Diffusion Alignment as Variational Expectation-Maximization
Review
| 닉네임 | Strength & Weakness & Sugguestions | 별점 (0/5) |
|---|---|---|
| 코스피 | 강점: 모델 가중치를 바꾸지 않고, Diffusion Optimization을 해결할 수 있어 효율성이 높음 약점: 디퓨전 모델인데, EM단계를 계속 반복하면 계산이 무거워지지 않을까? 제안: Timestep이나 반복 횟수를 조절해서 성능을 개선하는게 필요해 보임. | 3.9 |
| 얼라 | 강점: reward와 diversity를 함께 고려하면서 부분의 실험에서 SOTA 성능을 달성한 점이 강점 약점: test-time search의 품질에 크게 의존할 것 같음 + 계산량이 많이 필요해보임 제안: search를 최소화하면서 성능을 최대화하는 후속 연구가 나오면 좋을 것 같음 | 3.8 |
| 비요뜨 | 강점: 보상만 최적화 할 때 collapse 발생할 수 있는 문제를 EM으로 잘 균형을 잡은것 같음. EM을 diffusion에 사용한 사례를 처음 읽어보아서 잘 몰랐지만, EM학습 흐름이 diffusion의 샘플링/학습 구조와 잘 맞는 느낌? 약점: E-Step에서의 탐색 비용이 매우 클것 같음 제안: 모든 timestamp에서 M개씩 뽑는게 아니라 보상에 민감한 구간 별로 sampling 수를 다르게 할 수 있지 않을까? | 4.1 |
| 칫솔 | 강점: diffusion alignment에 EM 알고리즘을 새로운 방식으로 적용하고 reverse/forward KL도 결합함 약점: test-time search로 인한 시간 효율성 제안: test-time search 품질이 어느정도 이상이도록 보장하는 제약 추가 | 3.6 |
| 설향딸기 | 강점: diffusion이 가지는 다양성을 유지하면서도, 성능을 개선하는 방법 제안. 최근 강화학습들이 다양한 objective를 동시에 고려할 수 있도록 개량되고 있는 것 같고, 그 기조에 맞는 방법론이라고 생각함. 약점: 새롭게 느껴지지 않음. 그냥 기존 방법 2개의 결합 아닌가? 제안: 리워드 모델을 정확하게 조정하는 것이 오히려 over-optimization을 해결하는 더 좋은 방법일 것 같음. 이 알고리즘의 대상이 모델이 아니라, reward모델이나 다른 모델을 조정하여 해결하는 건 어떨까? | 3.7 |
| 나스닥 | 강점: 수학적 Soundness가 풍부함! Diffusion+RL은 참신한 조합인듯 단점: 타 메소드들과 비교해서 얼마나 가벼운지, 빠른지에 대한 비교가 있었다면 더 좋았을 것 같음! 제안: Alignment 성능, motivation에 대한 개선을 증명하려면 user study가 필요해보임! 여담: diffusion은 NLP랑 좀 안 맞는거 같다는 생각이 매번 듬 | 3.5 |
| 커피 | 강점 : 기존 diffusion의 문제인 mode collapse와 계산 비용 문제의 원인인 reverse-KL에 대해서, test-time-search 방식을 그대로 활용하여 세팅을 바꾸는 것이 참신함. 또한, test time search 방식의 샘플을 통해 reward gradient를 사용하지 않게 되어 더 일반화된 것이 의미가 있다고 생각. 약점 : test time search를 여전히 사용하므로 탐색비용에 큰 개선은 없을 것 같음. 또한 뽑힌 샘플의 퀄리티가 일관적이라면, reverse-KL의 mode collapse의 문제도 큰 개선이 없지 않을까? 제안 : test time search와 샘플의 퀄리티 확보에 관련된 연구가 추가 제시되었으면 더 논리적이었을 것 같음. | 3.8 |
| AI | 강점: reward 최적화를 수행하면서 diversity까지 유지하는 diffusion alignment의 핵심 trade-off를 잘 해결한듯 + DNA 도메인 실험도 신박함 약점: 근본적으로 diversity는 유지하더라도 모델의 bias 자체는 해결하기 힘들어보임 제안: 여기서 reward를 항상 절대적으로 신뢰하는데, uncertainty를 고려해볼 수 있지 않을까? | 3.9 |
| 404 | 강점: diffusion을 기존 Preference optimization에 접목하려는 시도 자체가 novelty가 크고, soundness가 좋다고 생각함! 현재 vision에서 difussion이 사용되는 취지가, 저자들이 제안하는 motivation과 직관적으로 align이 잘 되어서, 흥미롭게 읽음 약점: 다양성 이외의 모든 부분. e.g. 시간적인 cost, bias 등등을 고려하지 못함 (+architecture 그림 없어서 가독성이 너무 낮음) 제안: NLP downstream task에 적용 | 4.2 |
| 국밥 | 강점: mode-seeking 문제를 forward-KL로 전환하는 발상이 단순하지만 효과적인것 같음. 연속, 이산 두 도메인에서 동시에 검증해서 실험함. 약점: E-step에서 test time search 비용이 매 iteration마다 발생함. 기존 방법에 비해 실제 학습 시간이 얼마나 더 걸리는지 비교가 없음. 제안: E-step에서 탐색 횟수와 성능 간 비교 | 3.8 |
TL; DR
Diffusion 모델을 목적 함수에 맞게 diffusion alignment할 때 발생하는 reward over-optimization 과 mode collapse 문제를 EM알고리즘 (E단계(test time search) → M단계(forward-KL)의 반복)으로 해결하자!
