30 December 2025
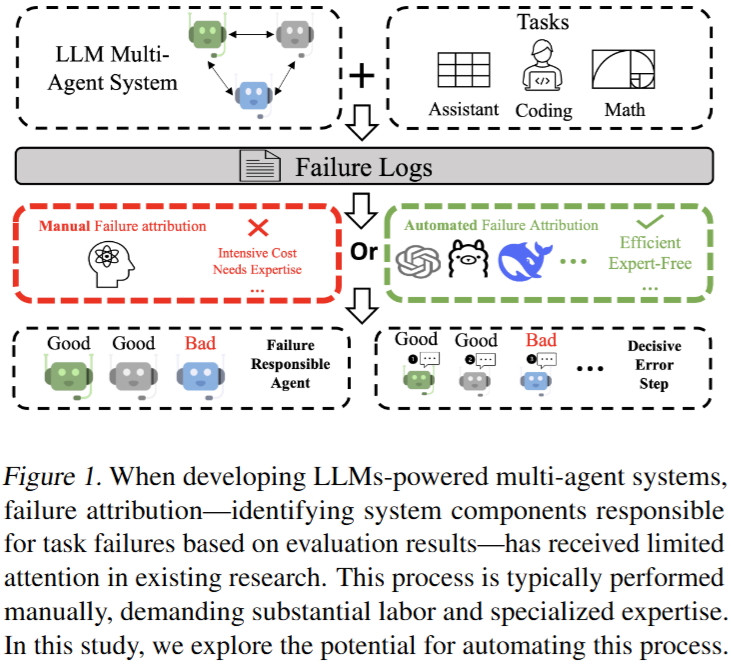
Which Agent Causes Task Failures and When? On Automated Failure Attribution of LLM Multi-Agent Systems
ICML'25
💡LLM 멀티 에이전트 시스템에서 오류가 났을 때 누가 언제 오류냈는지 자동으로 파악해보자!벤치마크 제안 및 현 LLM 성능 평가
30 December 2025
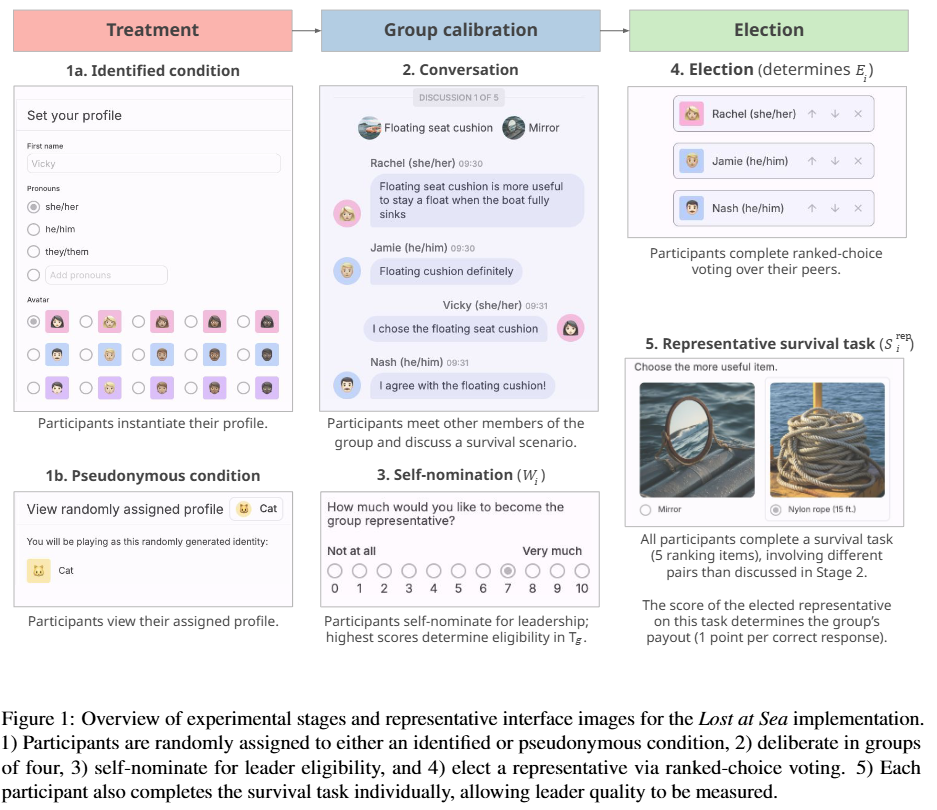
To Mask or to Mirror: Human-AI Alignment in Collective Reasoning
EMNLP'25
💡LLM은 사람을 따라하는가? 혹은 사람이 보편적으로 가진 편향(?)을 없애고 사람보다 더 나은 결정을 내리는가? 리더 선출 실험을 통해 분석한 결과, LLM 별로 다르다. (GPT, Gemini는 인간을 그대로 모델링 , Claude는 더 나은 선택)
17 December 2025
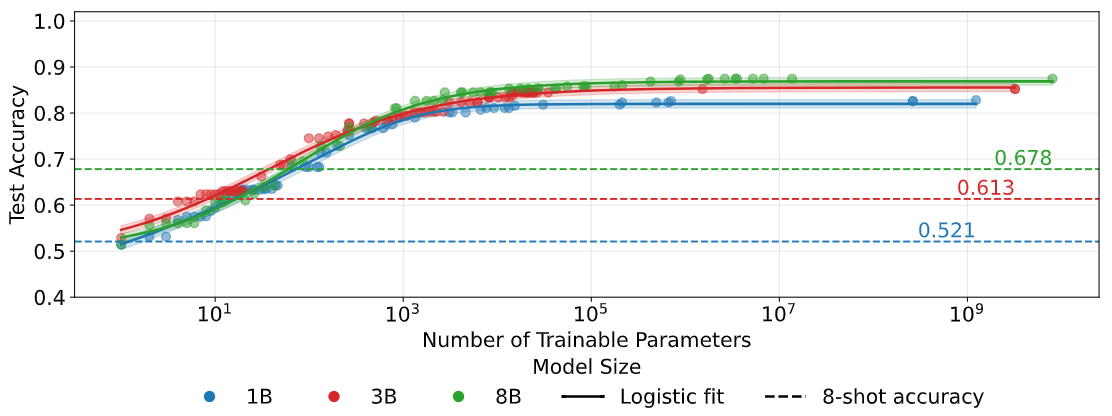
Quantifying Elicitation of Latent Capabilities in Language Models
NIPS'25
💡LLM은 잠재된 능력을 이미 갖추고 있으며, 아주 적은 수의 무작위 파라미터만 학습해도 그 능력을 효율적으로 끌어낼 수 있다는 것을 실험/이론적으로 정량화함