The Dual-Route Model of Induction
Review
| 닉네임 | 한줄평 | 별점 (0/5) |
|---|---|---|
| 피땀 | • 강점: 뇌과학과 연관지어서 token induction 이외에도 concept(의미) level의 경로를 병렬적으로 사용한다는 점을 실제 여러 검증 실험을 통해서 둘이 같이 작동한다는 점을 증명해냄 • 약점: 솔직히 토큰 단위 이외에 의미 단위로 저장하는 attention head가 있을 것 같다는 아이디어 자체가 novelty가 있진 않아보임 • 보완점: 문장을 넘어서 좀 더 긴 문단 같은 경우에는 하나의 concept indcution head에 정보가 저장되기 힘들것같은데 여러 induction head에 정보가 분할되어 저장되는 경우는 없는지 궁금함 | 3.5 |
| 눈물 | • 강점 : attention head에 token-induction head 뿐만 아니라 concept-induction head도 존재함을 실험을 통해 검증한 연구. 특히 patching 관련 실험 설계를 잘한 것 같음. • 약점 : 복잡한 모델 구조를 token + concept 로 표현을 하는데, 다른 attention head의 영향도 있지 않을까? 생각이 듦. 또한, 다른 task에서도 patching을 적용했을 때, 같은 결과가 나오는지 미검증됨. • 보완점 : concept과 관련된 구조가 존재하는 건 보여주었으나, 완전한 설명(일반성)을 위해 추가 검증 실험이 필요함. (번역 말고 다른 task에도 activation patching이 성립하는지) | 3.8 |
| thumbs-up | • 장: 사람의 지식 습득 방식을 categorize하고, induction head을 활용하여 언어모델에 적용하고자 함. 흥미롭지만 추상적인 개념을 정의하고, 이를 논리정연하게 검증함. COLM다운 논문! • 단 & 보완: First-token accuracy만으로 개념 이해를 속단할 수 있을까? 왜 이런 metric을 설정했는지? | 4 |
| 파이어 | • 장점: Attention Head에서 Concept Head를 통해 유사한 단어가 정확하게 반복되지 않더라도 의미 기반으로 다음 token을 예측할 수 있다는 점을 잘 보여주었음. • 단점: Attention Head에 의미론적인 정보를 저장한다고 하는데, 어떤 mechanism으로 의미론적인 부분도 보게 되는지 설명이 부족한 것 같음. • 보완: 번역 이외에도 다른 task나, 다른 샘플들로 실험이 필요할 것 같음. | 3.8 |
| 웃으면서 보자 | 장점: 사람의 사고 방식이나 동작 방식을 실제로 확인하는 연구는 언제나 의미 있다고 생각함. ICL에 대해 사실 그냥 의미적 해석을 하지 랂는다고 생각했는제, 이걸 보면 어느정도 하는 것 같음. 단점: 레이어와 헤드가 가지고 처리하는 정보가 더 다양할 것이라고 생각하는데, 이렇게 하나하나 찾는게 의미 있을까라는 생각이 들긴 함. 뭔가 근본적으로 새로웠으면.. 보완점: 아무리 봐도 태스크마다 다 다를 것 같은데.. 입력에 따라도 다를 것 같음. 실제 iCL 해보면 잘 안되는 경우도 많고. 의미의 범위가 어디까지린지더 모르겠름 | 3.6 |
| 독수리오형제 | • 강점: 기존 induction head 해석이 주로 token-level copying에 머물렀다면, 이 논문은 concept-level route를 추가해 induction을 새로운 관점에서 해석함 • 약점: 해당 논문이 보여주는 실험의 범위는 주로 multi-token word / word-level translation이라 일반적인 '개념' 수준은 아닐수도 있을듯 • 보완/제안: 더 넓은 분야(reasoning, ..)에서도 dual-route 구조가 유지되는지 궁금함 | 3.8 |
| 팝콘 | • 장점: 의미 단위의 복사를 담당하는 attention head 발견 • 단점: token copier head와 concept copier head의 기능을 개념적으로 완전히 분리할 수 있는지 의문 • 보완점: token copier head와 concept copier head가 함께 기능하는 경우도 있지 않을까? 상관관계가 있달지, 이에 대해서 더 분석하면 좋을 것 같다 | 4.2 |
| 삐질 | • 장점: 인지 이론에서 영감을 받아 LLM이 텍스트를 복사할 때 토큰 단위/의미 단위의 2가지 경로를 활용한다고 해석한점 + 단순히 상관관계에 가까운 attention map을 정말로 head가 원인인지 아닌지를 판단하는 아이디어를 접목한 점이 interpretability 분야와 잘 맞음 • 단점: 문제 정의랑 태스크 자체가 번역, 유의어 탐지 등 copying에 한정되어있는데 concept head가 추론 태스크에도 중요한지 검증되지 않음 • 수학 추론 태스크에서 어떤 step에서 concept head가 중요한지 파악해보면 어떨까 | 4.4 |
| 초콜릿 | • 장점: LLM의 induction head가 토큰 단위와 의미 단위 두 가지로 나뉜다는 아이디어를 제시하고 실제로 해당 head가 원인임을 보여줌 • 약점: 실험이 번역, 동의어, 반의어 같은 태스크에만 집중되어 있어서, 더 복잡한 태스크에서도 같은 역할을 하는지는 알 수 없을것 같음 • 보완점: 긴 텍스트에서도 concept head가 동일하게 작동하는지 보여주면 좋을것 같다 | 3.9 |
| 덩쿠림보 | 솔직히 헤드가 몇갠데 당연히 크게 보는 애들도 있고 작게 보는 애들도 있는게 당연하다고 생각들긴 함. 그래도 sound 하게 실험하고, 번역 task에서 쉽게 떠올릴 수 있는 research question(토큰 길이가 다른데 어떻게 번역을 잘하지?)을 다룬 것은 좋은 듯!! pretraining 단계에서 어느 head가 먼저 학습되는지 보는거 재밌을 듯 | 3 |
- Cited: 14
- Github: https://dualroute.baulab.info/
- Related paper: In-context Learning and Induction Heads (Enthropic’22) | Cited: 899
TL;DRICL 능력의 핵심 메커니즘은 induction head 때문이고 2 layers로 작동한다!
