 성향을 검증
- 초기화 스케일에 따른 현상의 원인을 Embedding Space와 Self-Attention Mechanism을 통해 분석
- Model Training의 동역학(dynamics) 관점에서 이 현상이 생기는 원인을 설명하는 이론적 프레임워크를 논문에서 제안
- LLM의 초기화가 모델의 성능에 어떻게 영향을 미치는지 이해를 높이는 연구
Introduction
Motivation
- LLM의 Reasoning Task에 대해서는 RHO-1과 같은 Data-driven Approach가 많이 제시되어 있으나, LLM이 진짜 logical rule을 이해하고, reasoning을 수행하는지 아니면 주어진 규칙을 단순히 따라만 하는지에 대한 의문
작은 initialization scale에서는 모델이 작은 단위 레벨의 기능과 복잡한 규칙을 학습함으로써 data에 fit되도록 유도함Neuron condensation effect가 학습 과정에서 생겨남Neuron Condenstation Effect: 동일한 계층의 뉴런들이 유사한 출력을 내도록 뭉쳐지는 현상
- 같은 레이어의 Neuron이 유사한 패턴으로 맞춰지는 현상으로 인해 발생하여 최소 복잡도로 data fitting이 되도록 함
- 표현력은 충분하지만 실질적으로 사용 가능한 자유도가 적어짐
- 개별 샘플을 따로 외울 수 있는 파라미터 분리가 어려워 암기 성능은 떨어짐
- 공통으로 적용되는 간단한 규칙을 찾는 방향으로 학습이 진행
큰 initialization scale에서는 모델이 input-output 매핑에 대한 기억을 하도록 유도하여 암기 성능이 올라감
Contribution
- Reasoning bias를 실제 자연어 학습 설정에서 보여주는 실험
- 모델의 Initialization Scale이 Reasoning Behavior (bias)에 미치는 영향이 상당을 설명하는 연구
Experiments
- Reasoning Bias를 식별하기 위해 neural network를 Small Parameter Scale로, 서로 다른 reasoning 복잡성을 가진 두 가지 데이터셋으로 학습하고 결과를 비교함
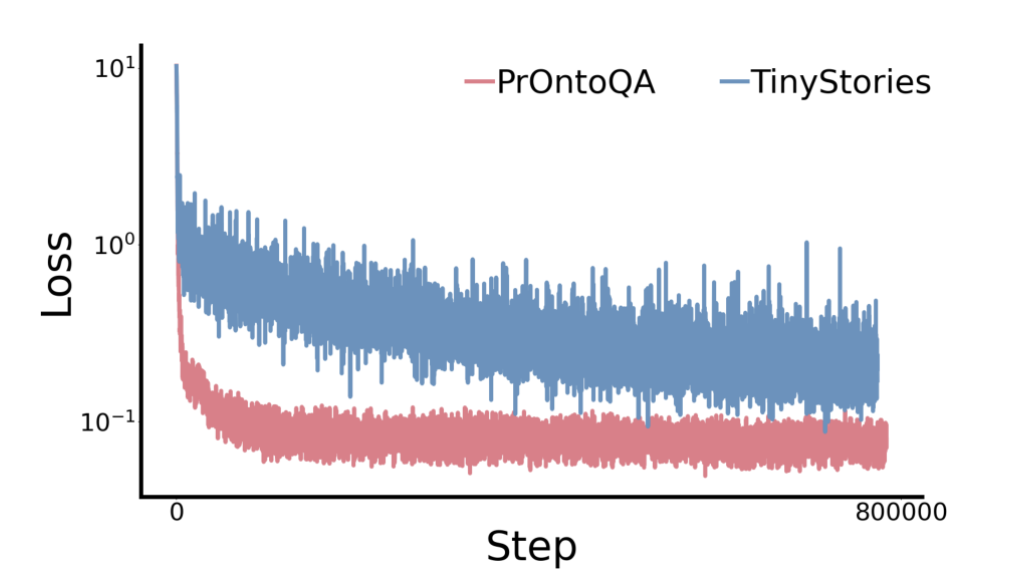
- 두 데이터셋을 GPT-2 상에서 섞어서 학습을 진행한 결과
