Curriculum Debiasing: Toward Robust Parameter-Efficient Fine-Tuning Against Dataset Biases
Review
| 닉네임 | 한줄평 | 별점 (0/5) |
|---|---|---|
| 계란초밥 | Motivation이 너무 당연한 말 투성이라 저자들의 contribution도 별로 와닿진 않는다. 그나마 curriculum sampling 정도? bias를 curriculum learning에 적용하는 게 신박했는데, bias sample의 의미를 알고 나니 별로 특별해보이진 않음 | 3.2 |
| 맹구 | 데이터셋에서 biased example을 찾는 과정은 의미가 있어보이고, 그러한 데이터도 활용하고자 하는 것은 괜찮아 보임. 그렇지만 데이터가 충분한 환경에서 굳이 biased example을 써야 하는 이유가 있을까? 하는 생각이 남는데, 고민해볼 필요는 있을 것 같다. | 3.8 |
| 국밥 | 굉장히 간단한 motivation이지만 기존연구에서 bias score를 고려한 게 없어서 어찌됐든 결과는 나쁘지 않다! 시기를 잘타고난 논문 아닐까? 실험결과도 OOD 타겟한거 치곤 ID에서도 나쁘지 않아서 괜찮은듯 | 4.2 |
| 피자 | PEFT에서 biased로 인한 성능 저하 문제를 분석했다는 점은 의미가 있어 보임. Contribution이 unbiased example을 제시해서 완화하자는 점이 좀 아이디어 자체는 떨어지는 듯. | 3.8 |
| 치킨 | biased example이 더 빠르게 수렴하는 것을 인정하고 관점 자체가 바꿔 학습 초반엔 bias가 example을 더 많이 학습하고 후반으로 갈수록 un-biased example을 더 많이 보이게 학습하게 하는 방식이 근본적인 원인의 해결책도 아니고 out-dated된 방법이라고 생각돼서 아쉽다. | 3.6 |
| 햄버거 | Biased 데이터로 먼저 학습하면 모델이 더 편향될 것이라 생각했는데, 이러한 커리큘럼이 가능해 보이는 이유는 PEFT 환경이라는 점에 있는 것 같음. 논문중 학습 초반 데이터의 영향력이 크다~ 관련 논문이 있었는데, 그건 pt from scratch 세팅이었음. 즉 학습 후반 데이터는 확실히 표현adaptation 역할을 하는구나 | 4.2 |
| 페브리즈 | 훈련 데이터가 제한된 상황에서 성능을 최대한 끌어올려주는 게 커리큘럼 러닝의 한 기능일 수 있을텐데, 그런 상황에서 데이터의 bias 정도도 고려해볼 수 있겠다. bias score 산출 방식이 새롭다 | 4.2 |
TL; DR
PEFT로 학습할 때 biased example에 overfitting되는 경향 존재함
(biased example에 더 빠르게 수렴하기 때문)
⇒ 학습 데이터 순서를 biased-to-unbiased 로 제시해서, 이를 완화하자!
Summary
- 연구진: 고려대
- 인용수: 1회
Background & Motivation
Parametric Efficient Fine-tuning (PEFT)
downstream task의 성능 향상을 위해, parameter 중 일부만 학습시키는 방식
biased example 란?
: bias attribute만으로 정답을 맞출 수 있는 example
- bias attribute : 과제의 본질적 의미를 이해하지 않아도 정답을 맞히게 만드는 표면적 신호(spurious correlations)
- biased example로 PEFT하면 성능이 저하됨

- out-of-distribution (OOD) evaluation에서, 거의 random한 성능임 (blue dashed line!)
⇒ 기존 debiasing method는 biased를 지워버리거나, unbiased 위주의 학습을 수행함
⇒ but, In-Distribution에서의 성능 저하를 유발함
Contributions (What they’ve revealed)
biased 환경에서 PEFT가 unbiased example 학습을 방해하고 OOD 성능을 크게 악화시킴을 보임
⁉️PEFT의 parameter 개수에 따라 ID, OOD 성능은 어떻게 변할까?
- background
PEFT는 업데이트되는 parameter 개수를 조절함으로써 모델의 일반화 성능을 향상시킨다 [1,2,3].
model의 generalization ability는, PEFT 과정에서 unbiased data를 얼마나 잘 학습헀는지에 따라 갈린다 [1,2,3].
- setting
- model: BERT-base에서의 LoRA,Adaptor
- data
- MNLI(NLI)
: lexical-overlap을 기준으로 biased 여부 판단- biased data:
- unbiased data:
- FEVER(Fact checking)
: biased feature인 LMI-ranked bigrams을 기준으로 biased 여부 판단- biased data:
- unbiased data:
- MNLI(NLI)
- metric: acc
Does PEFT Degrade the Model’s Generalization Performance?
⇒ PEFT 과정에서 unbiased data 의 training curve를 관찰하자

- parameter 개수가 적어져도 ID는 어느정도 성능 유지됨
- but, OOD에서는 parameter 개수의 영향이 큼
- 즉, PEFT는 biased setting에서의 generalization에 매우 취약함
Why Does This Degradation Occur?

