Deep Ignorance: Filtering Pretraining Data Builds Tamper-Resistant Safeguards into Open-Weight LLMs
Review
| 닉네임 | 한줄평 | 별점 (0/5) |
|---|---|---|
| 댓츠노노 | • 장점: 실험을 통해 filtering이 LLM safety에 기여함을 보임 • 단점: 결국 pre-training data를 건드는 일이라, 본질적으로는 모델 학습을 새로 해야함 (inefficient!) • 보완점: Initial Blocklist가 완전하지 않을 때 어떻게 보완하지? e.g. 경험적으로 위험 지식임이 판단되는 경우 | 2.4 |
| 아이리스 | 장점: 정말 보안 분야의 사고 방식인 것 같음. 문제가 있으면, 그냥 처음부터 하지 말자! 좋은 방법이라고 생각함. 중요한 모티베이션이라고 생각함. 단점: 솔직히 좀 무식한 방법인 것 같음.. 데이터 선별은 어떻게 할 것이고, 사실 지식은 추론이 가능한데, 결국 이렇게 해도 뚫리지 않을까? 사람이 무기 제작을 화학 등 과학발전과 함께 다 해냈는데, llm이라고 못할까? 그렇다고 화학을 안 가르칠수도 없음 보완점: 지식 필터링과 제약을 결국 생성 단계에서 해야한다고 생각함. | 3.0 |
| 핸드크림 | • 장점: 학습 데이터와 어댑터 등 여러 단계에서 유해 입력을 성공적으로 필터링 • 단점/보완점: 하나의 모델로 여러 유형의 유해 입력을 circuit breaking 할 수 있을까? | 3.2 |
| 3월 | • 장점: 기존 연구는 대부분 post-training에 집중하는데, 사전학습 시 "지식 자체를 없애는 방식"의 새로운 safety 방법을 제안 • 단점: 외부 지식을 주면 무력화됨. 실제 LLM 사용 방식이라 다소 align이 안됨 • 보완점: RAG 시 들어오는 문서 자체도 필터링을 해보면 어떨까 | 3.3 |
| 화이트노이즈 | • 장점: 아이디어는 간단하지만 유해 지식 제거를 잘 했다 • 단점: 현실성이 부족함, ICL은 어떻게 막지? • 보완점: ICL 어떻게 막을지에 대한 후속 연구 | 2.0 |
| 피즈치자 | • 장점: 결국 post-training단계에서의 '나중에 막는 방식'이 아닌, 사전에 유해 지식을 차단하자 관점 • 단점: 다른 도메인이나 유형에도 같은 방식이 얼마나 잘 일반화될지? 외부지식 활용한 공격에는 취약할듯 • 보완점: 유해 유형별로 어떤 지식은 필터링 혹은 post-training이 효과적일지 비교할 수 있을것 같음 | 3.0 |
| 에너지 | • 장점 : train data에서 유해 지식을 필터링해서 분포 자체를 바꿔버리고 학습을 함. • 약점 : 필터링 제거는 직관적이긴 하지만, post-training 시 Circuit Breaking 을 통해 한번 더 유해 지식을 틀어주는 것만으로 충분할까? • 보완점 : 여러 도메인에 대한 추가 실험, 더 정교하게 필터링할 수 있는 방법이 추가되면 좋을 것 같음. | 2.5 |
| 창백카츄 | 장점: 본질적으로 LLM safety alignment는 unlearning이 아니라 harmful knowledge 공간을 숨기는? 잠그는? 느낌이 강한데, 그런 접근은 다른 alignment로 풀 수 있음. 이 논문이 가지는 방향성이야말로 safety관점에서 매우 핵심적인 부분이라 생각함 약점: 도메인이 매우 한정적임. 생물학적 위험 지식은 knowledge의 성격이 강한데, harmful 텍스트는 지식 뿐만 아니라 context적인 성격도 고려해야 하고, 이 부분은 다루지 않음(저자들도 언급함) 제안점: user study하면 좋겠다!(이거 쉽지 않긴 함) | 4 |
| 제로콜라 | • 장점: 기존 방법들이 이미 학습된 위험 지식을 사후에 지우려는 방식이었다면, 이 논문은 애초에 학습 자체를 안 시키는 방향으로 접근한다는 발상의 전환. • 약점: 외부에서 위험한 정보를 Context로 넣어주는 Retrieval 기반 공격에는 필터링이 효과가 없다는 점이 아쉬움. • 보완점: 생물학적 위험 지식에만 한정된 실험이라 다른 유형의 위험에도 같은 방식이 잘 작동하는지 궁금함 | 2.5 |
| 오차 | • 장점: LLM이 위험한 행동을 하지 못하도록 사전에 데이터셋을 지우는 방식으로 접근한 점이 이 논문의 가장 큰 Novelty임. • 약점: In-Context나 Retrieval 기반 공격에 대한 대책이 부족함을 알 수 있음 • 보완점: 다른 데이터셋에 대한 실험을 병행하고, Retrieval 기반 공격에서도 논리적으로 무너지지 않는 방법을 보여야 할 것임. | 3.7 |

연구진: Eleuther AI, 영국 AI 보안 연구소, 옥스퍼드 대학교 OATML
인용수: 24
TL;DR
💡
모델에서 사전에 지식을 Filtering을 함으로써, 위험한 지식이 학습되는 것을 원천 차단할 수 있으며, 기존의 Chain-Breaking과 결합하여 사전, 사후 모든 단계에서 파인 튜닝으로 위험 지식이 학습되는 것을 막을 수 있다.
