14 January 2026
Advancing Expert Specialization for Better MoE
NIPS'25
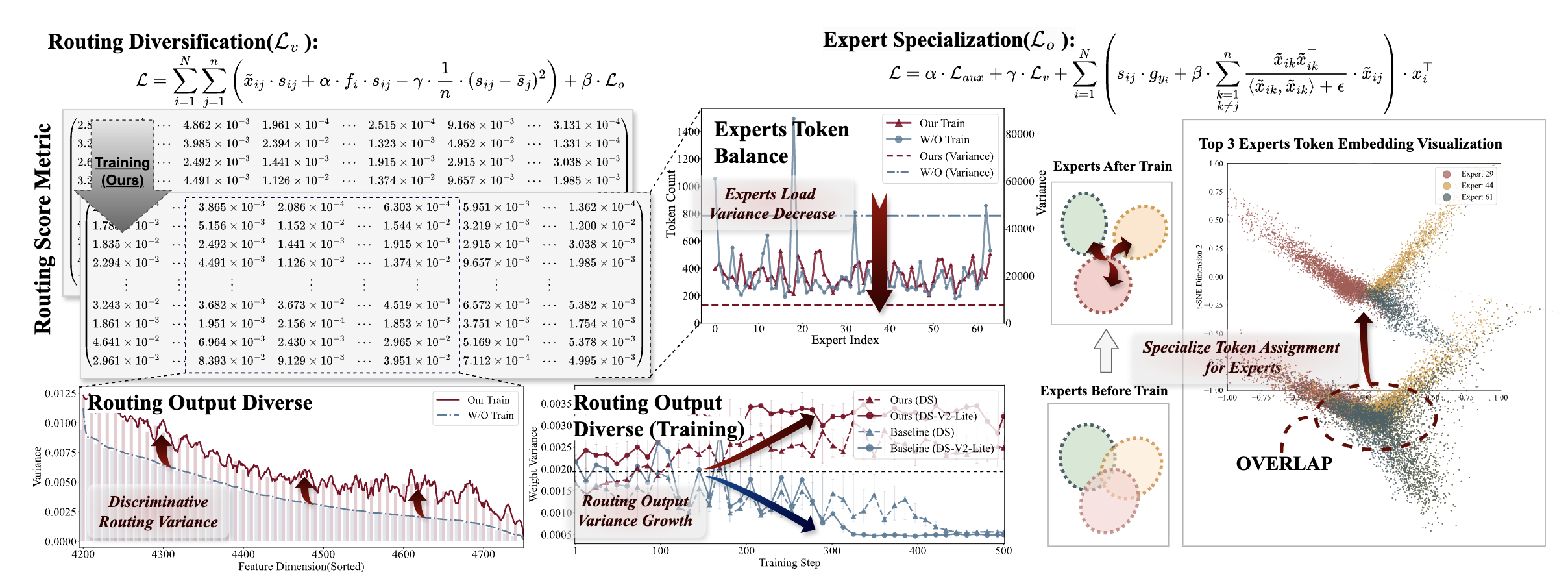
💡Mixture-of-Experts 훈련 손실함수에는 expert 간 routing 효율성 위한 objective term 있음그러나 이는 각 expert의 전문성 특화를 방해하는 부작용 있음⇒ routing 효율성 목표를 방해하지 않으면서 expert 전문화에 도움되는 objective를 추가하자
07 January 2026
What Happens During the Loss Plateau? Understanding Abrupt Learning in Transformers
NIPS'25
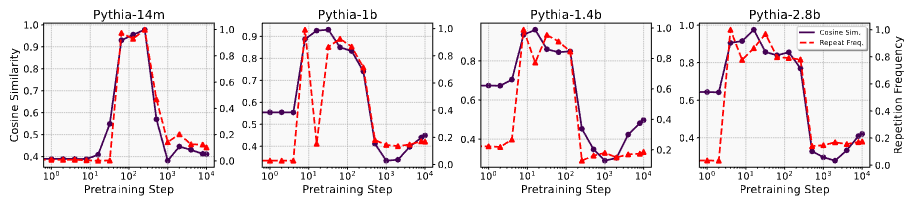
💡Transformer 모델 훈련 시 손실하락이 초기단계에서 정체되다가 갑자기 크게 일어나는 abrupt learning 현상 탐구
07 January 2026
Superposition Yields Robust Neural Scaling
NIPS'25
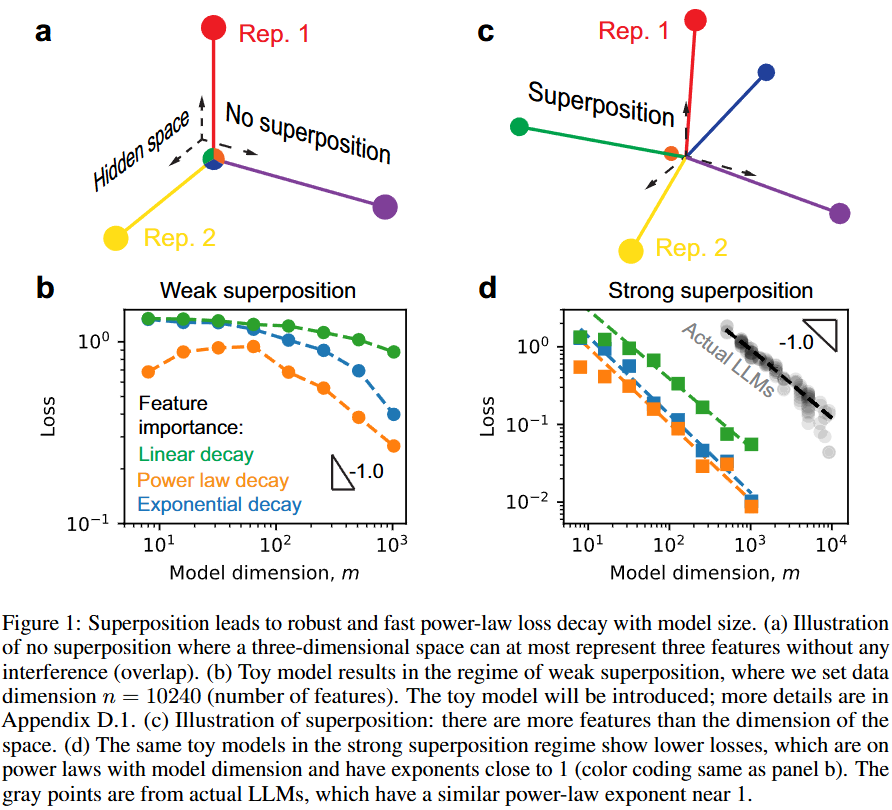
💡Superposition은 Scaling law가 작동하게 한다!