
27 March 2026
How Do Transformers Learn to Associate Tokens: Gradient Leading Terms Bring Mechanistic Interpretability
ICLR'26 Oral
💡트랜스포머는 학습 초기에 3가지 방식의 통계 구조를 가중치에 직접 반영하며, 이들의 조합만으로 의미적 관계와 어텐션이 형성됨
27 March 2026
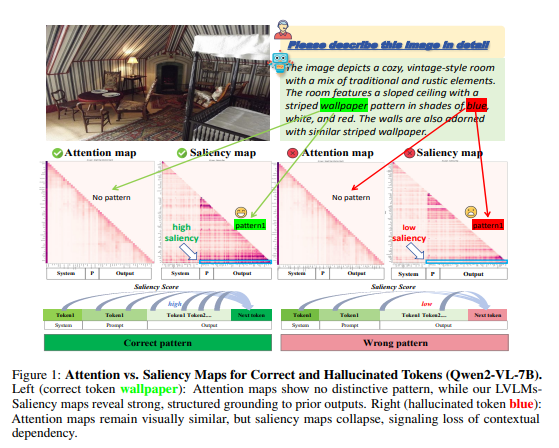
Hallucination Begins Where Saliency Drops
ICLR'26 Oral
💡Hallucination을 줄이기 위해 Attention map말고도 Saliency map에서 gradient가 줄어드는 부분을 확인해야 한다!
27 March 2026
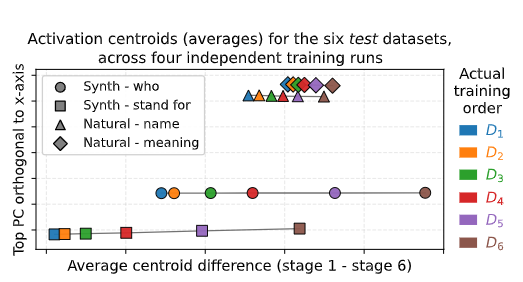
FRESH IN MEMORY: TRAINING-ORDER RECENCY IS LIN-EARLY ENCODED IN LANGUAGE MODEL ACTIVATIONS
ICLR'26 Poster
💡언어 모델은 “무엇” 을 배웠는지와 “언제” 배웠는지에 대해 알고있다.⇒ 다양한 통제 실험을 통해 검증해보자 ! !