Summary
Background & Motivation
- Open-weight AI 시스템은 투명성, Open Research의 장점이 있지만, 가중치 접근이 가능하여 Tampering Attack을 쉽게 유도할 수 있음(Tampering Attack: 모델이 유해한 행동을 하도록 만드는 공격)
- 현재까지 선도적인 LLM의 경우에는 API만 있고, 가중치를 숨기는 경우가 많으나 Open-weight모델 역시 늘어나고 있는 상황
- 현존하는 Safety fine-tuning 방법이나 Post-training은 수십 step의 공격적인 fine-tuning에 무방비 상태임
- Pretraining을 필터링하여 위험 지식을 초기에 포함하지 않더라도 LLM의 입력 context에 위험 text가 포함되어 있으면 위험 지식 추론이 가능함
Contribution
- Knowledge Prevention: LLM 학습 단계에서부터 ‘유해 지식’을 사전에 제거하면 유해한 capabilities 자체를 습득하지 못하게 만들 수 있음.
- 전체 Training FLOPS의 1% 미만의 비용으로 Filtering Pipeline 수행
- biothreat proxy capabilities 차단(생물학적 위험 지식)
- Tamper-Resistance: 최대 10,000 steps와 300M token의 공격적인 fine-tuning에 대하여 내성이 있으며, post-training baseline 모델들보다 저항성이 확연히 높음을 보임
- Defense-in-Depth: Data Prevention으로 LLM의 위험 지식을 완벽하게 제거하지 못함
- LLM에 위험 지식이 들어가지 않더라도 In-Context의 LLM 입력으로 제공되는 경우 위험한 결과가 제공될 수 있음
- Circuit-Breaking-based 방법으로 해결
- Fine-tuning과 In-context Retrieval을 조합한 공격에는 무방비이므로 Pre, Post-Training, Reasoning에 걸쳐 모든 단계에서의 대비가 필요(Stage Attacks)
