How Post-Training Reshapes LLMs: A Mechanistic View on Knowledge, Truthfulness, Refusal, and Confidence
Review
| 닉네임 | 코멘트(Strength, Weakness, Suggestion) | 별점 (0/5) |
|---|---|---|
| 코스피 | 강점: Base-model을 Post Training Model로 Train할 때, Confidence와 Truthfulness, Refusal 분석으로 변화의 원인을 분석한 점이 강점 약점: Neuron이 크게 변하지 않는다고 하는데, 그럼 Post에서 Base모델간 차이를 단순히 Refusal 분석으로 설명이 가능한 건지 모호한 부분이 있음. 개선: Base-model과 Post model을 변화시키는 디테일 변화에 대한 설명이나 증명이 자세할 필요가 있음. | 4.5 |
| 비요뜨 | 강점: 모델의 post-training을 모델 행동 특성에 나누어서, 특성에 따라서 기존위에 유지되는, 혹은 덮어씌어지는 영역이 있다는 것을 잘 제시했음. 근데 왜 저 4개의 기준을 선정하게 되었는지 궁금하다 약점: keyword 기반 refusal score은 상대적으로 부정확할수 있을것 같음(그런데 이건 판별하기 위해서는 어쩔 수 없으려나?) 제안: 예를 들면 reasoning 능력과 같이 4가지 이상의 기준으로 확장할 수 있을것 같음 | 4.3 |
| 칫솔 | 강점: post-training 시 refusal 방향이 바뀐달지, patching 효과에 방향성이 있달지 (post→base 효과 없기도 함) 하는 분석결과가 새로움 약점: base model에서 post-training model 방향으로는 neuron이 대체로 기능 유지한다거나, patching 효과 유지된다는 발견은 기존에 있던 것 제안: entropy neuron과 confidence의 관계에 대해서 의문만 남겼는데, 이에 대한 분석 | 4.0 |
| 나스닥 | 장점: 반전이 있는 결과! confidence에 대한 새로운 사실을 알게 됨 약점: 나머지 실험 결과는 대부분 그럴듯하고 비슷한 실험, 논문들이 이미 많음, novelty는 조금 떨어지는 느낌 제안: Post-training이라는 단어 자체가 너무 포괄적임. Preference optimization이나 instruction tuning같은 주로 사용되는 post-training 기법 안에서 더 심층적인 분석을 하는 것이 의미있는 실험 결과, 새로운 실험 결과, 해석가능성을 주지 않을까? | 3.5 |