TL;DR
💡
Induction head가 토큰 단위로만 복사하는 것이 아닌 의미 단위로도 복사하고, 토큰 단위와 의미단위 복사를 같이 사용한다.
Preliminary
In-Context Copying
정의prompt 안에 있는 패턴을 보고 그대로(or 의미 기반으로) 따라 생성하는 태스크- 새로 학습한 게 아닌, prompt 안에 있는 패턴을 보고 즉석에서 복사함!
- e.g.,
Input: A B C → D E F G H I → ???- In-Context Copying output:
J K L
- In-Context Copying output:
- 활용 분야
- 의미적 복사(concept copying)
- 번역 패턴 복사
Input: cat → 고양이 dog → ??? Output:개
- 번역 패턴 복사
- 의미적 복사(concept copying)
Induction Head
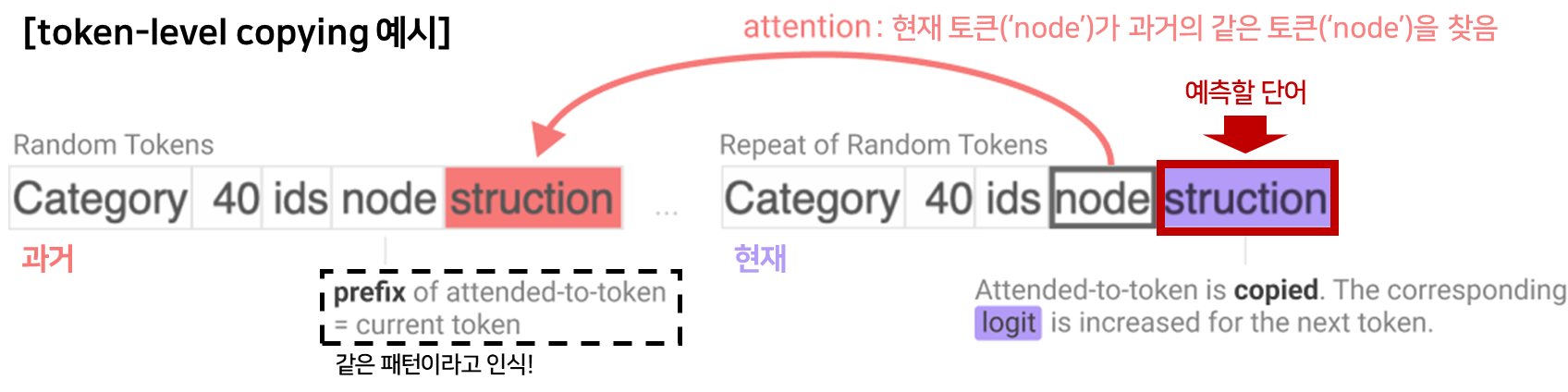
정의앞에서 본 패턴을 찾아 그 다음 토큰을 이어서 생성하게 만드는 attention head- 일반 attention head 와의 차이점
- attention head: 관련 있는 토큰을 참고
- induction head: 과거에 등장한 동일한 토큰을 찾아, 그 뒤에 이어졌던 토큰을 현재 위치에서 예측하도록 만드는 attention 패턴(특화된 Attention head)
- 일반 attention head 와의 차이점
- 작동원리
[A] [B] ... (다른 텍스트들) ... [A]- 모델이 현재 [A]를 읽고 있을 때, Induction Head 가 과거의 문맥에서 첫 번째 [A]를 찾아냄
- 과거의 [A] 바로 다음에 왔던 토큰이 [B] 였다는 사실을 Attention 함
- 결과: 다음 출력으로 [B]를 예측
⇒ 현재 토큰 → 과거 동일 토큰 찾기 → 그 다음 토큰 가져오기
- ⭐ 2-layer transformer 구조임!!