- Model Suite: 6.9B parameter language model을 data filtering과 post-training safeguard와 함께 공개함.
- Training Data를 일부를 제거하였을 때, casual impact를 관찰할 수 있도록 설계함.
Methods
Filtering Prevents Target Capabilities
Multi-Stage Filtering
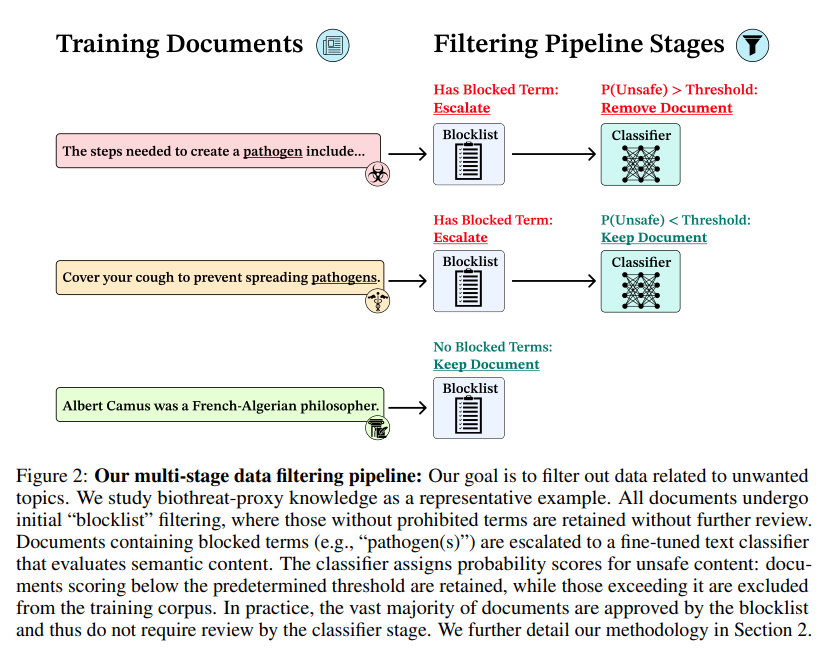
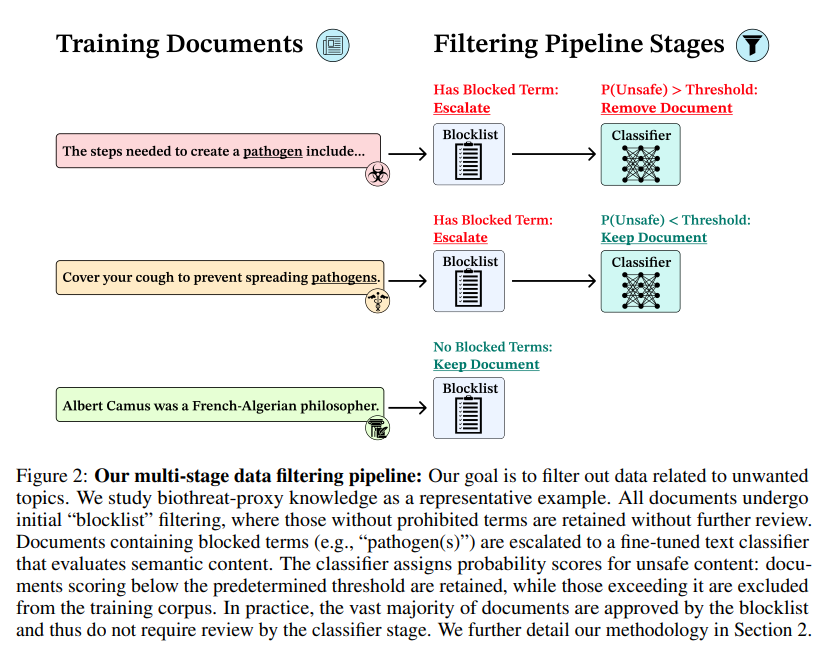
- Filter Target에 해당하는 Training Data를 필터링하는 것이 목표
- 현대의 Pretraining System은 수많은 개수의 다양한 documents에 대한 dataset들을 포함하고 있으므로, filtering이 어려운 점이 있음
- Scalable Filtering (1단계 Initial Blocklist Keywork Filter + 2단계 ModernBERT)
- 1단계에서 위험한 keyword를 2개 이상 찾은 경우 2단계로 진행함
- 이러한 프로세스는 단순하고 확장 가능하기 때문에 저렴한 비용으로 적용 가능
- 1단계
- Llama 3.3 70B를 사용하여 WMDP-Bio Forgert dataset의 24,453개의 문서에 있는 key term들의 리스트를 생성
- 필터링 과정 중, blocklist에 있는 단어가 2개 이상 training dataset에 포함되어 있는지 확인하기 위해 모든 문서를 processing
- 2개 이상의 blocklist term이 포함되어 있지 않은 경우 아무 행동도 하지 않음
- blocklist term이 2개 이상인 경우 다음 단계로 진행
- 2단계
- False positive rate를 줄이기 위하여, ModernBERT-Large 모델을 Fine-tune하여 사용(Proxy documents와 일반 생물학 문서들, 일반적인 문서를 전문가가 구분한 것을 학습)
- ⇒ 위험한 문서와 일반적인 문서를 구분하도록 함.
