EigenBench: A Comparative Behavioral Measure of Value Alignment
Review
| 닉네임 | Strength & Weakness & Sugguestions | 별점 (0/5) |
|---|---|---|
| 코스피 | 강점: 모델마다의 특징을 다른 모델이 평가하도록 하고, 각자 다른 모델이 특정 모델을 평가한 결과를 수치화함으로써 객관성을 어느정도 확보했다는 것이 강점임. 약점: 타 모델간의 비교 과정에서 계산 자원을 너무 많이 소비하고 비교 결과 산출에 시간이 오래 걸림. 새로운 비교 대상 모델이 추가된다면 나머지 각각의 모델에 대해서 전부 다시 계산해야 할텐데… 개선(제안): 모델 간 비교 및 계산 성능을 향상하기 위해 비교 우위나 캐싱을 사용하는 방법이 제안되었으면 함. | 3.9 |
| 얼라 | 강점: 해당 논문의 motivation처럼 가치는 주관적이기 때문에 정답 라벨이 있는게 맞나라고 생각했었는데 ground-truth label이 없이 실험한 부분이 마음에 듦 약점: LLM 의 성능에 따라 Value Evaluation의 문제가 생기지 않을까? 그리고 계산,비용적인 측면에서 practical 하지 않은듯 제안: 하나의 모델이 평가하는건 단일 모델의 bias가 있을 수 있으니 여러 모델이 평가하는 방식으로 해보는건 어떨까? | 3.7 |
| 비요뜨 | 강점: 정답이 없는 subjective alignment를 비교하거나 측정하는것은 항상 어렵다고 생각하는데, 그 비교기준이나 평가기준을 잘 세운듯 약점: constitution 종류나 population에 따라 평가가 달라질 수 있을 것 같음 제안: prompt나 persona영향을 분리해서 측정하는 설정이 있으면 좋을듯 싶다. 모델의 가치 성향인지 prompt에 의해 유도된 행동을 분리해 측정하면 설득력 있을듯 | 4 |
| 칫솔 | 강점: 언어모델이 충분히 이러한 주관적인 평가할 능력 있으므로 이를 적극 활용함 약점: 실질적으로 기업이 아닌 이상 사용하기 쉽지 않을듯 (비용 문제) 제안: 도메인에 따라 이 정도로 비용을 들여야 정확한 평가 가능한 경우도 있고 아닌 경우도 있을텐데 이에 대한 분석 | 3.6 |
| 설향딸기 | 강점: 모델이 평가하는 시대가 왔는데, 모델이 가지는 주관적 성향을 알 수 있어야 한다고 생각하고, 그것을 명확하게 규정하고 수행하는 연구. 약점: 고려해야될 것이 너무 많은데(평가 방식, 데이터, label, 평가 기준, noise…) 이거 다 컨트롤이 가능한가..? 제안: 분포 기반으로 하면 어떨까? 생성 임베딩의 분포 등 | 3.8 |
| 나스닥 | 장점: human 통계랑 비슷한 양상을 가지는 벤치마크 제안 단점: 정리된거만 보면 뭐한건지 모르겠음 제안: 타 LLM benchmark와 비교해서 어떤 부분에서 경쟁력있는 벤치마크인지 강조할 것! | 2.5 |