Summary
- 연구진: KAIST, MongooseAI, Mila, University of Edinburgh, Omelet
Background & Motivation
Diffusion 모델은 이미지, 로보틱스, 생물학 등 다양한 도메인에서 high-fidelity 샘플을 생성하는 데 뛰어남.
→ but 실제 응용에서는 단순히 샘플을 생성하는 것 외에도, 외부 기준(이미지의 미적 품질, DNA enhancers활성도 등)에 맞춘 샘플이 필요함
→ 이를 위해 diffusion alignment(사전학습된 diffusion 모델을 downstream objective에 맞게 fine tuning)이 필요
Diffusion Alignment의 기존 접근법
- RL 기반 fine-tuning (DDPO, DPOK)
- on-policy 데이터를 사용하여 reverse-KL objective를 통해 디퓨전 모델을 파인튜닝
- Denoising 과정을 sequential decision making으로 보고, black box reward function을 최대화하도록 policy 최적화
- Reverse-KL objective 사용 → mode-seeking 행동 → mode collapse 발생
- Direct backpropagation(DRaFT, AlignProp)
- 미분 가능한 reward functio으로부터 gradient를 denoising chain을 통해 직접 역전파
- 샘플 효율성은 높지만, reward model의 gradient 값에 의존 → reward 모델 자체가 완전하지 않음 → reward over-optimization 발생
→ 기존의 두 방법에서 mode collapse(생성된 샘플이 하나의 mode로만 생성이 되어서 다양성이 떨어짐), reward over optimization(reward 점수는 높지만 실제 품질은 오히려 떨어짐) 문제가 발생
Fine-tuning approaches
- Liu et al. (2024); Domingo-Enrich et al. (2025) 에서 reward function의 기울기 신호를 사용하여 사전 훈련된 분포를 따르도록 연속 diffusion 모델을 fine tuning할 것을 제안
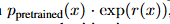
Test-time search 방식
- 모델 가중치를 바꾸지 않고 추론 시에 추가 연산을 투입
- 2가지 방식
- Guidance 기반: 노이즈 제거의 각 단계마다 reward가 높아지는 방향으로 신호를 줌. 하지만 근사치이기 때문에 underoptimization 일어남.
- search 기반: 각 단계에서 여러 후보들을 생성하고 그중 가장 좋은 것을 선택. 계산비용이 큼
- 기존의 test time search 방식은 계산 비용이 크고, underoptimization 현상 일어남
+연속과 이산 diffusion 모두에 적용 가능한 프레임워크는 없음
- 기존 방법들은 미분 가능한 reward와 연속 diffusion에 한정됨
→ Reward를 최대화하면서도 다양성과 자연스러움을 높이고, 연속/이산 도메인 모두에 적용 가능한 디퓨전 모델 fine tuning 프레임워크가 필요함
→ DAV는 test time search 방식을 통해 샘플 수집 → 수집한 샘플을 디퓨전 모델에 distill 함으로써 위 두 패러다임을 통합.