- 단일 Attention Head로만 작동하는 것이 아닌 두 개의 Attention Head Layer로 작동함
- next-token 정보를 hidden state에 저장해두고 그걸 꺼내는 구조
- 1st Layer
- 이전 토큰 정보 저장
- 현재 토큰이 바로 이전 토큰이 무엇인지 정보를 가져와 기억
- 뒷 층 헤드(실제 Induction Head):
- 현재 시점 토큰 [A]가 등장했을 때, 과거의 문맥을 뒤져서 똑같은 토큰 [A]를 찾고, 과거 [A]가 가지고 있던 바로 다음 토큰 [B]에 강한 어텐션(가중치) 부여
- 단일 Attention Head로만 작동하는 것이 아닌 두 개의 Attention Head Layer로 작동함
Activation Patching
- 모델 내부의 특정 활성화값(activation)을 조작해서 어떤 부분이 특정 출력에 얼마나 영향을 주는지 분석하는 기법
- 특정 뉴런/레이어가 특정 역할을 했는지 테스트하는 방법
- 단순 상관관계가 아니라, 해당 head가 실제로 출력에 인과적 영향(causal effect)을 주는지 확인하는 방법
- 특정 attention head가 어떤 역할을 하는지 분석할 때 사용됨
- 작동원리
- 모델에게 줄 2개의 입력이 있다고 가정
- 정상 입력 (clean input) → 원하는 정답을 잘 맞춤
- 오염된 입력 (corrupted input) → 일부 정보가 망가져서 정답을 못 맞춤
- 이때 특정 레이어나 뉴런의 activation을 오염된 입력의 실행 중간에 정상 입력에서 나온 activation으로 덮어씌우고(patch) 출력이 다시 좋아지는지 확인
- 성능이 회복되면 → 해당 activation의 attention head가 핵심 정보를 담고 있구나!!
- 성능 회복 안되면 → 다른 head를 알아보자..
- 모델에게 줄 2개의 입력이 있다고 가정
- 모델 내부의 특정 활성화값(activation)을 조작해서 어떤 부분이 특정 출력에 얼마나 영향을 주는지 분석하는 기법
Introduction
Background & Motivation
- 뇌 과학자들은 사람의 뇌가 무언가를 읽을 때 2가지 병렬 경로로 작동한다고 함
- 글자를 하나씩 해독하는 경로
sublexical(token)
- 단어의 의미를 전체 단위로 접근하는 경로
lexical
- 글자를 하나씩 해독하는 경로
- Token 기반 In-Context Copying의 문제점
- 사람에게 아래 두 문장을 외우라고 해보자!
- oane dnn t ephzawfeew eausr lthii → 뜻이 없기에 알파벳 별로 외우게 됨
token-based
- the false azure in the windowpane → 문장의 의미를 외우게 됨
concept-based
- oane dnn t ephzawfeew eausr lthii → 뜻이 없기에 알파벳 별로 외우게 됨
- 사람에게 아래 두 문장을 외우라고 해보자!
- 기존 induction head의 문제점
- 앞에서 본 패턴을 보고 다음 토큰 복사함 ⇒ 토큰 단위 복사임
- but, 번역 같은 느슨한(fuzzy) 복사 작업은 토큰 단위로 외우지 않고 concept 단위로 외움
- 번역을 하면 토큰 길이가 완전 달라지기도 하기 때문에 토큰 단위로는 설명이 부족함!
- e.g., potato (영어) → pommes de terre (프랑스어)
- 번역을 하면 토큰 길이가 완전 달라지기도 하기 때문에 토큰 단위로는 설명이 부족함!
RQ모델도 사람의 뇌처럼 토큰 단위 복사와 의미 단위 복사를 같이 할 수는 없을까?