| 국밥 | 강점: 주관적 가치는 정답이 없어서 평가 기준을 세우기 어렵다고 생각했는데 이 문제를 다루면서 언어 모델이 서로를 평가하는 방식으로 해결한 접근이 신선했음. 단점: 모델 1쌍 비교할 때마다 비용이 크고, 새 모델이 추가될수록 비교 횟수가 늘어나 현실적으로 적용하기 어려울 것 같음. 제안: constitution을 어떻게 작성하느냐에 따라 평가 결과가 달라질 것 같은데 이에 대한 검증이 필요하지 않을까 | 3,6 |
| 커피 | 강점 : human preference와 관련된 벤치마크를 만들 수 있을까? 벤치마크 또한 주관성이 크지 않을까 싶긴 했지만, 여러 모델을 사용해서 pairwise를 구성하고, 고유벡터를 사용해 설계 부분에서 이론적으로 타당성을 확보한 것 같음. 약점 : '주관성' 이라는 문제는 완전 해결한 것 같진 않으며, 벤치마크에 사용된 모델의 의존도가 있어보임. 제안 : 벤치마크 구성 시 다양한 '성질'을 가진 모델을 사용하거나, human evaluation을 추가 포함하는 등 모델 의존성을 줄이고 일관성을 강조(모델과 인간의 결과가 비슷하다~)하는 방법이 제시되면 좋을 것 같다! | 4 |
| 404 | 강점: 모델의 주관성을 평가하기 위한 벤치마크를 제안했음 단점&제안: 데이터셋 만드는 과정에서 rationale이 부족함 (기준, noise, 주관성 등등) | 3 |
| AI | 강점: Alignment 자체가 주관적인 가치를 정량화하기 어렵다는 문제를 직접 해결하려는 접근을 새롭게 제안함 약점: 모든 모델이 동일한 RLHF 방향을 가지고 있으면 model 간 consensus가 사람의 가치를 표현하지 못할 수 있지 않을까? 제안: LLM judge 품질을 좀 더 다양한 방향으로 테스트할 수 있을 듯. 적대적인 response나 prompt 자체를 동적으로 수정하는 방향도 포함할 수 있음 | 3.5 |
TL; DR
💡
모델의 주관적 성향을 다른 모델의 성향과 비교하여 순위를 매기고, 신뢰도 벡터로 수치화하여 신뢰성을 판단하고, 모델마다 판단의 기준 차이를 확인할 수 있다!
ICLR 2026

Cited: 0
Summary
Background
- 모델의 주관적인 기질을 파악하는 것이 중요함
- 모델에서 중요한 Trait이 가장 주관적일 때가 많음
- trait이 subjective하는 예시: 한 사람이 모델이 kind(친절)하다고 판별한 것을 다른 사람은 fawning(아양)이라고 평가할 수 있음
- 이 문제를 해결하기 위해 language model이 다른 모델을 평가하도록 함
Contribution
- 특정 조건에 따른 점수 리더보드를 구성하여 모델들이 얼마나 기준에 부합하는지 비교 및 분석 가능
- Language Model이 다른 모델의 답변을 평가하도록 하여 모델이 특정 기준에 부합하도록 Fine-Tuning을 더 쉽게 할 수 있도록 함