| 얼라 | 강점: 지금까지 읽은 alignment 논문은 다 출력 즉, 모델의 응답을 보고 결과만 봤다면 모델 내부 표현을 본다는 점에서 신선함. 실험을 통해 지식 저장 위치가 안바뀐다는 걸 입증한 점 약점: confidence 차이에 대해서는 entropy neuron만으로 설명되지 않는다라고만 하고 실제 원인이 뭔지는 제대로 설명하지 못함 제안: 다른 preference에 대해서도 post-training이 유사한 패턴을 보이는지 에대한 추가 분석 | 4.2 |
| 설향딸기 | 강점: 지식 저장과 선호도 개선이 별개라는 것으로 이해되고, 파라미터 지식이라는 말과 굉장히 잘 맞는다고 생각되며 명확함. 약점: 기존 논문에서도 각 작업의 영향을 미치는 layer 가 다르다는 등 많은 결론을 내고 있고, 그 계열의 논문 중 하나라고 느껴진다. 제안: 지식 저장이 문제가 아니라, 지식을 쓰는게 바뀌는 것이 문제 아닌가? 추론 과정이 달라지는 것이라고 생각함. attention, embedding 등 그러한 방향의 실험이 더 유용하지 않을까? | 3.8 |
| 404 | 강점: post-training이 어떻게 영향을 끼치는지를 기존 연구와 달리 지식저장 및 모델 내부 관점에서 분석함 단점&제안: post-training이 영향을 끼치는 특성이 refusal 말고 더 없나? 더 다양한 특성에 대해서도 궁금함! (e.g. attention) | 4.3 |
| 커피 | 강점 :Post-Training의 실험 결과만 보고 판단했던 것을, 내부적으로 분석하여 체계적인 해석 근거를 제시함. 약점 : 4가지 관점 외에 다른 관점에 대해서도 확장 가능할 것 같고, 사용한 실험 방식이 LLM의 복잡한 구조(능력?)에 대해서 충분히 해석(분석)을 했다고 할 수 있을까? 제안 : 다른 관점에 대해서, 그리고 추가적으로 해석가능성에 대한 다른 실험 방식도 있었으면 좋을 것 같음. | 4.2 |
| 국밥 | 강점: Refusal은 pre training에서 자연스럽게 생기는 게 아니라 post training이 새롭게 만들어내는 능력이라는 걸 수치로 증명함. 약점: Confidence의 원인을 entropy neuron이 아니라고만 결론짓는데 confidence 변화의 원인에 대한 설명이 더 있었으면 좋았을것 같다 제안: 4가지 이상 관점에 대해서 추가 실험 | 4.3 |
| AI | 강점: Post-training을 내부 메커니즘 관적에서 분석하고, refusal & confidence alignment를 새로 분해해서 활용한 점이 interpretability를 상당히 끌어올렸다고 봄 약점: LLM의 실제 지식은 단순한 사실관계가 아닌 멀티홉, 인과관계 등 훨씬 복잡한데 지식의 location이 변하지 않는다는게 이런 지식에도 적용이 될지는..? 제안: 문제 세팅을 멀티홉, 인과관계등을 고려할 수 있도록 확장하고 LLM 크기도 올려서 scale에 따른 경향성 분석 수행 | 4.1 |
TL; DR
💡
Post-training 후 모델 내부 지식, 진실성, 안전성, 확신성의 변화를 기계적으로 분석!