Contribution
- token induction head 이외에 concept induction head도 존재함
- Token Induction: 토큰 단위 복사
- Concept Induction: 의미 단위 복사
복사 = token head + concept head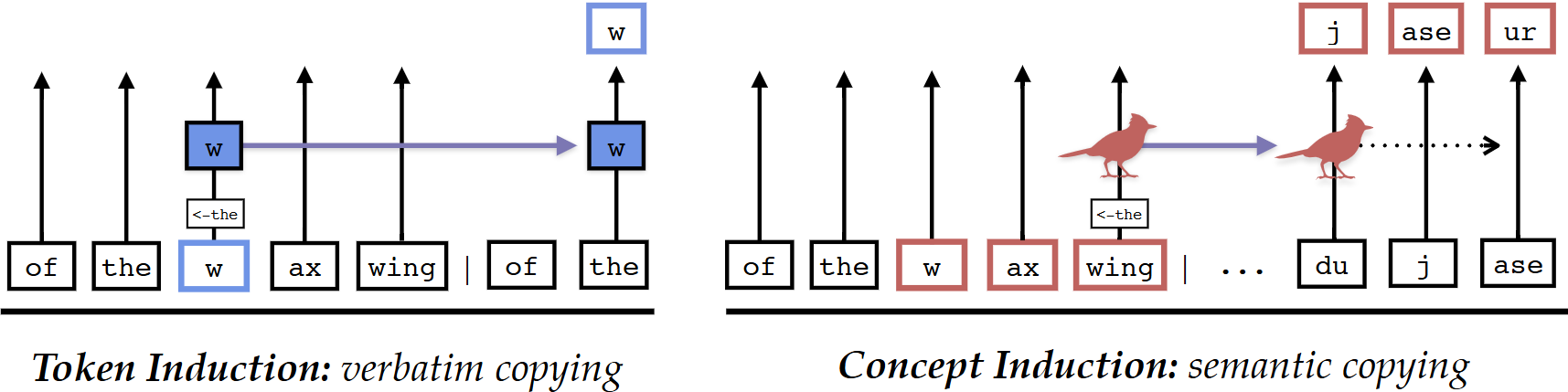
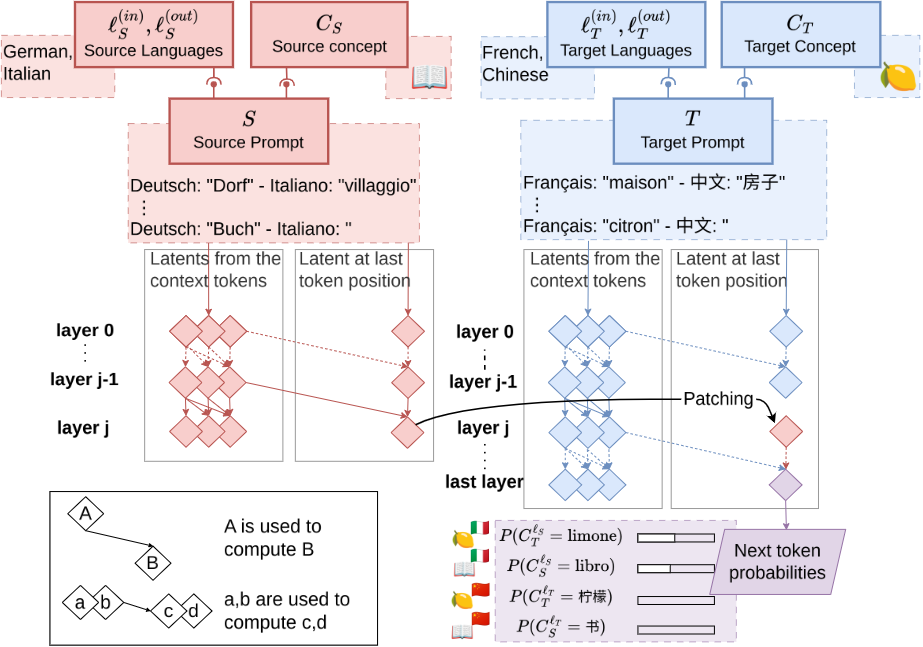
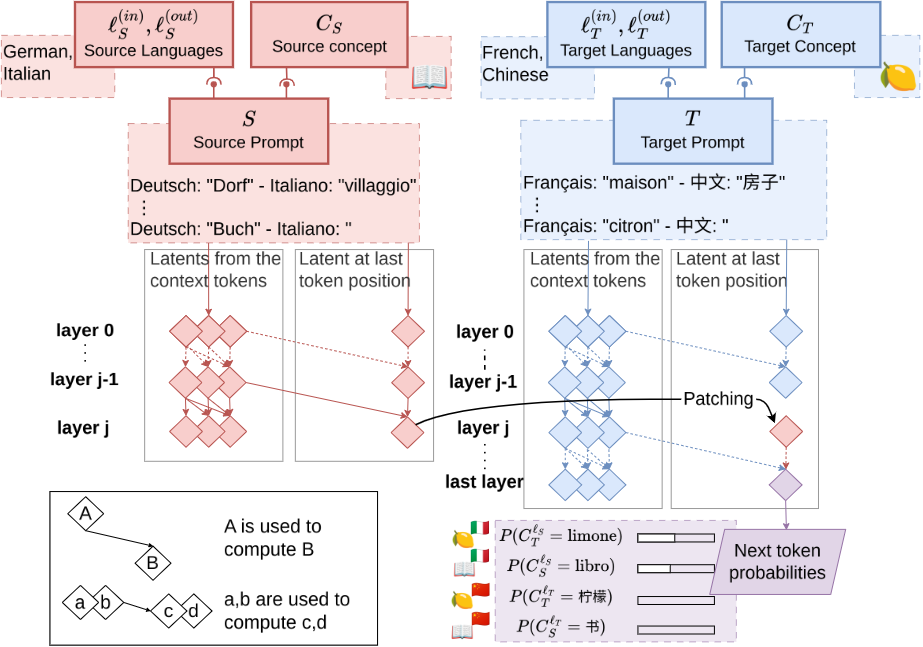
Concept Induction Head를 찾아보자
목표어떤 head가 token/concept 단위의 copying을 하는지 구분해보자- concept head를 찾기 위해, multi-token 단어를 복사하는 attention head를 causal intervention을 통해 찾음
- 특정 head가 multi-token 개념의 미래 토큰 확률을 증가시킨다면,
- ⇒ 해당 head가 전체 개념을 복사한다고 가정(패턴이 없는데도 복원이 되면 Concept-head 때문)
실험 과정(중요)
- 기본 induction prompt 만들기(기존 Induction Head 실험 셋업과 같음)
x1 x2 ... xn c1...cm | x1' x2' ... xn' c1'- 앞부분과 뒷부분이 거의 같은 반복 구조(
|는 newline)
- 끝에 multi-token 개념
c1...cm을 붙임
- 마지막 토큰은 항상
c1'(c1과 동일한 토큰)
- e.g.,
random_tokens... "Paul Cham bers" | random_tokens... "Paul" ↑ 마지막 토큰 c1'
- 모델 입장에서는
Paul다음에Cham이 와야 한다는 걸 앞 문맥에서 유추해야 함
- 앞부분과 뒷부분이 거의 같은 반복 구조(
- 두 개의 프롬프트 준비
- (Step1과 동일한 프롬프트):
x1...xn c1...cm | x1'...xn' c1' ← 앞뒤가 일치- (오염된 프롬프트):
y1...yn+m | x1'...xn' c1' ← 앞부분을 전혀 다른 랜덤 토큰으로 교체- 에서는 앞부분이 망가졌기 때문에, 모델이
c2를 예측할 단서가 없음
- Activation Patching: 에서 특정 head의 activation을 뽑아서, 의 같은 위치에 이식(patch)하고 실제로 예측이 되는지 실험(Preliminary 참고..)