- 모델의 가치 성향과 중요하게 보는 Feature를 EigenBench Score 산출에 사용하여 모델별 판단 기준의 차이를 볼 수 있음
Method
- Model Population
- 비교 대상 모델의 개수: N
N ≥ 2 (2개 이상의 모델로 비교)
- 각각의 모델은 모두 평가 모델과 평가 대상 모델 둘 다 해당됨
- 모델 M은 base model m과 페르소나 p로 구성(M=(m,p))
- 비교 대상 모델의 개수: N
- Constitution(구성 조건)
- Constitution
- 조건 내의 기준(Ci)는 LM response를 비교하기 위해 비교하는 모델에 prompt 형태로 제공됨
- 이 방법은 다양한 Constituion(조건) 내에서 적용이 가능하여 조건이 달라져도 유효함
- 예: Universal kindness, conservatism, deep ecology
- Universal Kindness는 넓고 보편적으로 받아들여지는 기준이고, Conservatism, deep ecology는 좁으면서 논쟁적인 기준
- 본질적으로 이 기준들은 주관적이기 때문에 여러 모델의 평가를 모으는 EigenBench가 이 평가에 적합함
- Scenario Dataset
- Set of Prompt Scenario S로 구성
- 실제 일어날 수 있는 시나리오(human concerns, dilemmas, curiosities)를 반영한 데이터셋으로 구성
- r/AskReddit에서 수집된 Kaggle Dataset
- OASST Conversations
- 실제 인간과 LM 사이의 대화
- 초기 User Prompt만 추출
- AIRiskDilemmas
- 모델이 생성한 윤리적 딜레마
- 모델의 가치 판단 능력 판별
 https://www.kaggle.com/datasets/rodmcn/askreddit-questions-and-answers
https://www.kaggle.com/datasets/rodmcn/askreddit-questions-and-answers
- Collecting Pairwise Comparisons
- 조건 C에서의 시나리오 S일 때, 평가 대상 모델 j, k, 평가 모델 i가 존재함
- 모델 Mj, Mk에서 각각 대답을 얻어내 Rj, Rk라 함
- Rj, Rk를 Mi(평가 모델)에서 평가한 결과를 Rj^, Rk^라 함
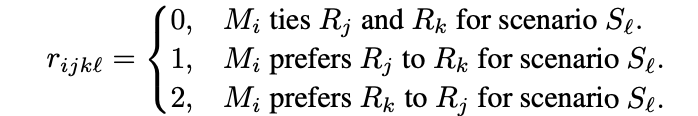
- bias를 피하기 위해 Rj, Rk의 순서를 바꿔서도 평가함
- 순서에 따라 선호도가 달라지는 경우 tie(무승부)로 평가
- Low-Rank Bradley-Terry-Davidson Model
- 모델의 선호 랭킹(win, lose, tie)에 대한 데이터를 4에서 수집한 후, Bradley-Terry-Davidson (BTD) 모델을 이용하여 이것을 확률적인 Ranking으로 변환, 모든 결과들을 하나의 Matrix로 합