- biased 보다 unbiased에 수렴하기 훨씬 어려움
전반적으로 biased에 먼저 수렴하고, 이후 unbiased에 수렴한다고 함 !

⇒ unbiased example을 잘 학습시켜서, 전반적인 generalization 성능을 향상시키자 !!
- biased 보다 unbiased에 수렴하기 훨씬 어려움
- background
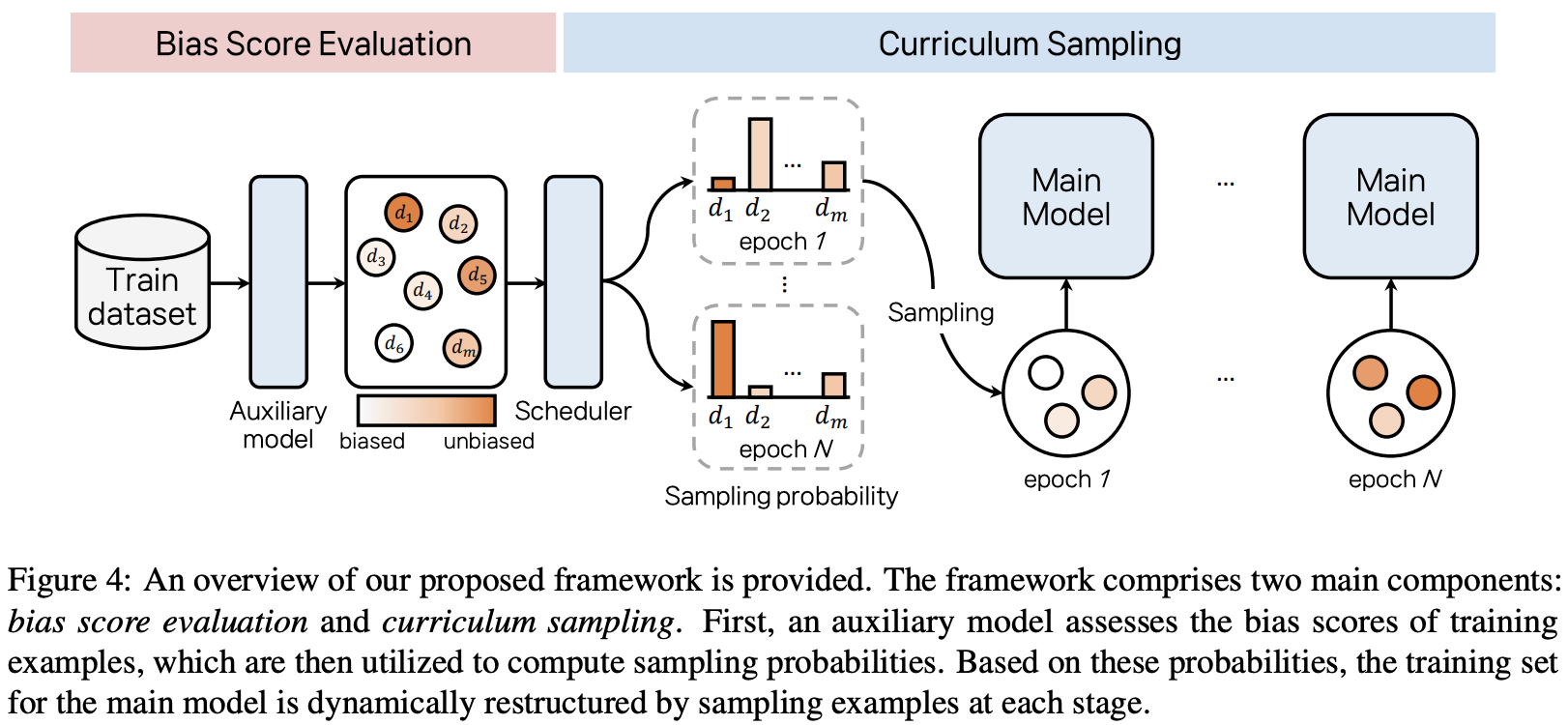
biased-to-unbiased 순서의 CURRICULUM DEBIASING 프레임워크를 제안