PrOntoQA데이터셋- CoT를 포함하는 QA 데이터셋
- 질문을 정확히 맞추기 위한
Reasoning을 명시적으로 표현하는 내용
TinyStories데이터셋- 3-4세의 아이가 이해할 수 있는 단어로 이루어진 짧은 합성된 스토리(암기(Memory) 위주)
- PrOntoQA 데이터셋에서 Loss가 빠르게 줄어드는 것으로 볼 때, 모델이 Reasoning pattern을 더 잘 파악함을 알 수 있음
- 추론(Reasoning) 과제가 학습 초기에 빨리 습득되는 이유
- 학습 과정에서 초기에 Embedding space가 더 분화되는 특성이 존재함
- 임베딩이 분화된다: 임베딩 공간에서 Vector들이 서로 다른 방향, 위치로 이동
- 토큰 t는 one-hot이기 때문에 임베딩으로 변환 후 그 토큰이 등장한 모든 샘플의 loss gradient를 누적해서 업데이트하는데 토큰마다 어떤 라벨과 함께 등장하는가가 임베딩 방향을 결정
Reasoning Task에서 임베딩 분화가 빠른 이유- 특정 토큰은 특정 유형의 라벨과 강하게 연관되어 토큰별 라벨 분포가 서로 다름
- 임베딩이 학습 초반부터 다른 방향으로 이동
Memory Task에서 임베딩 분화가 느린 이유- 서로 다른 Memory (암기) 토큰들이 비슷한 라벨 분포를 가짐
- Gradient 방향이 서로 유사, 초기에 임베딩이 서로 구분되지 않음
- 학습 과정에서 초기에 Embedding space가 더 분화되는 특성이 존재함
Result
- Transformer에서 ‘작은 초기화’를 사용하여 실험을 진행
- Biased된 현상을 자세히 관찰하기 위하여 임베딩 레이어와 Multi-layer Perceptron으로 구성된 간략화된 모델을 제안
- 토큰 임베딩은 해당 토큰이 등장한 샘플들의 라벨 분포에 의해 학습되는 것을 이용하여 실험 설계
- Reasoning Anchor
- 토큰 자체만으로 정답이 결정되지 않고 다른 토큰들과의 Composition에 따라 라벨이 달라짐
- Gradient의 분산이 큼
- 라벨 분포가 다양하므로 초기 학습 단계에서 임베딩 분화가 빠름
- Memory Anchor
- 특정 토큰이 거의 같은 정답(label)과 연결됨
- 라벨 분포의 분산이 작고 임베딩 업데이트나 분화가 작음
- Reasoning Anchor