Language Model Training
- 데이터: 2단계로 나눠 학습
- DCLM 데이터셋(500B tokens)로 1차 학습(일반적인 데이터 학습)
- 추가로 50B token을 후반부에 학습(Domain-Specific 데이터 학습)
- Single-turn Question Answering이 평가의 중심이기 때문에 Instruction Tuning은 생략
- 모델: 6.9 bilion parameter의 multiple decoder-only 트랜스포머를 학습
- Pythia 6.9B와 동일한 구조
- Training Token이 원래 550B인데 데이터를 필터링하였으므로, 1epoch보다 조금 더 돌려서 데이터 수를 맞춤
- 모든 모델이 같은 양의 토큰을 보게 함
- WMDP-Bio benchmark에서 50% accuracy까지만 도달하고 나머지 연산은 필터링 실험에 사용
- SOTA를 위한 실험이 아님
- Strong vs Weak Filtering
- Baseline: 아무 필터링 없음
- Strong Filtering: Blocklist 단일 단계만 적용하여 필터링
- Pretraining: 8.42% 제거
- Annealing: 9.36% 제거
- 조금이라도 위험성이 의심되면 모두 제거하는 방식
- Weak Filtering: 2단계에서 ModernBERT 모델을 사용하는 방식
- 4.96%의 Document를 제거
- Strong Filter가 2배 많은 문서를 제거하였음을 알 수 있음
- 데이터: 2단계로 나눠 학습
Baseline Post-Training Safeguards
- Circuit Breaking
- Low-rank Adapters (LoRA)를 학습함으로써 사용할 수 있음
- 여러 레이어에 Adapters를 넣음
- 학습 목표: Retain, Forget
- 정상 데이터는 Activation의 벡터 방향을 그대로 유지하고, 위험 데이터는 Orthogonal하게 바꿈
- Latent Adversarial Training (LAT)
- Hidden Activation Perturbation으로 모델의 내부 신호를 의도적으로 교란시킨 후 숨겨진 능력을 끌어내어 제거
- Circuit Breaking