- 만약 특정 attention head 의 activation을 이식했더니
c2확률이 올라간다면 → 이 head가 개념 복사를 담당한다는 증거가 됨..!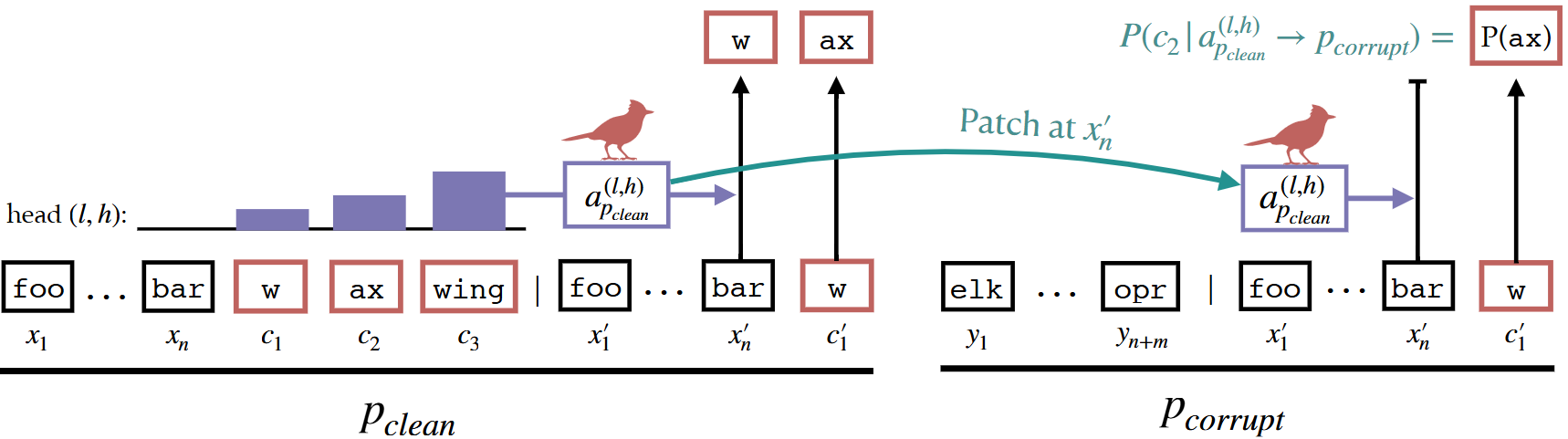
의 head를 의 head로 patching 하는 과정
- 만약 특정 attention head 의 activation을 이식했더니
- 2가지 Score로 평가
- (1) Concept Copying Score (개념 단위 복사):
c2는 개념의 두 번째 토큰 (e.g.," Cham")
- 이미
c1'("Paul")은 입력에 있으니,c2를 맞추려면 개념 전체를 기억해야 함
- Concept Copying Score가 높으면 ⇒ 개념 수준 복사 head
- (2) Token Copying Score (토큰 단위 복사):
- 개념 대신 랜덤 토큰 사용
r1(바로 다음 토큰) 예측에 집중
- Token Copying Score가 높으면 ⇒ 토큰 수준 복사 head (전통적 induction head)
- (1) Concept Copying Score (개념 단위 복사):
- 기본 induction prompt 만들기(기존 Induction Head 실험 셋업과 같음)
실험 결과
- 각 모델의 모든 attention head에 대해 causal score를 계산

사용한 모델 : Vocab size, : 학습에 사용된 총 토큰 수 - Head들의 위치 분포
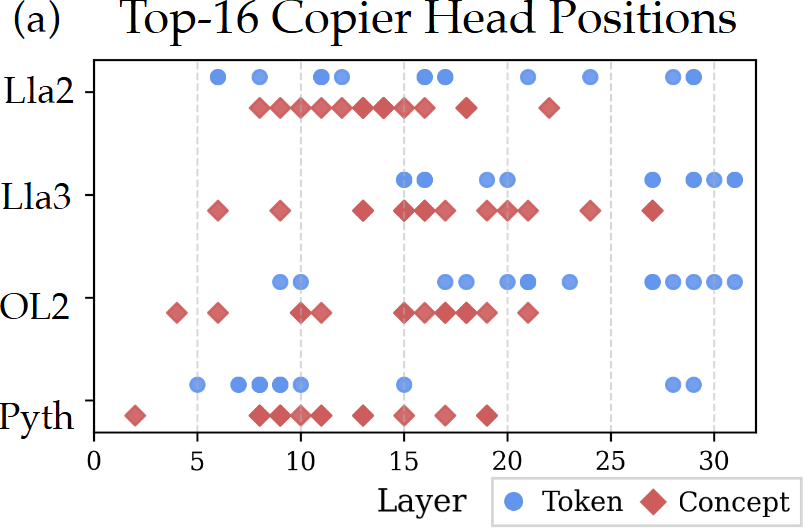
- Concept Copier Heads (🔶)
- 초중반 레이어에 집중되어 있음
- 의미 정보는 이후 레이어에서 활용되어야 하므로, 초반 레이어에서 미리 형성되어야 함
- Token Copier Heads (🔵)
- 산발적으로 분포, 특히 후반 레이어에 많음
- 토큰 하나를 복사하는 건 단순한 작업이라 늦게 처리해도 됨
- 두 헤드의 위치 분포가 거의 겹치지 않음
- ⇒ 아 각각 다른 역할이구나(둘 다 필요하구나!)
- Concept Copier Heads (🔶)
- Head들의 위치 분포
- 각 모델의 모든 attention head에 대해 causal score를 계산
Next-Token & Last-Token Attention Scores