Reasoning Bias in Transformer with Composite Anchor Functions
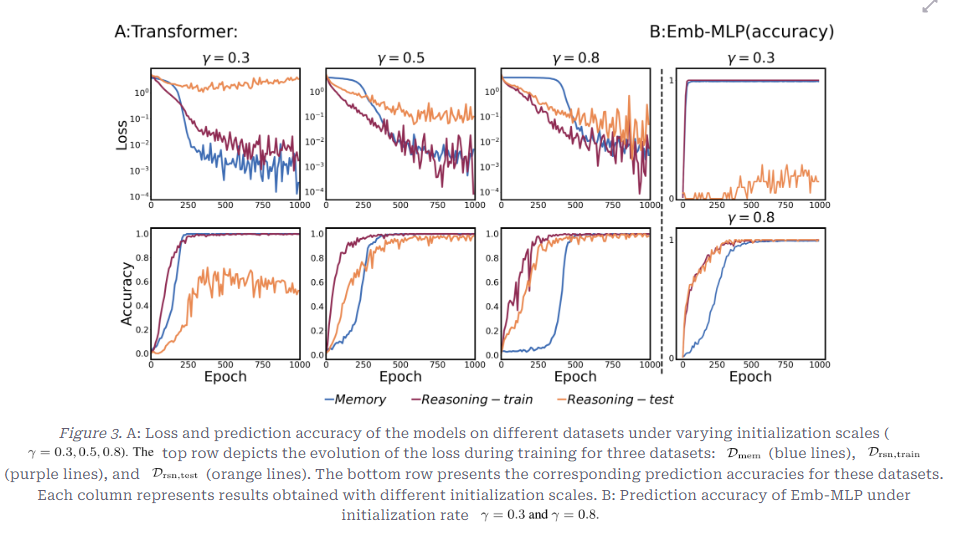
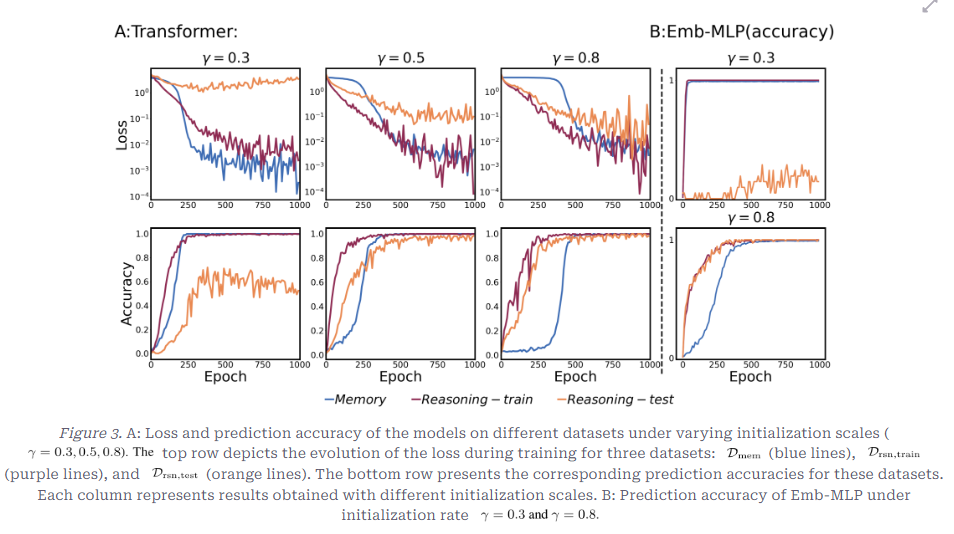
- 0.3, 0.5, 0.8로 Gamma 크기를 변화하였을 때, 위는 학습 중 loss의 변화, 아래 행은 Prediction Accuracy의 변화
- 주의: Gamma크기가 클수록 초기화 스케일은 작은 것임
- Amem (암기로 풀 수 있는 토큰), Arsn (규칙을 알아야 풀 수 있는 토큰), Z (일반 토큰), M (특정 Reasoning Anchor 쌍에만 의미 있는 규칙)으로 데이터셋 구성
- 데이터셋
- 총 200,000개 샘플
- 암기만 하면 되는 데이터, Reasoning이 필요한 train 데이터, Reasoning이 필요한 test데이터로 분리
- 모델
- Decoder-only Transformer (2 layers, 1 attention head)
- Loss: Cross Entropy + AdamW
- 초기화 스케일: 0.3, 0.5, 0.8
- 0.3의 큰 초기화
- 훈련 데이터에서는 암기 데이터, Reasoning이 필요한 데이터 모두 잘 맞춤
- 테스트 추론 데이터에서는 loss가 거의 줄지 않음
- 훈련 샘플 자체를 암기하고 있음을 알 수 있음
Memory 데이터의 loss가 다소 빠르게 하강하고 있음
- 0.8의 작은 초기화
- 추론 데이터는 훈련 및 테스트 데이터 모두 loss가 잘 하강
Memory 데이터의 loss 하강이 다소 느림
- 단순 암기보다 규칙을 먼저 학습
- Reasoning Bias가 발생함
⇒ 모델의 Learning Bias가 Initialization scale에 영향을 받음
Simplified Model
Bias를 더 잘 이해하기 위해 2 layer의 작은 Fully Connected Network에서 실험
- 모델의 정의
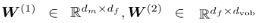
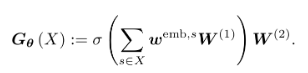