- bias score evaluation 💡
bias score로 example의 sampling probability를 만들자
- 일반적인 curriculum learning 처럼, easy-to-hard 순서로 학습시키자!
- easy = biased, hard = unbiased로 두자
- 뭐가 biased이고 뭐가 unbiased일까?
- how to?
- dataset bias를 exploit하도록 학습된 auxiliary model 를 학습시키기
details of
- auxiliary model이란?
- 각 example의 biased 정도를 판단하는 모델
- main model이 biased example는 덜 학습하기 위한 weight로 사용
- 선행연구[3]와 동일한 방법으로 학습
- BERT-Tiny (4M)를 backbone으로 사용하여 target dataset을 학습시킴

⇒ auxilary model이 잘 맞춘 데이터는 biased, 아닌 데이터는 unbiased로 간주
- BERT-Tiny (4M)를 backbone으로 사용하여 target dataset을 학습시킴
- auxiliary model이란?
- 각 example ( )에 대해 가 내뱉는 분포 중 “정답 라벨 에 할당된 확률” 를 bias score의 proxy로 사용
- 가 높을수록 biased example이다!
- dataset bias를 exploit하도록 학습된 auxiliary model 를 학습시키기
- 일반적인 curriculum learning 처럼, easy-to-hard 순서로 학습시키자!
- curriculum sampling💡
sampling probability를 기준으로 매 학습 단계마다 training sample을 재구성하기
- 기존 curriculum learning은 “baby step strategy”을 적용하여 training example을 ordering
- baby step strategy 이란? 전체 trainset D를 여러 버킷으로 나누고 가장 쉬운 버킷부터 시작하여 점차 더 어려운 버킷을 merge하여 학습하는 방식
⇒ but, 모델이 지나치게 쉬운 예제에 반복적으로 노출되기에 overfitting 가능성이 존재 [4]
⇒ 이를 보완하기 위해,
curriculum sampling제안: 각 training step마다 trainset을 다시 sampling
- ( )의 sampling probability Pi

- a: curriculum의 granularity를 결정하는 hyperparameter
- S: trainset에서 bias가 적은 example의 비율을 늘리는 scheduler (학습이 진행될수록 감소; unbiased가 더 자주 sampling됨)

- T: total number of training stages
- β: initial sampling distribution를 조절하는 hyperparameter
- 기존 curriculum learning은 “baby step strategy”을 적용하여 training example을 ordering
- bias score evaluation
다양한 architecture/model scale/task에서의 적용 가능성을 검증
- setting
- 6가지 PEFT 기법과 비교
- Adapter: 모델에 small, task-specific modules 를 넣어 학습함
- Prompt-tuning: input prompt만 조정하여 task-specific adjustment를 수행
- Prefix-tuning: input prefix만 조정하여 task-specific adjustment를 수행
- BitFit: 모델의 bias term만 학습시킴
- LoRA: model weight를 low-rank matrices로 분해하고 low-rank component만 학습
- Ada-LoRA: low-rank matrices를 학습 과정에서 dynamic하게 설정
- backbone: BERTBase(110M), Llama-3.2-1B
- benchmark: MNLI(Natural Language Inference), FEVER(Fact Verification), QQP(Paraphrase Identification)
- 6가지 PEFT 기법과 비교
- results
Main result
- BERTBase(110M)

- Llama-3.2-1B

- PEFT들은 전반적으로 full fine-tuning 대비 OOD 성능이 크게 떨어짐
- but, 제안하는 방법은 거의 full FT 와 비슷하거나, 더 성능이 높음
- BERTBase(110M)
Ablation Study (BERT; 81%)

- w/o Curriculum Scheduler 즉 coarse-grained curriculum으로 인한 성능 저하
- w/o Difficulty-based Sampling 즉 initial set로 계속 학습시키면 학습 저하
reversed curriculum result

- 확실히 OOD에서의 성능 하락
Convergence Speed

- Ours가 Vanila 보다 수렴이 빠름
- Vanila는 100K step 이후에서는 오히려 loss가 증가 (=overfitting)하지만, Ours는 아님
다른 Debiasing Method와의 비교

- 기존 debiasing method는 OOD가 약간 상승 & ID 감소
- Ours는 ID와 OOD 모두 향상 or 유지
- setting
Reference
[1] https://aclanthology.org/2020.emnlp-main.613/ (EMNLP’20)
[2] https://openreview.net/forum?id=Hf3qXoiNkR (ICLR’21)
[3] https://aclanthology.org/2023.emnlp-main.681/ (EMNLP’23)
[4] https://aclanthology.org/2020.acl-main.542/ (ACL’20)