목표Concept copier head는 도대체 어디에 attend하는가?- 기존 token induction head는 항상 바로 다음 토큰을 attend 함
RQconcept copier head는 개념 전체를 한번에 전달한다면 개념 정보가 저장된 마지막 토큰에 attend하지 않을까?
- 두 가지 Score 설계
- Last-Token Matching Score (concept head용)
# 프롬프트 구조 x1...xn c1...cm | x1'...xn' ↑ 여기서 attention 측정- 단어의 마지막 토큰을 바라보는 정도
x'n위치에서 개념의 마지막 토큰 cm에 얼마나 attend하는지 측정
- 개념은 COUNTERFACT 데이터셋에서 샘플링 (길이 2~5토큰)
- Next-Token Matching Score (token head용)
- 다음 토큰을 바라보는 정도
- 개념 대신 랜덤 토큰 span 사용
- 첫 번째 토큰 에 얼마나 attend하는지 측정
- Last-Token Matching Score (concept head용)
- 실험 결과
목표Llama-2-7b의 각 head의 next-token matching score와 last-token matching score
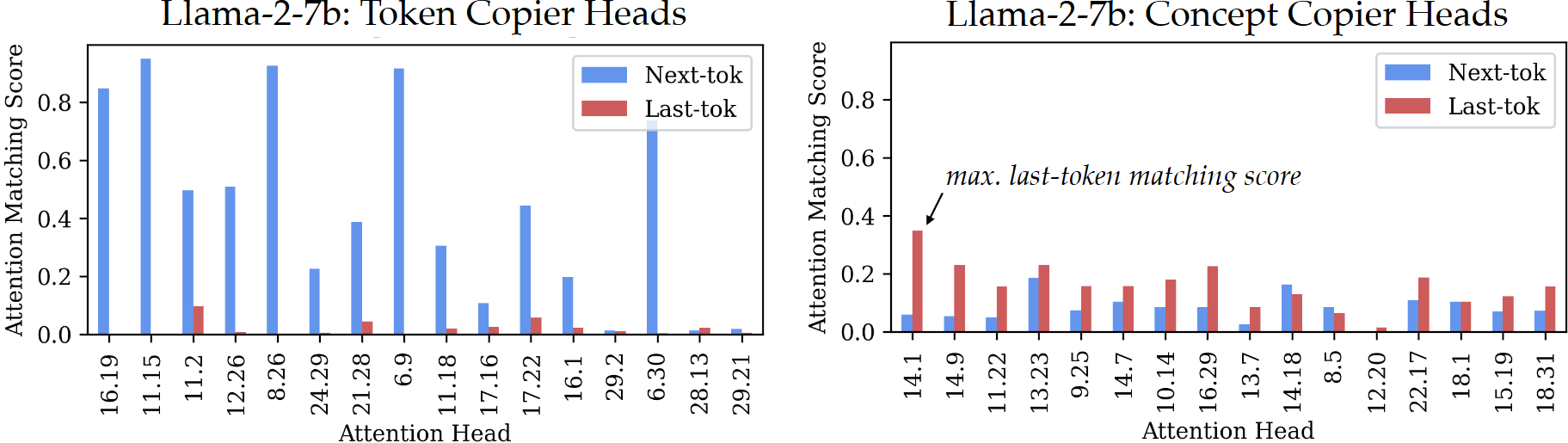
- x축: 각 attention head의 위치(layer 번호.head 번호)
- 왼쪽 그래프(token copy head): NEXTTOKENMATCHING이 매우 높음
- 오른쪽 그래프(concept copy head): LASTTOKENMATCHING이 매우 높음
Concept/Token Copier Head 제거 실험
RQConcept induction head와 Token induction head를 강제로 끄면 어떤 task에 영향을 주는가?- Concept head → fuzzy copying (의미 기반 복사) 에 중요
- 번역, 동의어, 반의어 등 의미적으로 관련된 단어 복사
- Token head → verbatim copying (그대로 복사) 에 중요
- 완전히 동일한 단어를 그대로 옮기는 작업
- Concept head → fuzzy copying (의미 기반 복사) 에 중요
- 실험 설계
- Fuzzy copying Tasks (의미 기반 tasks)
- Translations (5개 언어의 단어 → 영어 번역)
