26 November 2025
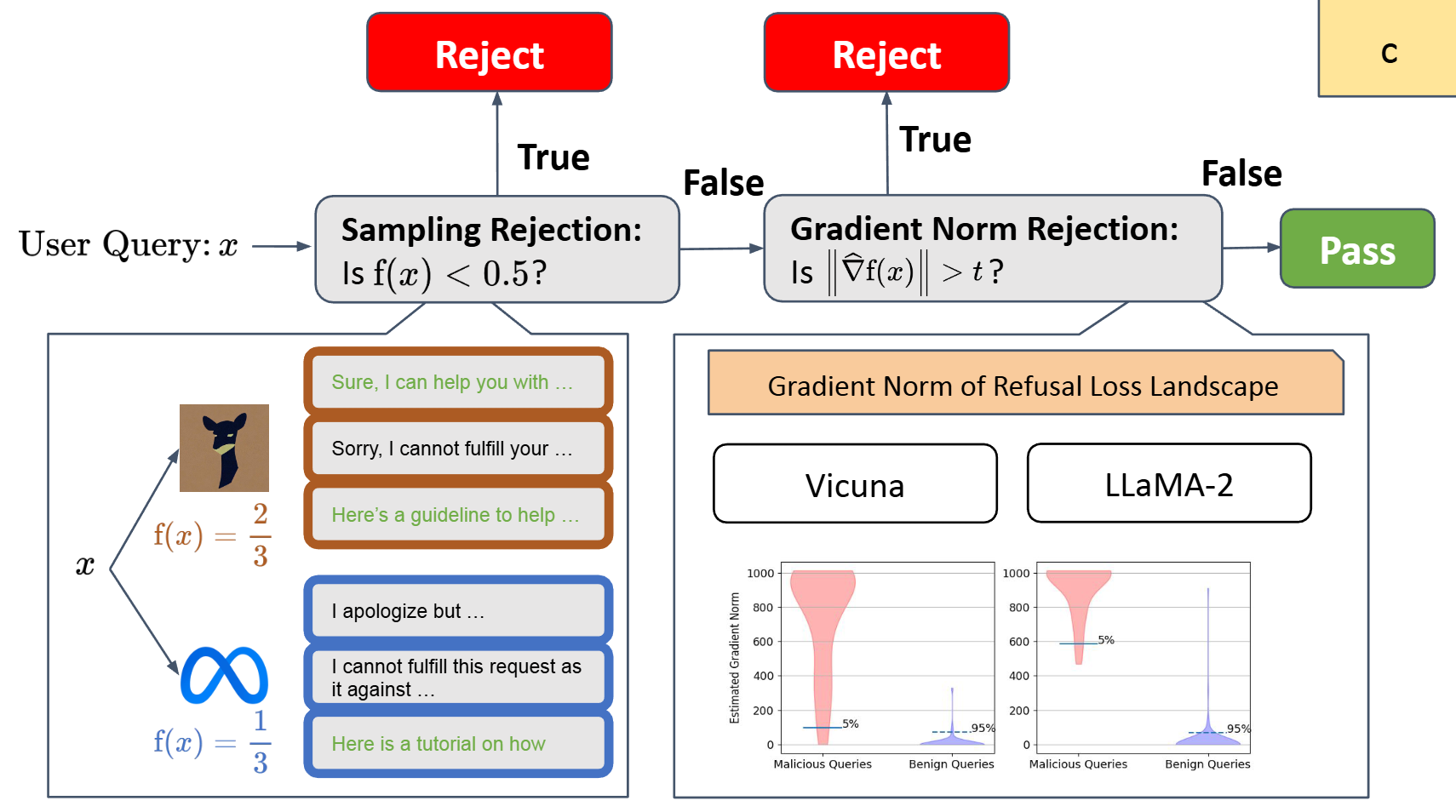
Gradient Cuff: Detecting Jailbreak Attacks on Large Language Models by Exploring Refusal Loss Landscapes
NIPS'24
💡Jailbreak: 사용자가 모델의 안전장치를 우회하여, 원래 거부해야 할 위험한 답변을 끌어내려는 공격적 프롬프트 조작 기법LLM이 jailbreak을 시도하는 prompt에 노출될 때, 모델의 loss function을 시각화한 landscape의 gradient가 흔들린다는 특징을 이용하여 jailbreak 공격을 차단하는 방법을 제안
26 November 2025
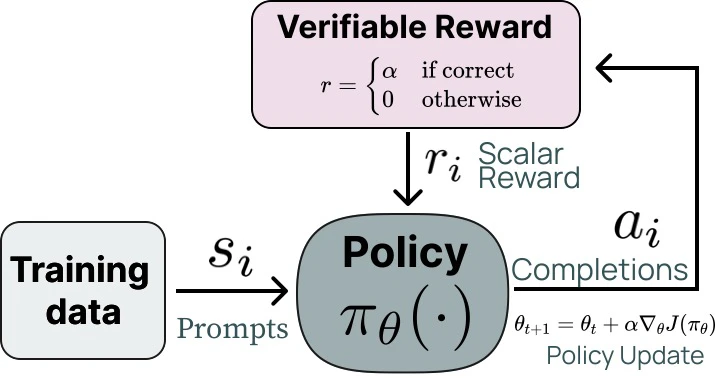
Does Reinforcement Learning Really Incentivize Reasoning Capacity in LLMs Beyond the Base Model?