저자소속: UCLA, University of Alberta, UIUC, Harvard
Summary
Background
- 요즘 Post-training의 목적
- Truthfulness 향상
- Safety alignment (악의적 공격에 대한 방어)
- 모델의 confidence 보정
- 요즘 Post-training 기법들
- Direct Preference Optimization (DPO)
- Reinforcement Learning from Human Feedback (RLHF)
- Downstream task improvement
Motivation
- Post-training을 더 잘하기 위해서, 기계적으로 해석하자!
- 기존 연구들은 제한된 알고리즘, 태스크, 모델, 방법론(SAE)을 쓰고 있음
- 우리는 더 체계적으로 함!
Contribution
- Base모델과 Post 모델을 체계적, 기계적으로 분석
- Instruct model (모든 post-training 끝난 모델) , SFT model (fine-tuning만 함) 가지고 분석
- 다음의 관점에서 post-training 전후 비교
- 지식 저장과 표현
- 내부적 truthfulness
- Refusal
- Confidence
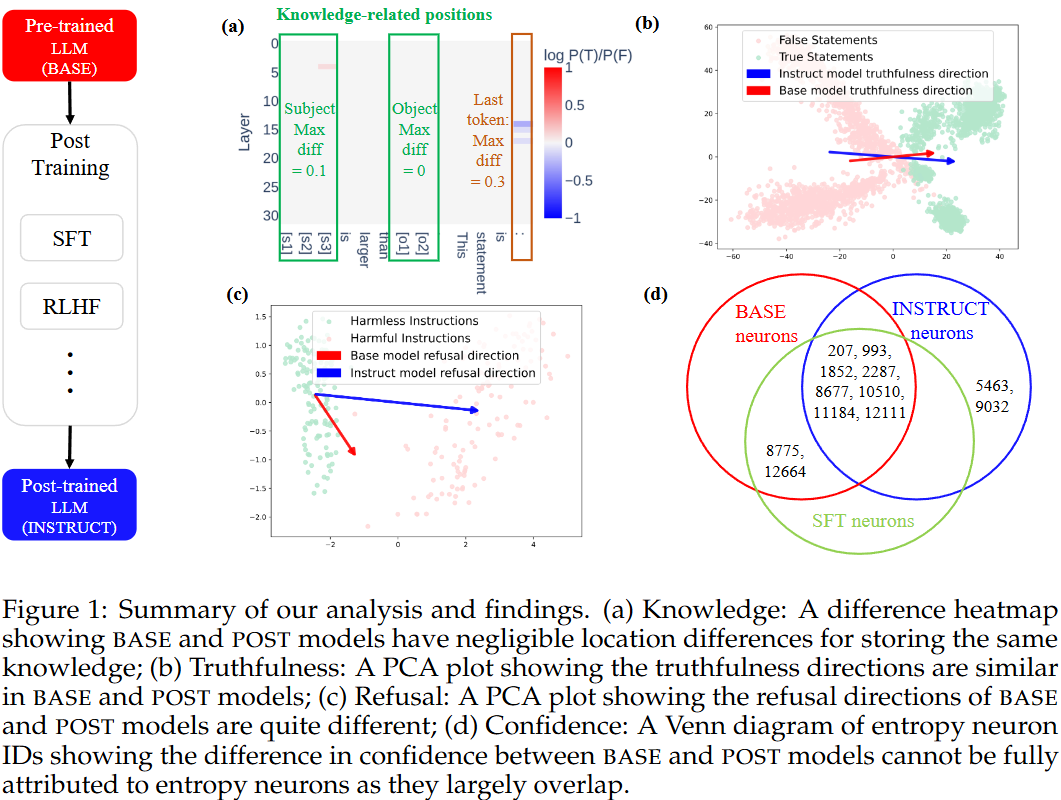
- 아래는 요약 figure
- 지식 → 저장하는 위치, 표현 방식 유지되거나 강화됨
- 내부적 Truthfulness 방향 유지됨
- Latent vector가 유지됨
- Refusal은 방향 바뀜
- Confidence는 entropy neuron이 아닌 다른데서 강화됨
- Confidence가 보정된다고 entropy neuron이 달라지는건 아님
Task별 Dataset 구성
- 지식, Truthfulness는 TF 문제, Refusal은 harmful text로 데이터셋 구성

Knowledge Storage and Representation
- Post-training 전후로 지식 저장 위치가 바뀌는지, 지식 표현 벡터가 크게 달라지는지 확인하자!
- 유지되면 좋은 것
실험 세팅
- 지식에 관한 T/F 문제로 테스트
- E.g. “The city of New York is in the United States. This statement is:”
- 참/거짓 문장끼리의 hidden state 차이를 보고 지식 저장 위치를 판별함
- E.g. “The city of Seattle is in France.” vs. “The city of Paris is in France.”
- 참 문장 줬을 때의 번째 layer 번째 토큰의 hidden state , 거짓 문장은
- 거짓 문장 주고 hidden state를 교체해서 답변이 False에서 True로 바뀔 때(정확히는 확률 보고 결정) 그 위치에 지식이 저장되어 있던 것!