Contributions
DAV (Diffusion Alignment as Variational EM) 프레임워크
- Diffusion alignment를 variational EM 알고리즘으로 구현
- E-step (탐색)과 M-step (근사화)를 반복하여 reward 최적화와 다양성 보존을 동시에 만족함
E-step에서 test time search를 활용한 posterior inference
- Soft Q-function 기반의 test time search로 보상이 높은 다양한 샘플을 variational posterior에서 탐색하여 사용
- 기존 EM기반 RL 접근법의 약점(on poliocy 샘플을 reweighting하여 사후분포를 근사할때 사후 분포를 잘못 지정하게 됨)를 극복
M-step에서 forward-KL distillation으로 모델 업데이트
- Reverse-KL(mode-seeking) 대신 forward-KL(mode-covering)을 사용하여 다양성 보존
- E-step에서 발견한 다양한 mode를 모두 커버하도록 모델이 학습됨
연속 + 이산 diffusion에 모두 적용 가능
- Text-to-image와 DNA sequence design 에서 실험 검증
- Reward function의 미분 가능성에 대한 가정 불필요(미분을 사용하지 않음) → 더 일반적인 프레임워크(연속, 이산 모두 적용 가능)
→ forward-KL 방식으로 기존의 Diffusion Alignment 접근법들의 두가지 문제점을 해결하면서 Test-time search 방식을 추가 계산 오버헤드 없이 학습 시에만 사용함으로써 효과적으로 적용한 데에 의미가 있음
Method
전체 파이프라인: E-step과 M-step을 반복하며, E-step에서 발견한 높은 보상 샘플을 M-step에서 모델에 distillation.
E-step: 탐색. test time search로 보상이 높고 다양한 샘플을 발견
→
M-step: 증류. 발견한 샘플들을 forward-KL로 모델에 distillation
→
반복
variational EM formulation
- optimality variable O를 도입
- O=1이면 좋은 결과, 이 확률을 최대화하는 것이 목표
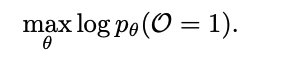
- 디노이징 경로 τ가 숨겨진 변수(latent variable) 역할
- τ가 높은 보상을 줄수록 O=1일 확률이 높음
- O=1이면 좋은 결과, 이 확률을 최대화하는 것이 목표
- 직접 최적화가 어려우므로 Variational distribution η(τ)를 도입해 ELBO를 최대화
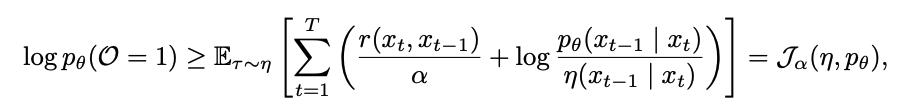
- Discount factor γ를 추가하여 노이즈가 큰 초기 단계의 영향을 줄임
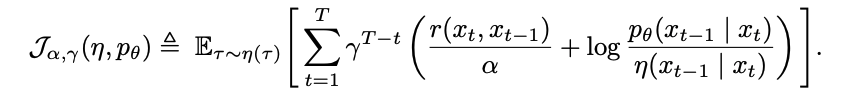
E-step: test time search로 posterior inference
- 최적의 variational distribution η*는 "현재 모델의 확률 × 소프트 Q-함수의 지수"에 비례하는 볼츠만 분포
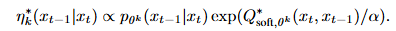
- η*k 에서 다양하고 보상이 높은 궤적을 샘플링 하는 것이 목표
- 직접 샘플링이 불가능하므로 2단계 근사 수행:
- gradient guidance로 proposal distribution(제안 분포) 구성 (보상 기울기로 좋은 방향을 안내)
- importance sampling으로 보정 (실제 최적 분포와의 차이를 가중치로 보정)
- 모듈화 설계를 통해서 더 좋은 탐색 알고리즘이 나오면 교체 가능
M-step: forward-KL로 디퓨전 모델 업데이트
- E-step에서 발견한 궤적들에 대해 log-likelihood를 최대화함으로써 학습 = forward-KL minimization
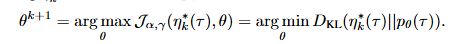
- Forward-KL 사용 → mode-covering 특성 → 다양한 모드를 모두 커버하도록 학습
- 기존 RL은 reverse-KL → mode-seeking → 하나의 모드에만 집중
- DAV-KL variant: 사전학습 모델과의 KL 페널티를 추가하여 다양성을 더 보존
DAV, DAV-KL?