2 layer의 모델로 구성하고, W(1)을 입력 토큰에서 hidden state를 추출하는 Weight로, W(2)를 hidden state에서 출력 토큰을 추출하는 Weight로 구성하고 활성화 함수(sigmoid)를 사용
- Embedding Space가 보이는 패턴 비교
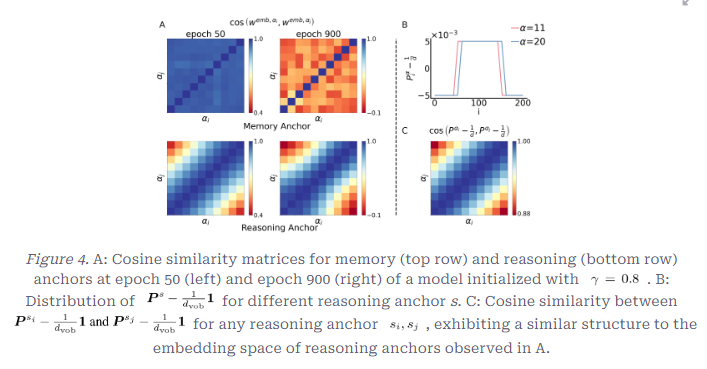
Memory Anchor가 학습 Epoch이 증가하였음에도 일관적으로 거의 같은 방향을 가리킴과Reasoning Anchor가 가까운 거리일수록 같은 방향(Cosine 유사도가 높음)을 가리키고, 거리가 커질수록 유사도가 감소하는 연속적인 결과를 가짐을 보여줌
Memory Anchor와Reasoning Anchor의 임베딩에서 Cosine 유사도를 보았을 때,
Reasoning Anchor에서는 Anchor간 거리가 커질수록 Cosine 유사도가 감소하는 결과를 보여Reasoning Anchor가 빠르게 임베딩 공간에서 연속적, 계층적 구조가 만들어짐
Memory Anchor에서는 모든 Memory Anchor가 거의 같은 방향을 가리킴- 모델의 Primitive-level 매핑, 즉, 임베딩이 더 다양해져야 함
- 복잡성과 다양성이 더욱 증대되어야 함
- ⇒ 그러나 결과적으로 Reasoning Anchor에 비해 Memory Anchor가 다양하지 못하고, 분화가 잘 안되고 있음
- Target 분포가 Embedding을 결정하는 이유
- Assumption
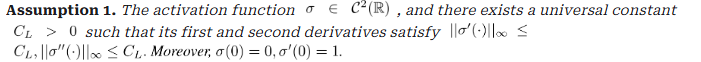
- 작은 입력에서는 활성화가 거의 선형이고, Gradient가 폭주하지 않음을 가정함
⇒ Small initialization에서는 Emb-MLP (합성된 모델)가 거의 선형 모델처럼 작동한다
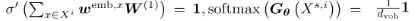
- Hidden Layer의 비선형성이 사라지므로, Target Distribution만 보고 Embedding이 움직임
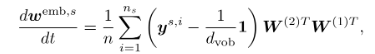
- 토큰 s에 대한 Embedding의 Gradient는 s가 등장한 모든 샘플의 정답 레이블과 uniform 분포의 차이에 의해 누적됨
- Proposition
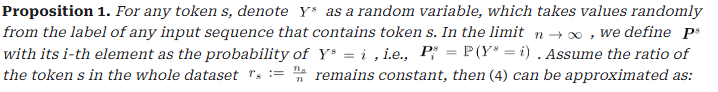
- 랜덤 변수: 토큰 s를 포함한 샘플을 하나 무작위로 뽑았을 때의 정답 레이블