- 이게 크면 지식 저장이라는 뜻
-
이렇게 데이터셋에 대해 정규화시켜서 계산
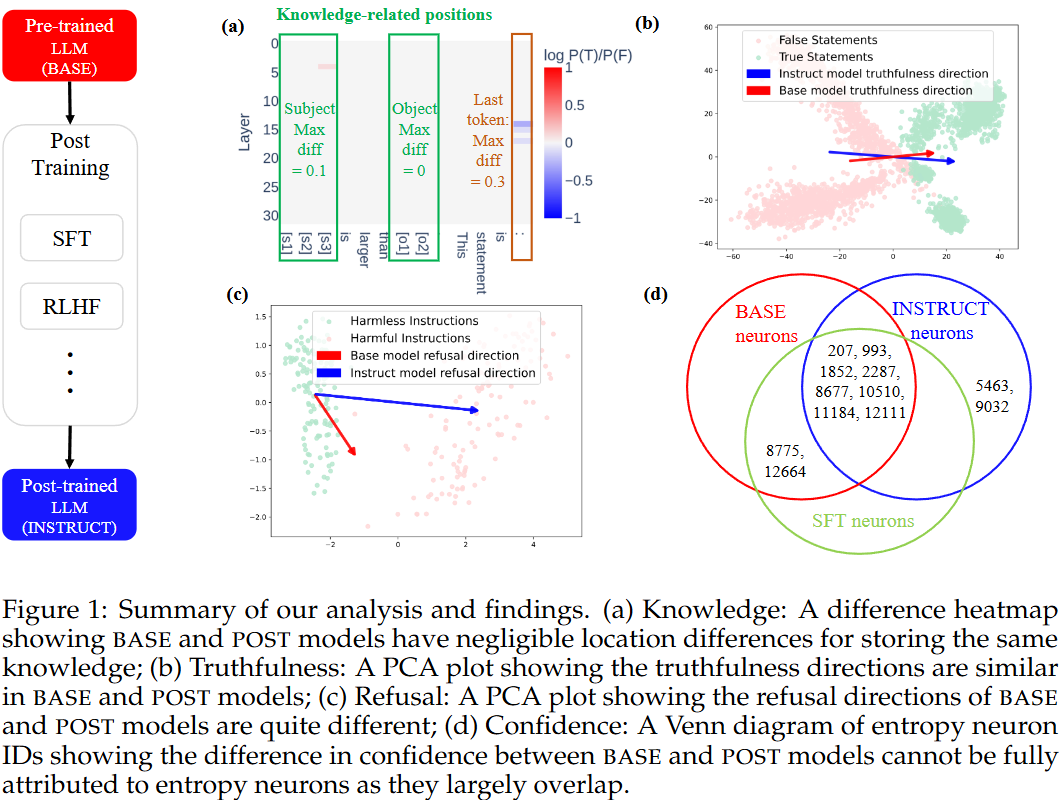
Post-training은 지식 저장 위치를 바꾸지 않는다!
- Base와 Instruct 모델에서 주로 반응하는 토큰의 위치는 subject, object, 마지막 토큰(여기에는 문장 전체의 정보 포함)
- 모델간 차이를 냈을 때 0에 가까움
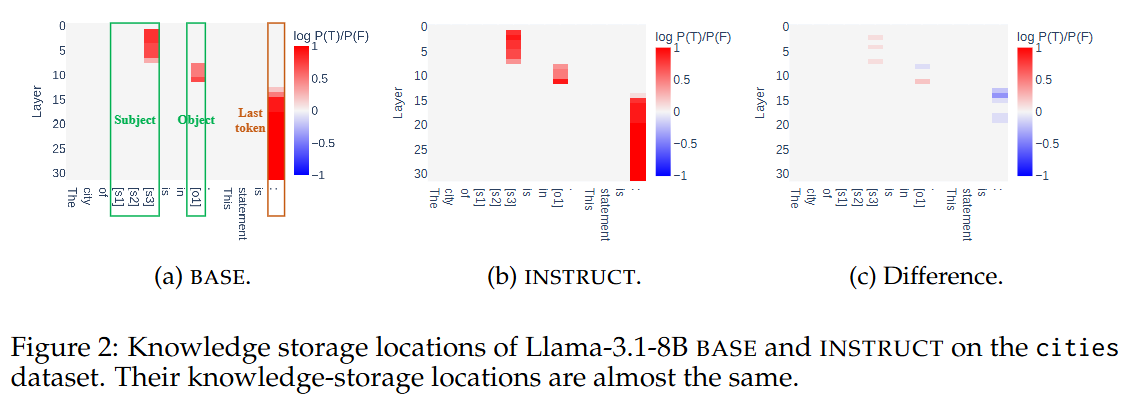
- 피어슨 상관계수도 1에 가까움
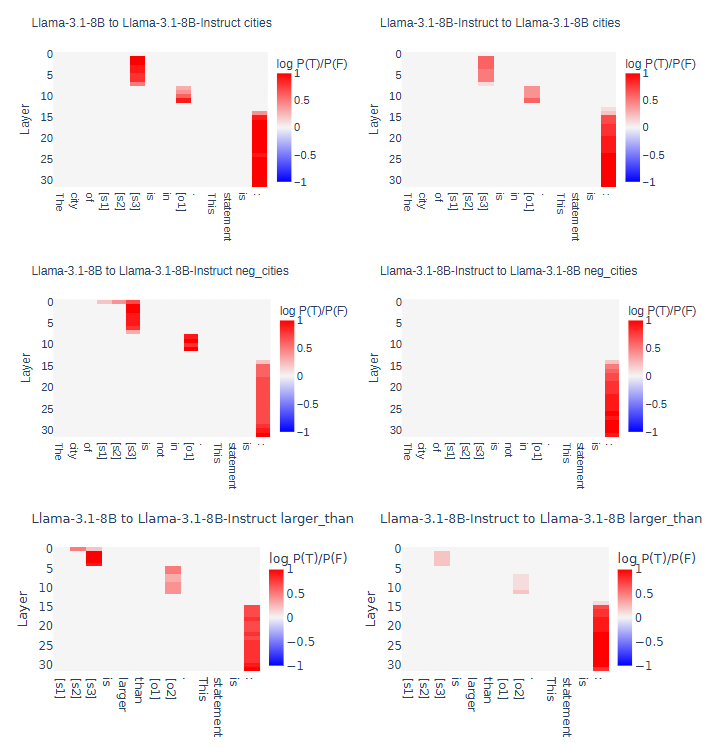
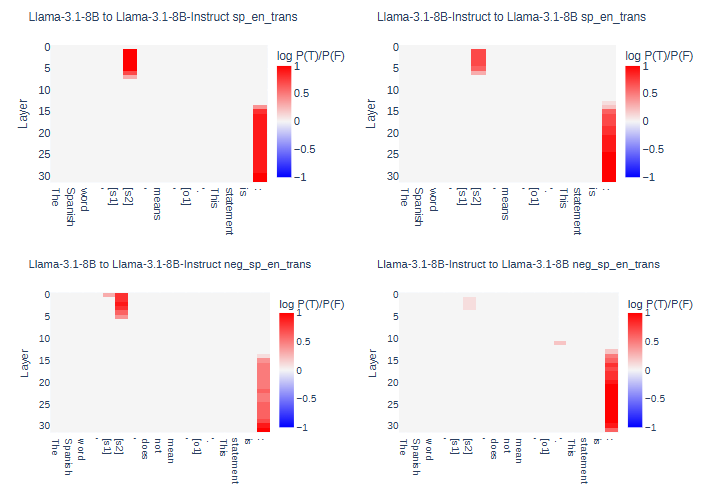
Base → Post 의 representation 패칭은 (거의) 항상 잘 되는데 역은 종종 실패함!
- 한 모델에서 token 의 layer 번째의 hidden state를 다른 모델의 같은 자리에 적용했을 때 잘 되는지 실험
- Base→Post는 잘 되는 경우가 많은데, Post→Base는 잘 안될 때가 좀 있음
- 이 현상은 모델 종류(Llama, Mistral), 사이즈(8B, 13B)에 상관없이 관찰됨
Internal Belief of Truthfulness
- 내부 truthfulness 방향이 유지되는지 확인하자!
- 유지되면 좋은것
실험 세팅
- 이번엔 참문장하고 거짓문장 사이의 hidden state 차이로 truthfulness 방향성 계산
-
- 여기서 는 마지막 토큰을 씀!