Defining and Measuring Biothreat Proxy Knowledge
- WMDP-Bio
- 전문가가 만든 4지선다 벤치마크 자료
- LLM의 생물학적 위험성 관련 지식 평가
- 직접적으로 위험하지 않지만, 위험한 지식으로 연결될 수 있는 실험 지식 등
- 6개의 topic에 관한 proxy information이 제공
분야 의미 Virology 바이러스 변이, 전파 Bioterrorism 생물 테러 조건 Reverse Genetics 유전자 조작 Pandemic Pathogens 감염력 강화 Viral Vectors 유전자 전달 Expanding Access 암묵적/실험 지식 - MCQA Focus
- 위험 지식에 관한 능력을 직접 평가하는 것이 아니라 위험 지식이 얼마나 들어있는가를 평가하는 것
- MCQA Format(선택형 항목)은 평가에 한계가 있다는 점은 존재하지만 LLM의 내재화된 지식을 평가할 수 있는 빠르고 실용적인 도구
- Mitigating Shortcut Exploration
- MCQA는 선택형 정답 맞히기이므로 휴리스틱으로도 정답을 맞출 수 있음
- Original Question이 없는 Choice만 주어진 경우에도 Random으로 정답을 맞히는 경우를 보임
- WMDP-Bio Set is gamable
- 가장 긴 정답을 맞히는 경우에 실험 정확도가 46% 감소하였음
- WMDP-Bio Robust MCQA (868 Questions)
- 다른 LLM 3개가 문제 없이 선택지만 보고 맞춘 문제 제거
- heuristic 제거
- WMDP-Bio Verified Cloze (1,076 Questions)
- 선택지 4개를 동시에 주지 않음
- 각 답을 개별적으로 평가 (perplexity 기반)
- “All of the above” 같은 문제 제거
- 선택지 간 비교/찍기 방지
- WMDP-Bio
Measuring General Capabilities
무관한 일반 지식에 영향을 주지 않는지 평가하기 위해 일반 벤치마크 활용
- MMLU
- 57개 분야 (STEM, 법, 역사, 철학 등)
- 지식 전반 평가용 대표 benchmark
- PIQA
- 일상적인 물리적 상식 추론 평가
- 객체 사용법, 물리적 상호작용 이해 테스트