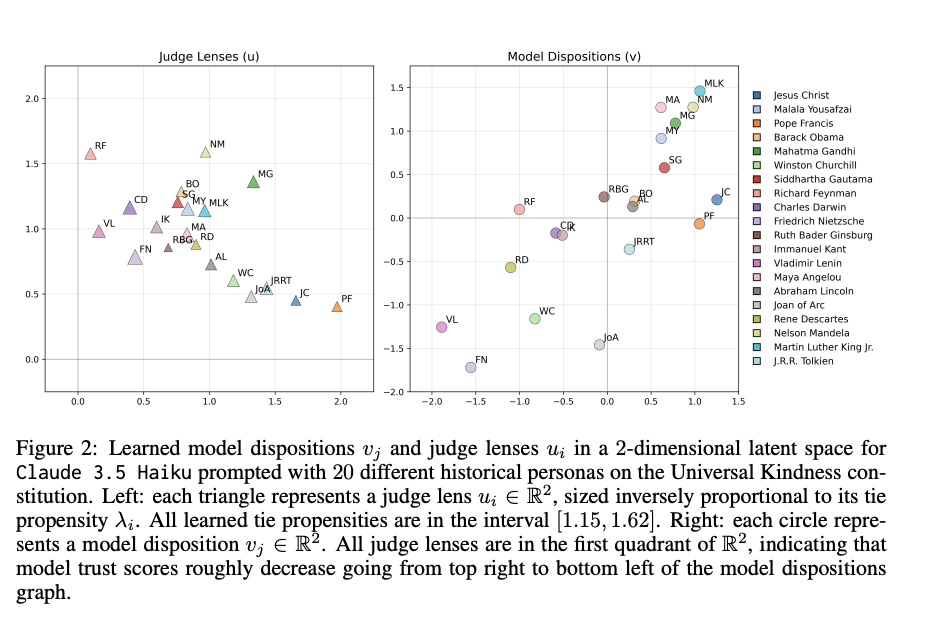
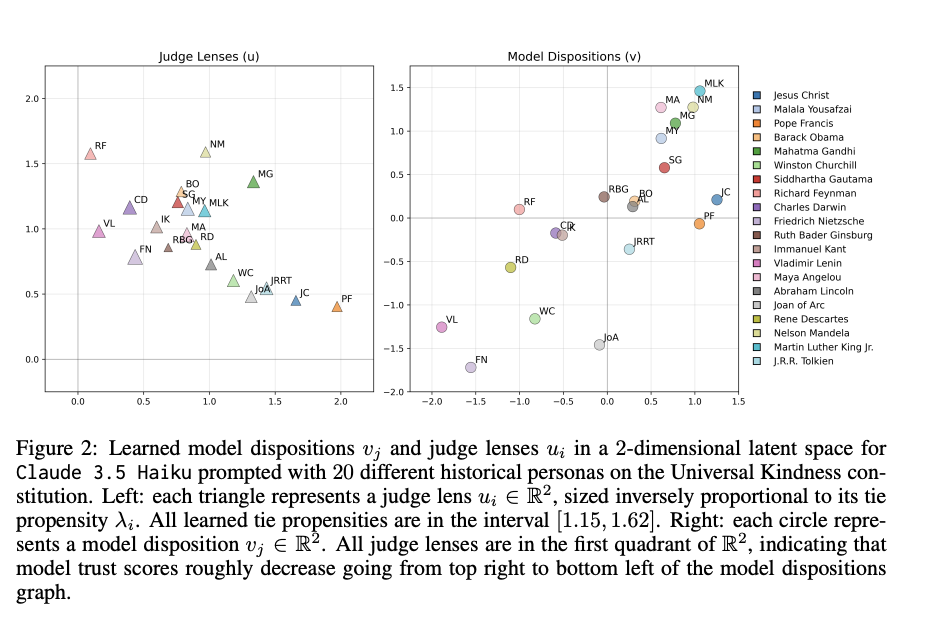
- 각 평가 대상 모델(Mj)에 대해 Latent disposition 벡터 vj 학습
- 각 평가 모델(Mi)에 대하여 Judge lens 학습
- 각 평가 모델 latent의 어떤 부분을 중요하게 보는지 반영(각 평가 대상 모델의 어떤 부분이 중요한지 반영)
- 각 평가 모델에 대하여 tie Propensity 학습(무승부되는 경우가 얼마나 되는지)
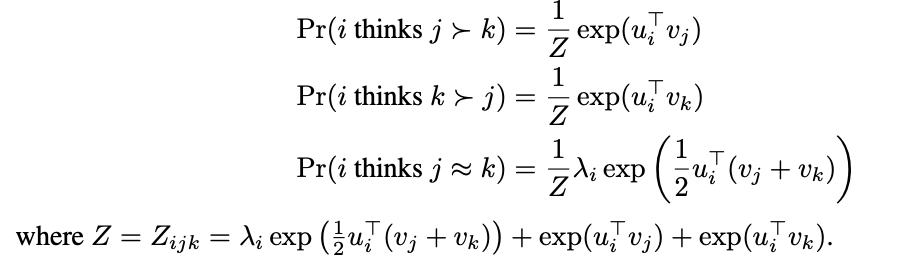
실제 결과와 모델이 예측한 결과가 일치할 확률 계산
(예: 평가 모델 i가 j>k를 선호한다고 예측하는데 실제로 i가 j>k를 선호할 확률)j>k, k>j, jk tie의 3가지 경우 모두에 대하여 계산해서 결과를 더함
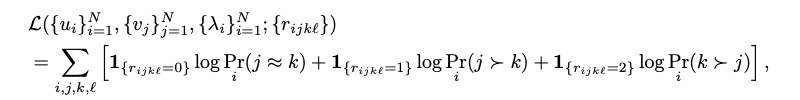
- EigenTrust
- ui와 uj의가 앞의 확률 모델에 의해 fit되면 Trust Matrix(신뢰 행렬)을 출력
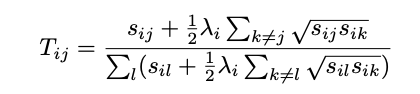
- 평가 모델 Mi가 Mj를 얼마나 신뢰하는지 나타내는 행렬
- Trust vector t를 EigenTrust로부터 얻음
- T(신뢰 행렬)의 left principal eigenvector
- t(0)은 uniform distribution으로 초기화함
- t(n+1) = t(n)T를 반복하고, t(n+1)-t(n)이 일정 임계치(Threshold) 미만으로 떨어지면 수렴으로 간주(모델마다 평가한 점수를 Aggregation하여 모델간 consensus한 점수를 산출)
- t: 모든 모델에 대한 신뢰도 분포 점수(각 모델이 얼마나 신뢰받는가를 종합해서 나타낸 수치)
- Elo Rating(Elo & Sloan, 1978)으로 어떤 모델 j에 대한 신뢰도 랭킹 점수 최종 결과 산출
- Eloj = 1500 + 400 log10 (N tj )
Results
- Model Rankings
- 평가 대상 모델
- Claude 4 Sonnet
- GPT 4.1
- Gemini 2.5 Pro
- Grok 4
- DeepSeek v3
- Qwen 3
- Kimi K2
- Llama 4 Maverick
- 평가 방법
- r/AskReddit 데이터셋에서 1,000개의 시나리오를 선택
- 각 시나리오에 대해 모델 간 쌍(pairwise) 비교를 약 30,000번 수행
- 비교 결과로 각 모델이 얼마나 좋은 답변을 내는지 점수(EigenBench score) 산출
- 평가 대상 모델
- Human Validation
- 인간 평가자 비교 과정
- 두 명의 인간 평가자(논문 저자, 독립된 외부 평가자)