- 은 truthfulness가 가장 강하게 인코딩되는 layer 선택
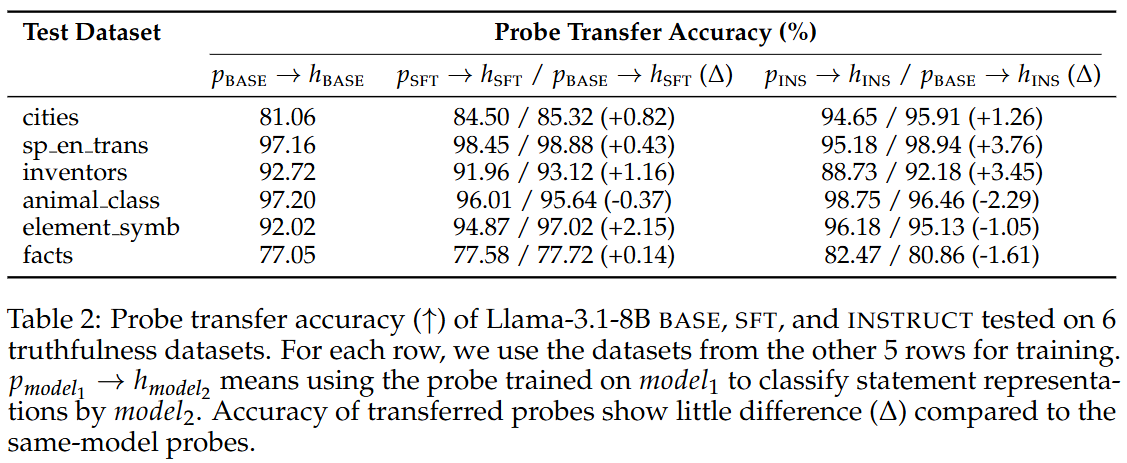
Post-training 이후에도 내부 truthfulness 방향은 유지됨!
- 모델별 끼리 코사인 유사도 계산해보니까 엄청 비슷함

- Base 모델의 truthfulness 방향성으로 참거짓 분류기만들어서 SFT, Instruct 모델에 적용했을 때,
잘 함
- Base모델의 Truthful 방향으로 SFT 모델과 Instruct 모델에 steering해도 잘 먹힘!
Refusal
- 내부 refusal 방향이 유지되는지 확인하자!
- 유지되면 안 좋은 것 (refusal 잘하도록 하는게 post-training이기 때문)
실험 세팅
- , 를 이용해서, truthfulness와 마찬가지로 이번엔 refusal 방향 계산
- Refusal을 유도할 때는 가장 강하게 작동하는 layer 에서 hidden state에 refusal 방향을 더함
-
- Refusal을 감소할 때는 모든 레이어에서 refusal 방향을 뺌
-
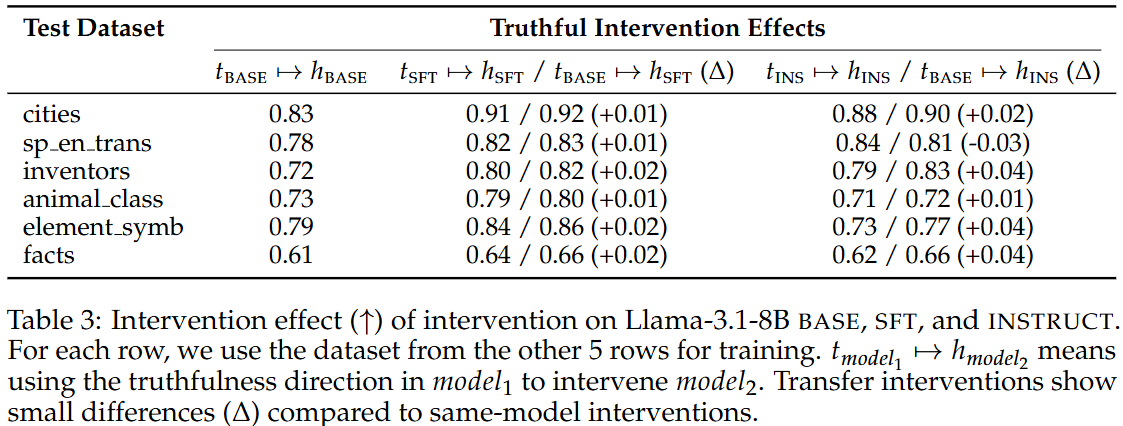
Post-training하면 내부 refusal 방향이 바뀜!