분포: 토큰 s가 어떤 레이블과 얼마나 자주 함께 등장하는가
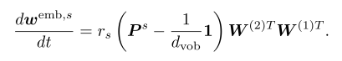
- Embedding의 이동 방향은 정답 분포 P와 완전 균등 분포의 차이에 의해 결정됨
모델 구조, 다른 토큰은 거의 관여하지 않음
- Results
- Memory Anchor가 모두다 거의 같은 방향으로 Align 되는 이유
- 어떤 Memory Anchor가 등장해도 정답 레이블 분포가 동일(Uniform 분포와 차이가 거의 발생하지 않음)
- 모든 Memory Anchor의 Gradient 방향이 같음
- ⇒ 따라서 Embedding이 같은 방향으로만 계속 움직임
- Reasoning Anchor가 분화되는 이유
- Reasoning Anchor s에 대하여 정답 레이블이 모두 동일하지 않음
- 평균(기대값)이 s마다 다름
- Embedding Gradient 방향이 달라짐
- ⇒ 초기 단계에서부터 빠르게 분화
일반적인 Task에서의 Transformer
Transformer에서의 Bias 실험 개요
- MLP (Multi-layer Perceptron) 모델이 Noise Sequence에서 실패한다는 점에서 이러한 실패가 적은 Transformer 모델이 더 나은 점을 보여주지만, 그럼에도
Reasoning bias가 유지되는지 보여주는 부분
- Transformer의 임베딩 space가 Emb-MLP에서 보인 것과 유사한 현상을 보이는지 살펴보고, 모델이 입력으로부터 정보를 어떻게 포착하는지 확인하는 실험
실험 결과
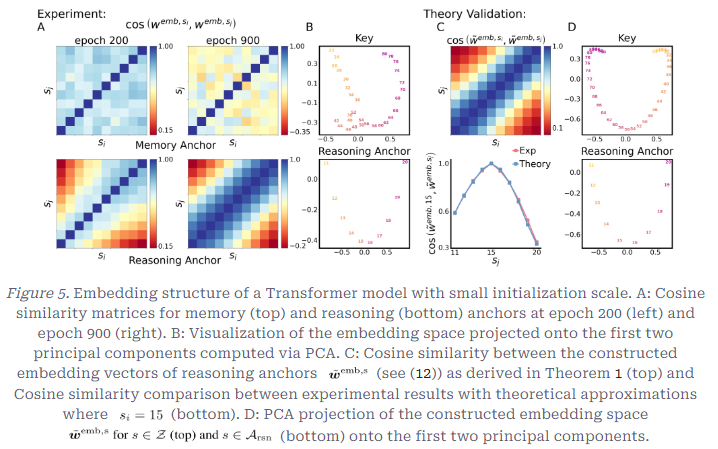
- 앞의 현상이 합성 모델이 아닌 실제 Transformer 모델에서도 그대로 나타난다는 점을 설명한 Figure
- B: Memory Anchor와 Reasoning Anchor의 PCA 분포의 비교
- C: 실제 Transformer Embedding과 합성 모델의 코사인 유사도 비교 그래프
- D: 이론적으로 구성한 임베딩의 PCA
- Embedding Space
- Transformer의
Embedding Space는 Emb-MLP와 거의 동일
Reasoning Anchor는 계층적, 연속적 구조를 보였으며, 거리가 멀수록 Cosine 유사도가 감소함을 알 수 있음