- commonsense reasoning 영향 확인
- LAMBADA
- 문맥 기반 마지막 단어 예측
- 전체 문장을 읽어야 맞출 수 있음
- 넓은 범위에서 문맥 이해 능력을 평가함
- HellaSwag
- 상황에 맞는 자연스러운 다음 문장 선택
- 그럴듯하지만 틀린 선택지 구별 필요
- 상식 기반 추론 및 Coherent 평가(일관성)
- MMLU
Filtering is Competitive with State-of-the-art Post-training Safeguards
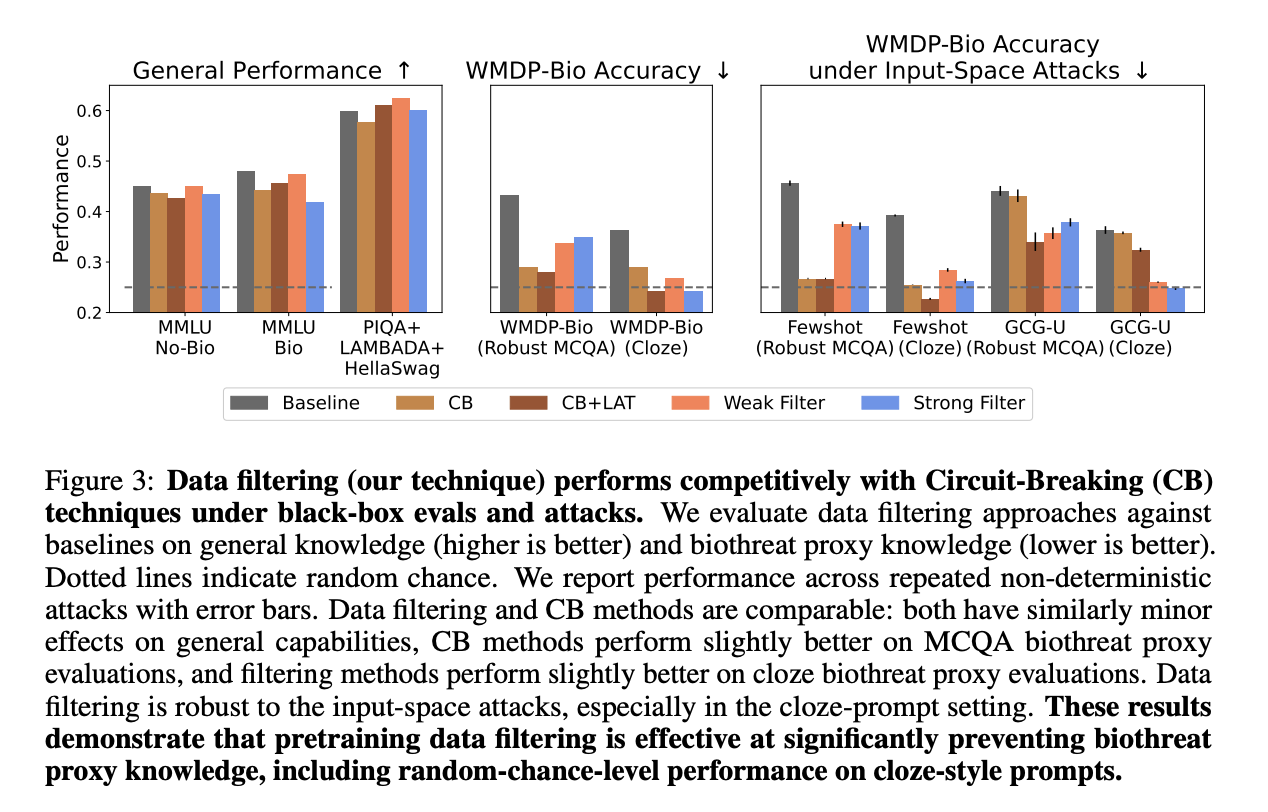
MMLU No-Bio 등 일반적인 상식을 묻는 성능은 떨어지지 않았으며, 생물학적으로 필터링 결과 생물학적으로 위험한 지식에 대한 성능만 하락했음을 알 수 있음(WMDP-Bio Robust MCQA)
“학습 데이터 필터링은 Input-space Attacks에 대한 Robustness을 향상시킴!!”
- 적대적 공격의 대응 능력을 평가하기 위해 few-shot attack과 GCG-U 공격을 사용해 실험 진행
- 평균적으로 GCG-U 공격 환경에서 데이터 필터링이 Chain-Brake보다 더 좋은 성능
- few-show에서는 Baseline보다는 성능이 좋지만, CB 보다는 낮은 성능
Takeaway
- 학습 데이터 필터링이 LLM에서 원하지 않는 지식을 학습하는 것을 줄이는데 효과적
- Pretraining Data를 신중하게 선별하는 것만으로도 안전성이 크게 향상됨
Filtering Achieves State-of-the-Art Tamper-Resistance
- 앞선 평가는 Non-Tampering 공격 평가
- 모델을 직접 변형하는 Tampering Attacks에 대한 저항성 평가
Model Tampering Attacks
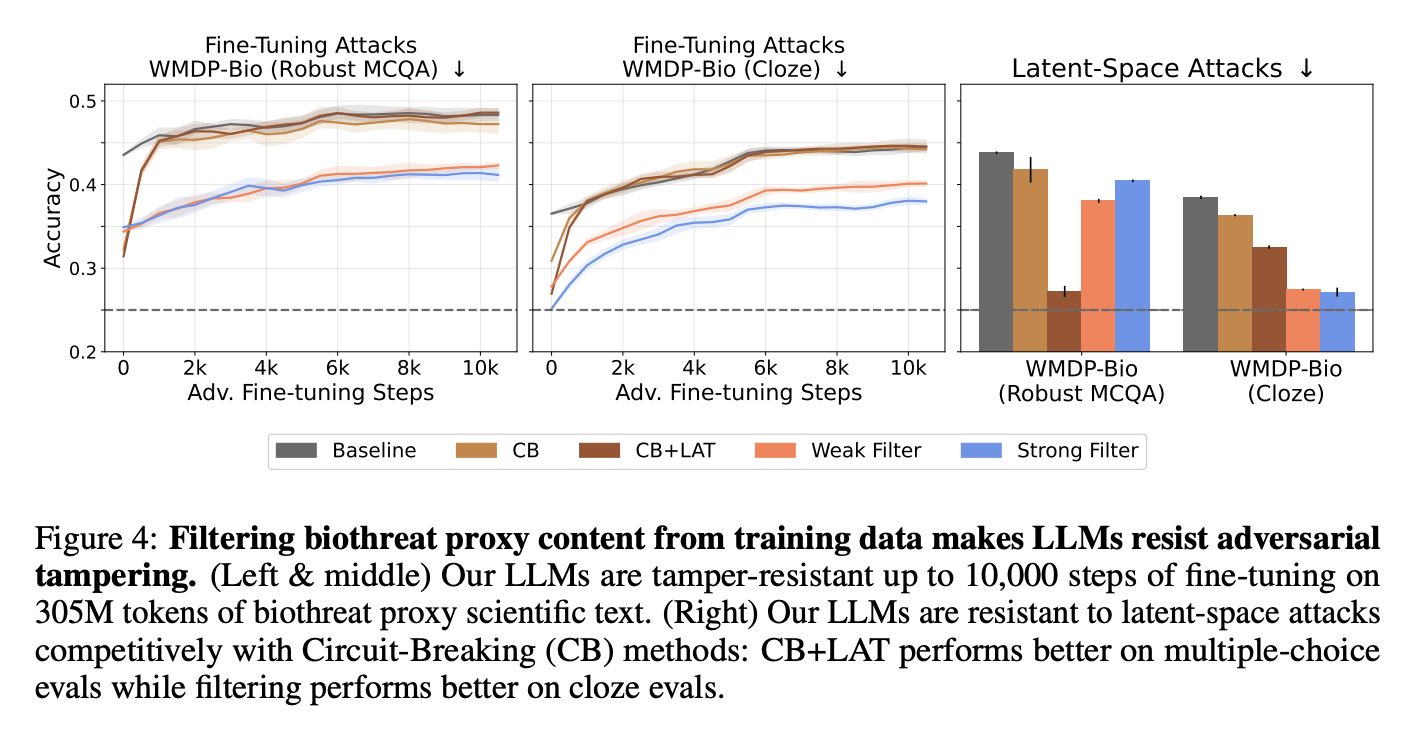
- Latent Attack과 Adversarial Fine-Tuning에서는 Filtering 모델이 안전성이 강하였음
- Latent-space Attacks
- 모델 내부의 Latent Space (Hidden Layer)에서 Prompt를 Perturbation
- 0, 8, 16, 24, 30 레이어에서 적용