- Base모델하고 SFT, Instruct 모델의 refusal 방향 끼리 유사도 낮음
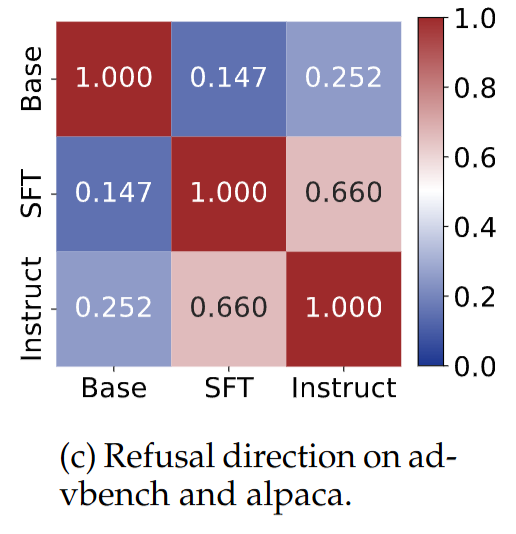
- Base모델의 refusal 방향성으로는 steering 잘 안되는데, SFT, Instruct모델의 방향성으로는 steering 잘 됨

Confidence
- Post-training하면 base모델하고 다른 confidence를 가지게 됨(토큰 생성 확률 스케일이 보정됨)
- 그리고 모델 내 엔트로피 neuron이 confidence를 조정한다고 알려짐
- 이 뉴런들은 가중치(weight norm)이 크고, unembedding matrix와의 composition이 낮기에,
확률 분포의 순위는 바꾸지 않으면서 스케일을 조절함
- 이 뉴런들은 가중치(weight norm)이 크고, unembedding matrix와의 composition이 낮기에,
실험 세팅
- 엔트로피 neuron들을 식별하자!
- 마지막 MLP layer의 각 뉴런에 대해, 출력 가중치 을 unembedding matrix 로 vocab space에 projection해 logit attribution을 계산함
- 이 projection은 해당 뉴런이 최종 예측 logit에 미치는 영향을 근사함
- 그리고 projection의 분산 LogitVar 계산
-
- LogitVar가 낮다는 것은 특정 토큰을 밀어주는게 아니라 어휘 전체에 대해 가중치를 부여함
- 엔트로피 neuron은 보통 LogitVar는 낮고 weight norm은 큼
- Weight norm이 가장 큰 neuron 상위 25%를 선택하고, 그 부분집합에서 LogitVar가 가장 낮은 10개
neuron을 마지막 MLP 층의 엔트로피 neuron으로 식별
- Weight norm이 가장 큰 neuron 상위 25%를 선택하고, 그 부분집합에서 LogitVar가 가장 낮은 10개
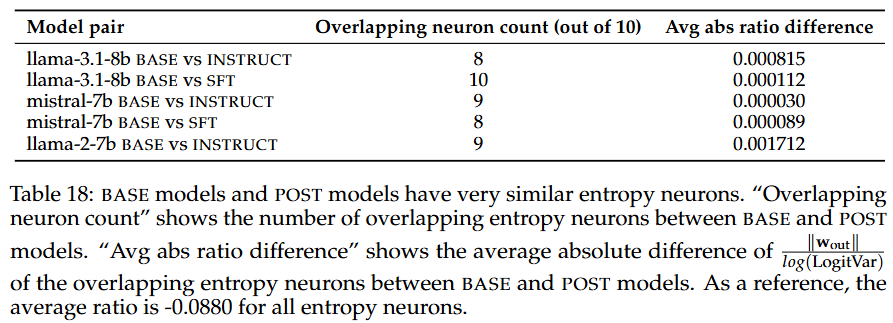
Post-training해도 엔트로피 neuron은 크게 안바뀜!