모델과 같은 방식으로 LM 답변 pairwise 비교
- 각 시나리오에서 LM 답변 2개를 랜덤 선택
- 인간에게 Universal Kindness 조건 기준 8개 항목으로 비교하도록 함
- 점수 계산: Bradley-Terry-Davidson 모델
- 인간 판단을 수치화하기 위해 Bradley-Terry-Davidson 모델 사용
- 각 모델 j와 인간 h에 대해 잠재적 점수(latent score) 학습
- 신뢰 벡터 계산
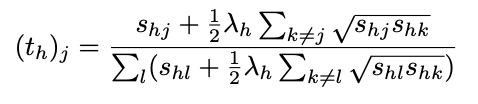
LM이 비교하는 방식과 유사하게 비교하여 점수의 신뢰성 확인 가능
- Validation on Ground Truth Labels
- 객관적, 정답이 있는 문제에서도 EigenBench가 모델 순위를 잘 복원할 수 있는지 확인
- GPQA 벤치마크를 사용
- 대학원 수준 물리, 화학, 생명 문제 448개
- 객관적 문제(A, B, C, D)로 구성
- 실험 설계
- 총 15개 모델 평가
- 기존 조건 기반 평가는 생략
- 각 문제에 대하여
- 두 모델 j, k의 답변 Rj, Rk 수집
- 판정자가 둘 중 어느 답이 더 나은지 선택
- 비교값(trit) 정의
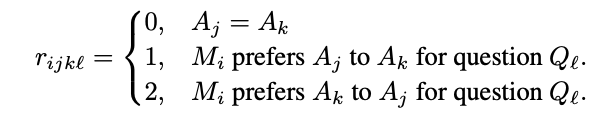
- EigenBench는 모델들 간 상호 신뢰(trust)를 계산할 수 있음
b. 점수 계산
- Bradley-Terry-Davidson(BTD) 모델을 사용
- trit 데이터를 기반으로 신뢰 행렬 T 학습
- 판정자가 모델 답을 얼마나 신뢰하는지
- 최종 trust vector t, 전체 모델 집단의 합의(consensus) 평가
- 즉, 모델들이 서로를 얼마나 믿는가를 기반으로 성능 순위 도출
c. 결과
- EigenBench 순위는 정답 기반 순위와 거의 일치
- Ground-truth 정답을 제공하지 않아도 모델 간 신뢰만으로 실제 성능 순위를 잘 복원
- 주관적 특성 평가에도 신뢰할 수 있는 합리적 순위(rankings) 생성 가능
Conclusion
- Diverse한 시나리오에 대하여 한 모델이 다른 모델을 평가하게 하고 이것을 EigenTrust를 적용하여 하나로 합침
- Human Judgement와 객관적인 Ranking으로 비교했을 때, 같은 모델들에 대한 평가 결과가 EigenBench와 일치하여 Eigenbench가 유의미함
Limitation
- EigenBench의 데이터 수집 방식이 비효율적
- 두 모델의 비교는 각각의 모델에서 Response Call과 Reflection Call, 그리고 두 모델을 비교하는 Comparison call을 필요로 하여 부하가 큼
- Higher loss value를 가진 모델에 대해서 더 많은 비교를 수행한다거나 하는 대책이 필요(BTD 모델)
- 인간 평가자 비교 과정