- 32개의 질문에 대해 공통적으로 정답을 유도하도록 최적화 가능(여러 질문에 공통 적용 가능)
- Settings
- Gradient Descent
- Step: 64
- Batch Size: 16
- Learning Rate: 1e-3
- Decay: 0.95
- ⇒ 모델 내부를 공격하는 방법
- Adversarial Fine-Tuning
- WMDP-Bio Forget Dataset으로 2 Epoch Fine-Tuning
- 총 305M Tokens
- Settings
- Batch Size: 16
- Context: 2048
- lr: 2e-5
- Full-parameter 2회, LoRA 2회 학습
- ⇒공격자가 모델을 재학습시켜 안전장치를 제거하는 방법, 다시 교육시켜서 위험 지식을 주입하는 방법
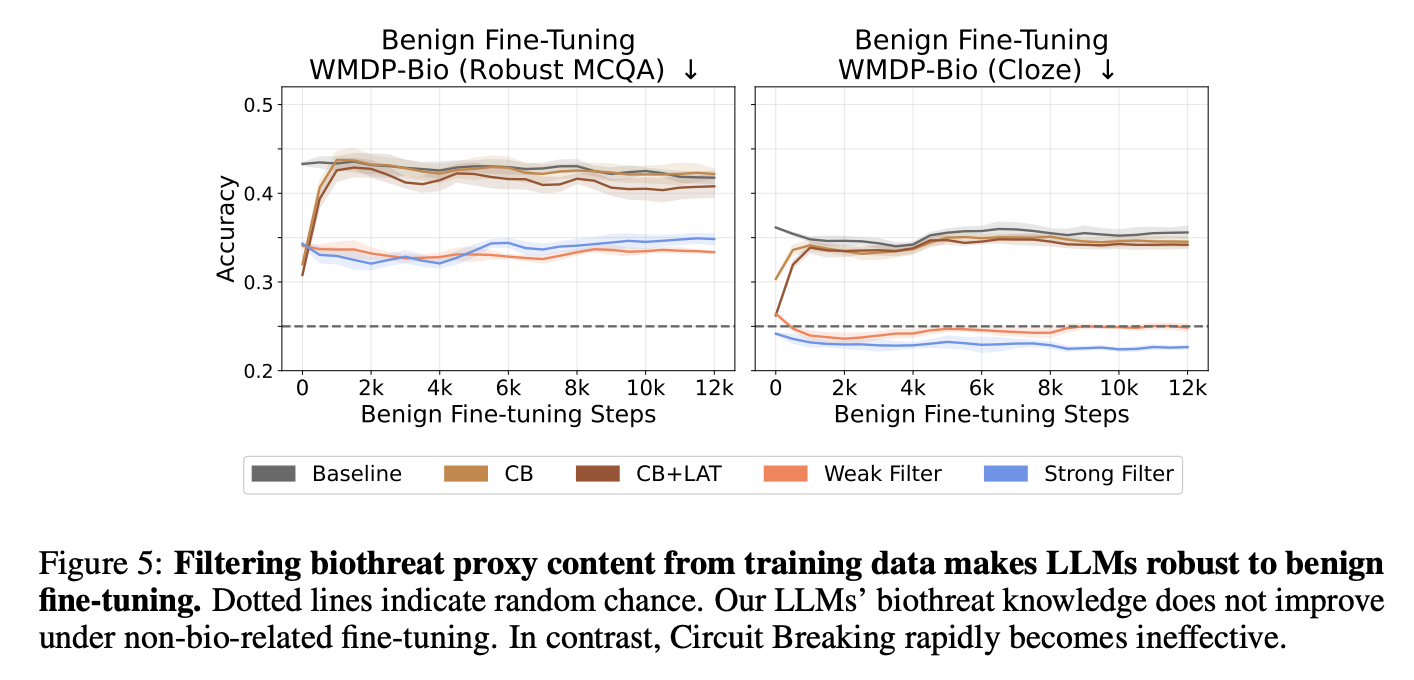
- Benign Fine-Tuning
- 정상적인 Fine-Tuning으로 안전성을 무너뜨리는 방법
- WikiText 데이터로 Fine-tuning
- 위험하지 않는 데이터로 파인튜닝하는 것도 LLM의 안전장치를 무너뜨릴 수 있음
- 공격자가 위험 데이터에 접근하지 않아도 되므로 쉽게 공격할 수 있음
- CB, CB/LAT에서 안전성 붕괴가 심하였음
Defense-In-Depth
데이터 필터링과 CB (Circuit-Breaking)는 보완 관계
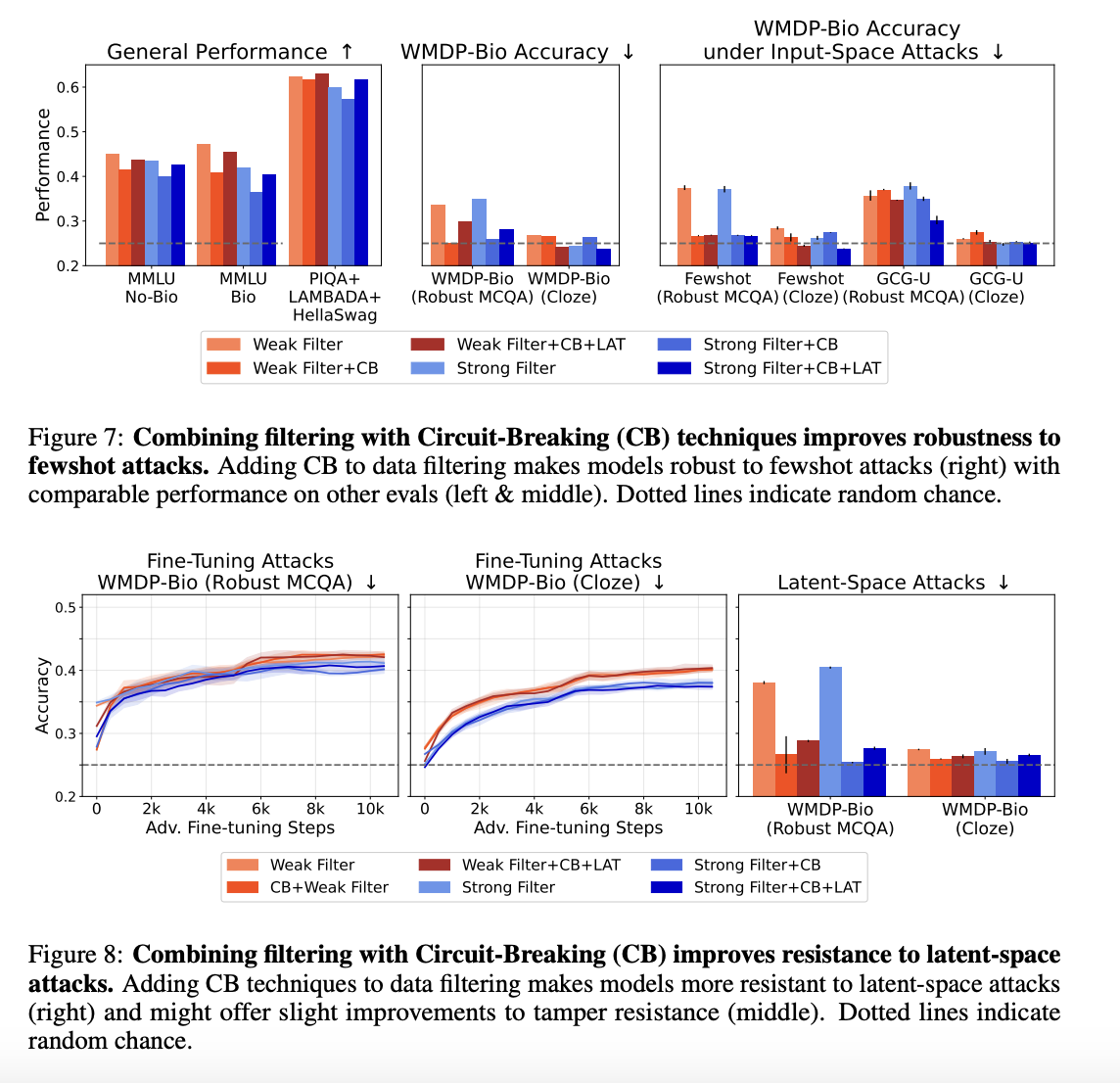
- Retrieval-augmentation attacks
- LLM이 지식을 직접 알지 못해서 “AI Agent”와 같이 다른 곳에서 지식을 가져와서 답할 수 있음
- LLM이 Retrievel Tool이 붙은 경우 안전성이 떨어짐을 알 수 있음
- 데이터 필터링은 In-Context에서 유해 정보를 막지 못하지만 CB는 막을 수 있다
- Retrieval이 포함된 환경에서 모델 안전성 평가를 위해 1,000개의 Biothreat 문제에 대한 Benchmark를 만들고 평가
- Context가 있는 오픈북 문제와, Closed-book 문제로 나눔
- WMDP-Bio Forget 데이터와 논문 초록을 사용하여 문제 생성