Memory Anchor는 대조적으로 Alignment에 모두 유사성을 보임
- PCA (주성분분석)에서 전체 임베딩 공간의 구조적 특성을 분석함
⇒Attention은 임베딩을 새로 만들지 않고, 기존 임베딩의 bias를 키우는 역할만 한다는 것을 보여줌
⇒ Transformer도 Emb-MLP와 같은 경향성을 보인다!
- Transformer의
- First Attention Module
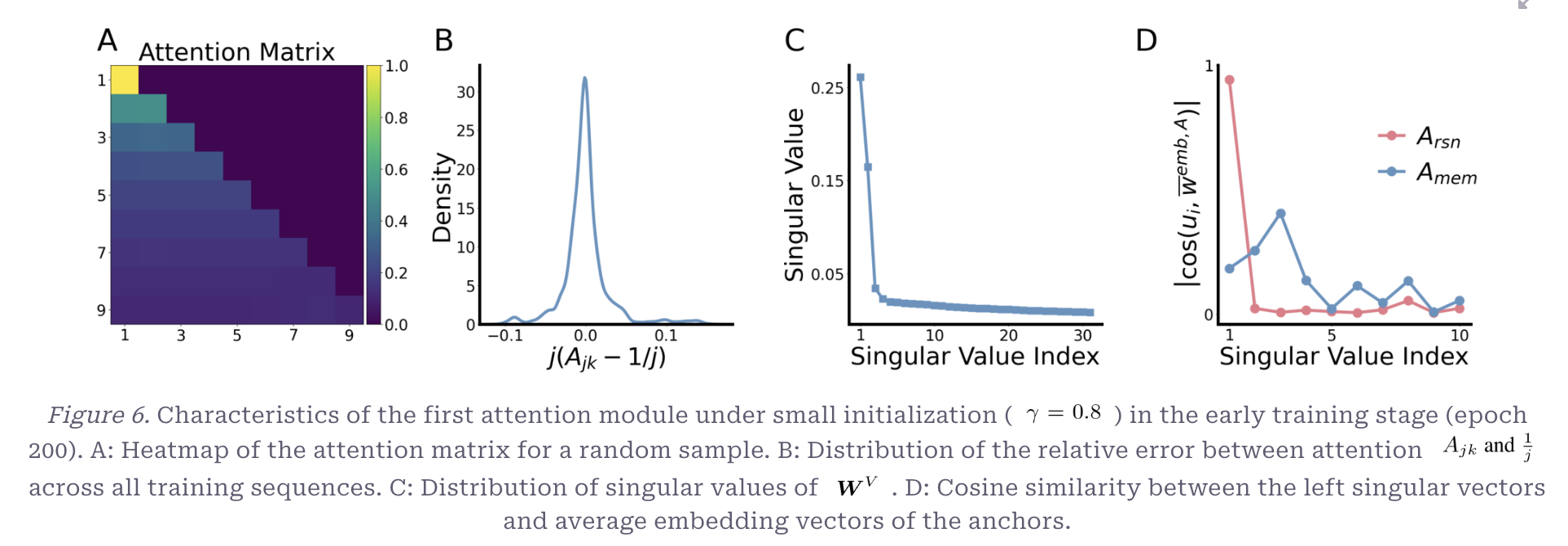
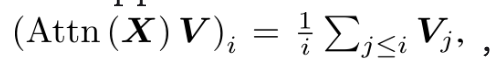
- i번째 token의 출력이 그 이전 모든 token의 평균이 되는 것
- Query-Key의 Dot product가 점차 동일해짐
- 결과적으로 mask로 인해 Prefix Average 연산으로 됨
- 첫 Attention Layer는 어떤 토큰이 중요한지 고르는 역할이 아닌 지금까지 등장한 Token을 누적하는 장치
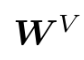
- 의 경우 가장 큰 Singular Value가 나머지보다 훨씬 큼
- Corresponding Singular Vector가
Reasoning Anchor와는 가깝게 align되지만,Memory Anchor는 거의 수직임Reasoning Vector는 거의 대부분 W에서 포착되며, 모든 subsequent 토큰들로 전파됨
- Second Attention Module
- 중요한 정보가 어디있는지 찾고, 마지막 정보를 모으는 역할
- [Definition 2] One-layer Transformer

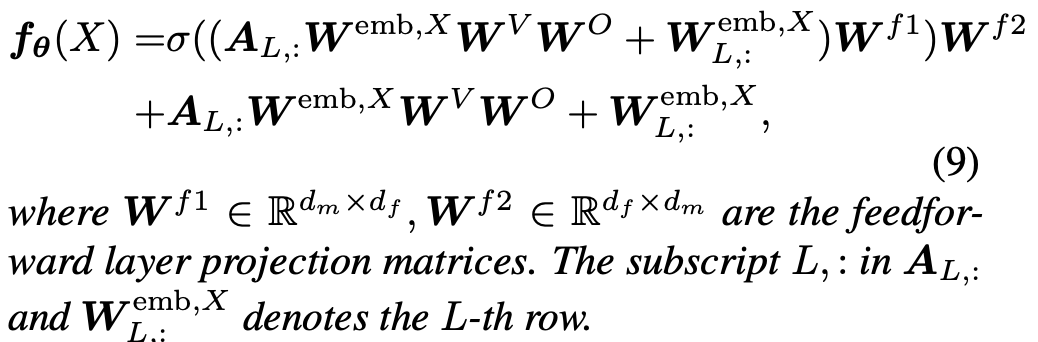
- Layer Normalization와 final projection layer는 제외함
(결과에 영향을 미치지 않는 요소임)
- 앞선 관찰 결과와 같이 Small initialization scale에서는 Attention A가 average로 해석될 수 있음
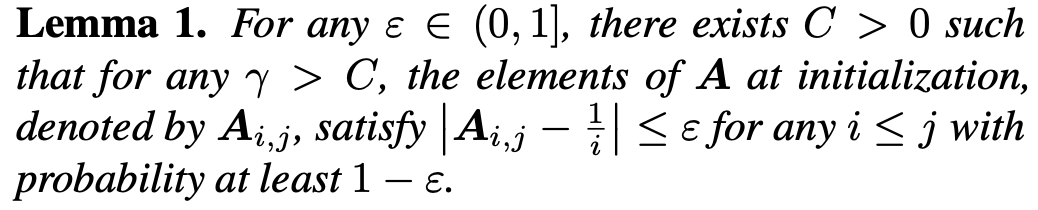
- 작은 초기화일 때⇒ Self-Attention이 Prefix Average와 거의 유사함