- uppercasing (대문자 변환)
- synonyms
- antonyms
- Baseline
- Verbatim task (의미(semantic)가 없는 토큰 복사)
- English copying: 영어 단어 목록을 그대로 반복
- Nonsense copying: 랜덤 토큰을 그대로 반복
- e.g., apple → apple, xyz → ?
- Verbatim task (의미(semantic)가 없는 토큰 복사)
- Metric
- First-token accuracy: 첫 토큰 맞추면 개념 이해했다고 판단
- Ablation 방식
- 특정 Head의 activation을 mean activation (무의미한 상태)으로 바꿈
- 어떤 Head를 지우냐?
- concept head 제거: concept score가 높은 head들
- token head 제거: token score가 높은 head들
- Fuzzy copying Tasks (의미 기반 tasks)
- 실험 결과
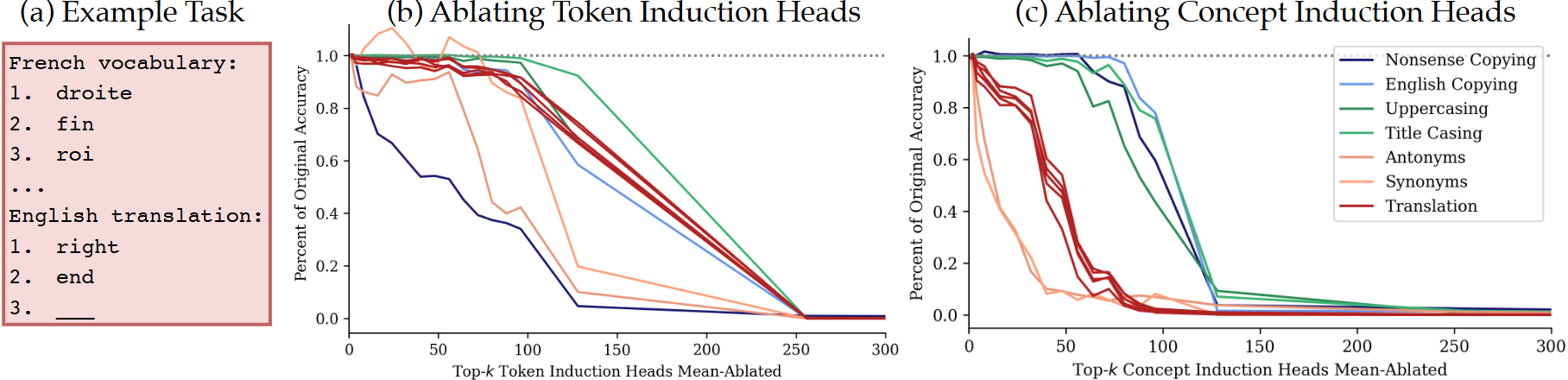
x축: 제거한 induction head 갯수(점수가 높은 top-k 순으로 ablate) - (b) ablating Token Induction Head
- Nonsense copying 실패
- 나머지 task는 concept head가 대신 수행 가능
- → Token head는 의미 없는 패턴의 그대로 복사에 필요
- (c) ablating Concept Induction Head
- 번역, 동의어, 반의어 정확도 하락
- 표면적 복사 task에는 영향 없음
- → Concept head는 의미 기반 복사에만 필요
- 두 ablation 모두 영향 없는 task
- English copying: 의미로도, 패턴으로도 풀 수 있어서 어느 쪽을 꺼도 나머지 경로가 대체
- Uppercasing: 마찬가지로 두 경로 모두로 해결 가능
→ Concept head를 끄면 의미 기반 복사가 망가지고, Token head를 끄면 verbatim 복사가 망가짐
⇒ 두 경로가 실제로 독립적으로 존재함
- (b) ablating Token Induction Head
Concept Induction is Language-Agnostic
- Concept induction head의 의미적 복사는 언어와 무관한 추상적 의미 표현의 복사다!