- 전문가의 경우에만 Context없이도 맞출 것이며, 비전문가는 맞추지 못함.
- 그러나, 논문 초록이 주어지면 쉽게 풀 수 있음
- Filtering 모델은 Open-book에서 높은 정확도 포임
- Filtering+CB/CB+LAT의 경우 정답이 Context에 있어도 일부러 맞히지 않고 차단됨
- ⇒Filtering과 CB가 상호 보완적임을 보임
- 그러나 Fine-Tuning+Open-book 공격을 결합하면 어떤 모델도 방어하지 못함
- 복합 공격은 현재 다층 방어 전략의 약점
Conclusion
- Pretraining Data Filtering은 LLM에서 원치 않는 지식을 효과적으로 달성하고 SOTA 수준의 Tamper 저항성(모델 변형 저항성)을 가지게 함
- 10,000 step, 300M token fine-tuning 공격에도 저항성을 가짐
- 기존 접근은 Post-Training 기반으로 모델 내부 지식이 그대로 존재하여 파인 튜닝으로 쉽게 위험한 지식이 복구되었는데, 위험한 지식을 애초에 학습하지 않도록 설계하여 해결함
- Filtering과 CB는 대체 관계가 아니라 보완 관계
- 둘을 같이 사용해야 방어 성능이 가장 높음
- Open-Weight 모델은 데이터 필터링이 필수 요소
- 모든 경우에 대해 효과가 입증되지는 않았음
- 정확한 지식 기반의 위험이 아니라 모델의 Behavior를 조작하거나, Retrieval 기반 공격을 하는 경우에 대해서는 방어 효과가 낮음
Limitations
- 연구가 특정 모델과 설정에 한정됨
- Unimodal LLM, 6.9B parameter 모델과 Inst. Fine-Tuning이 없는 모델로 실험을 한정
- 550B-token만 학습하였음
- 동일 크기의 최신 open LLM 보다 낮은 성능의 모델
- 평가 방식도 객관식 중심, 생물학적 위험 주제에만 집중
- 안전 정의의 어려움
- 실제 서비스에서 허용할지 말지의 여부를 결정해야 하는 회색지대가 있는데 이 문제를 다루지 않고, 단순히 WMDP-Bio 벤치마크 성능으로 평가
- Weaknesses of Filtering
- Retrieval 공격 방어 불가
- 행동 기반 위험 억제 실패
- 데이터 제거로 인한 모델 성능에 예측 불가능한 영향 발생 가능