- 엔트로피 neuron들 대부분이 십중팔구(진짜임) 겹침
- 그리고 각 neuron들의 영향도 비슷함
- Weight norm과 LogitVar 분포로 봐도 Post-training 전후는 비슷함
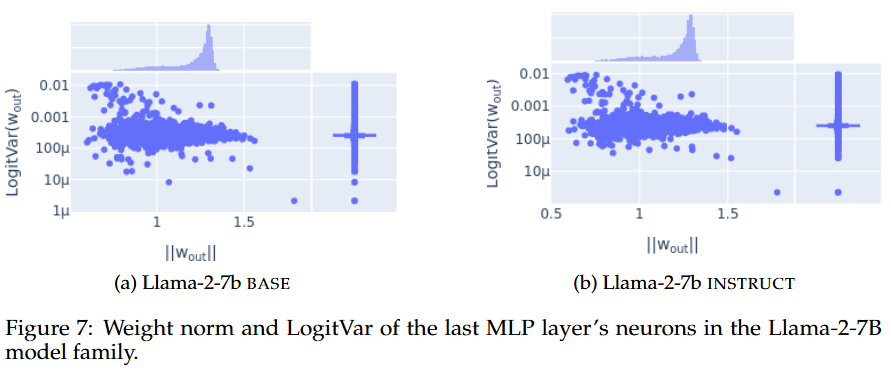
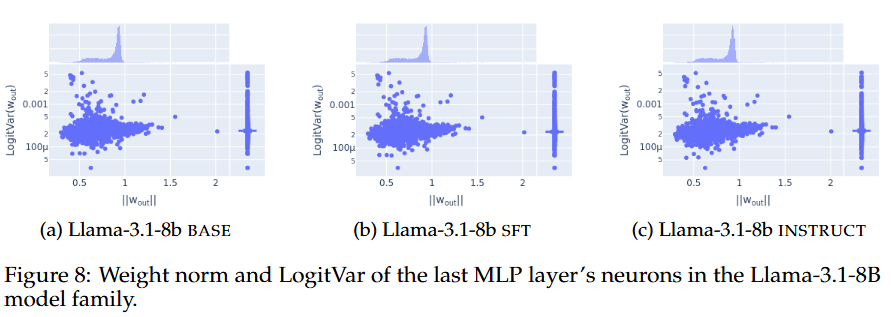
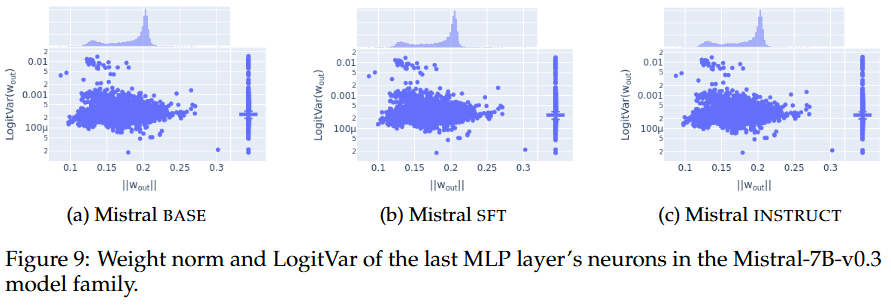
- 결국 엔트로피 neuron은 post-training 이후에도 크게 변화하지 않으니, confidence는 다른 디테일에서의 변화에서 기인되는 것!
- 다른 정교한 해석이 필요함