- e.g.,
- 영어
waxwing
- 러시아어
свиристель(여새)

waxwing: 여새 → 새(bird) 이름임 - 영어
- 두 단어는 표면적으로 완전히 다르지만, 같은 개념을 가리킴
⇒ concept head가 의미를 다루면 두 경우 모두 동일한 activation을 가질 것!
- e.g.,
- 실험 설계
- 두 개의 서로 다른 번역 프롬프트를 만듦
Source prompt (s) Base prompt (b) 번역 방향 스페인어 → 이탈리아어 일본어 → 중국어 번역 단어
- patching 실험 진행
- Source prompt에서 top-k concept head의 activation 추출
- Base prompt의 같은 위치에 이식(patch)
- 모델이 대신 의 의미를 출력하는가?
- 원래 이탈리어로 번역할 스페인어 를 중국어의 의미로 번역할건지?
- 두 개의 서로 다른 번역 프롬프트를 만듦
- 실험 결과
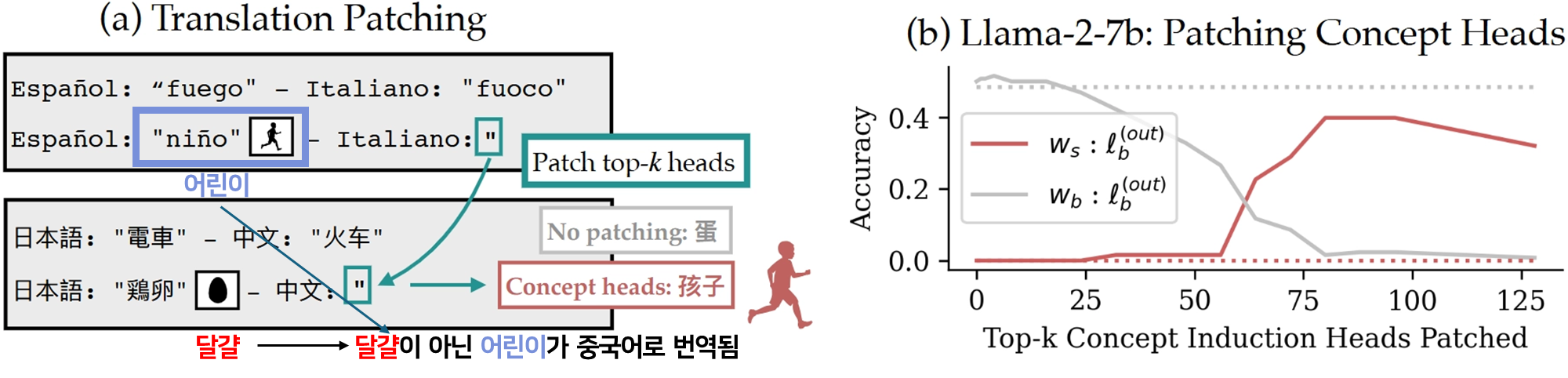
- (a) patching을 하니 source prompt의 가 번역됨(figure (a) 참고)
- (b)
- 빨간선( 출력): patch한 source 단어의 의미가 출력되는 정확도
- 회색선( 출력): 원래 base 단어의 의미가 출력되는 정확도
- k가 증가할수록:
- 회색선 하락 → 원래 답이 밀려남
- 빨간선 상승 → source 의미가 대신 나타남
- k=80 근처에서 효과가 가장 강력
- ⇒ 80개 정도의 concept heads가 가장 효과적이구나