- Q, K의 scale이 작고 softmax 입력이 거의0이면 softmax 결과가 거의 uniform
- 순차적 정보 누적으로 Reasoning에 유리
- Proposition 2
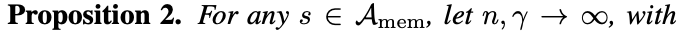
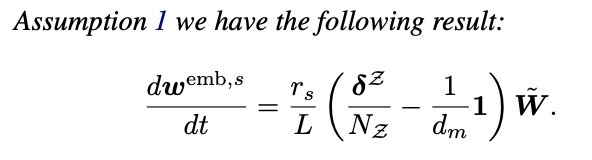
Memory Anchor들은 Embedding 방향이 비슷해지고 한 곳으로 뭉침
- Proposition 3
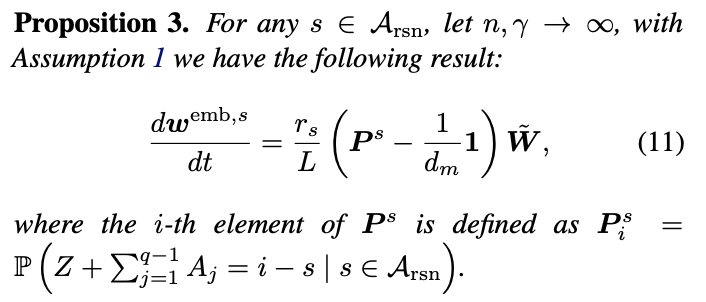
Reasoning Anchor의 임베딩 업데이트
Reasoning Token은 이전 토큰들과 조합되어 Label이 결정됨
- Label 분포 P가 s를 중심으로 퍼진 분포
- 임베딩이 점진적으로 분화
- Theorem1

- Reasoning Embedding의 근사 형태
- 결과적으로 Transformer에서도 Reasoning bias가 일어남을 수학적으로 증명함
- Layer Normalization와 final projection layer는 제외함
Real Language Tasks
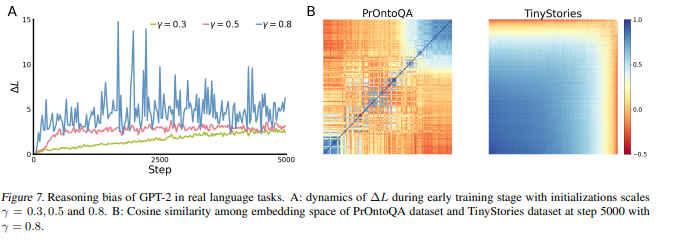
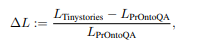
- ∆L: Reasoning Bias를 정량화한 지표
분자: L(TinyStories)-L(PrOntoQA): 두 task 간의 loss차이
분모(L(PrOntoQA)): 추론 과제의 loss로 정규화
Reasoning 과제 대비, Memory 과제가 얼마나 더 어렵게 학습되고 있는가에 대한 지표
- ∆L이 증가하는 것의 의미
- L(PrOntoQA)가 상대적으로 더 빠르게 감소
- 모델이 추론 과제를 더 잘 학습하는 방향으로 biased
- 이 현상의 원인
- GPT-2는 작은 초기화 scale로 학습됨
- 초기 학습 단계에서의 Representation이 분화하였음을 알 수 있음
Conclusion
- 작은 초기화가 추론 선호 bias를 만듦
- Label distribution이 임베딩 공간을 만드는데 핵심 역할을 하고 학습에 있어 동역학적 영향을 미침
- Next-token prediction training과 같은 유사한 task에 활용 가능
- 실험적 관찰과 이론적인 수식으로 증명함