NIPS'25
💡RLVR하면 sampling path에서 정답 path를 효율적으로 잘 찾긴 하는데, 원래 모델이 고려안하는걸 고려하는건 아님! 게다가 샘플링을 늘리면 오히려 reasoning scope가 base model보다 좁음!my insight: 이것도 지식의 저주?!
26 November 2025
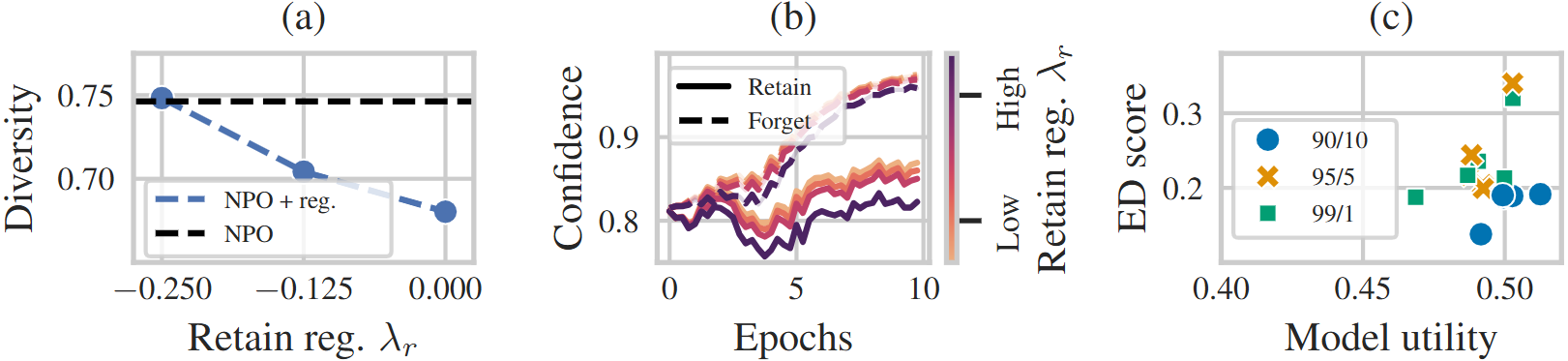
A Probabilistic Perspective on Unlearning and Alignment for Large Language Models
ICLR'25
💡LLM이 언러닝, 정렬이 진짜 잘 됐는지 평가하기 위해선 기존의 결정론적 출력 즉, 하나의 답만 평가해선 안되고, 모델의 전체 출력 분포를 확률적으로 보고 평가를 해야 함이를 위해 새로운 기존의 결정론적인 평가지표가 아닌 새로운 확률론적인 평가 지표들을 제안