- DAV: reward를 더 공격적으로 올림 → 점수는 높지만 다양성은 상대적으로 낮음
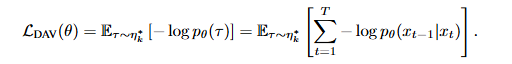
- DAV-KL: reward는 좀 낮지만 사전학습 모델의 특성을 더 보존하도록 제약 λ 추가
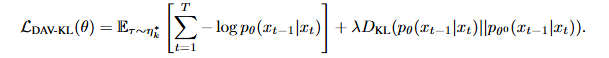
- DAV: reward를 더 공격적으로 올림 → 점수는 높지만 다양성은 상대적으로 낮음
Forward-KL은 mode-covering objective 함 → E-step에서 발견한 모든 다양한 mode를 커버하도록 모델 업데이트
Experiments
실험 1: Text-to-image 생성 (연속 diffusion)
실험 세팅
- 모델: Stable Diffusion v1.5 (LoRA rank 4로 파인튜닝)
- 보상: LAION aesthetic score (미적 품질 점수, 미분 가능)
- 프롬프트: 40개의 동물 프롬프트
- 평가 지표:
- reward(미적 품질)과 더불어 이전 방법의 두가지 주요 실패 였던 과최적화와 다양성 붕괴(mode collapes)를 평가
- Aesthetic Score(LAION aesthetic score): 미적 품질. (미분 가능함) → reward. 모델이 최적화하도록 훈련된 목표 점수
- ImageReward: 인간 선호도 점수 → 학습에 사용되지 않은 별도의 평가 지표 (과최적화 탐지를 위해 사용)
- CLIP Score: 프롬프트-이미지 일치도 (과최적화 탐지)
- LPIPS-A/P: 샘플 다양성
- reward(미적 품질)과 더불어 이전 방법의 두가지 주요 실패 였던 과최적화와 다양성 붕괴(mode collapes)를 평가
- Baselines: DDPO (RL기반 파인튜닝), DRaFT (직접 역전파), TDPO (gradient-free RL), DAS (테스트 시간 탐색)
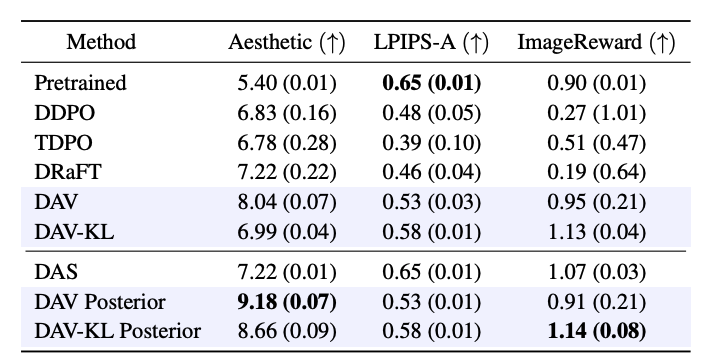
- 결과
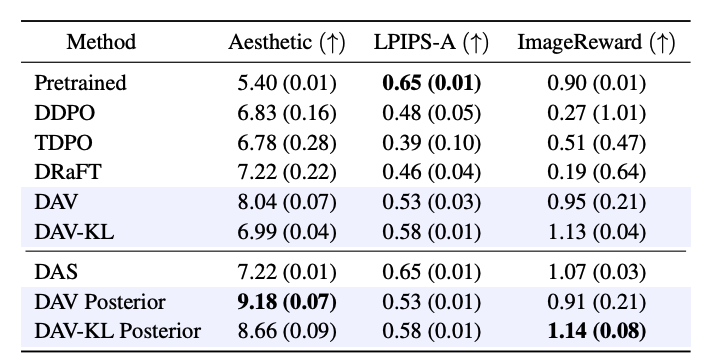
- DAV는 reward(8.04)가 DDPO(6.83), DRaFT(7.22)보다 크게 높으면서 ImageReward(0.95)를 기존 pretrained 수준으로 유지
- → reward 함수를 속이지 않고(over-optimization하지 않고) 진짜로 좋은 이미지를 만들었다
- 기존 방법들은 보상을 올릴수록 ImageReward, CLIP, 다양성이 떨어짐 (over-optimization됨)
- → 기존 방식(DDPO, DRaFT)은 Aesthetic Score 라는 평가 지표에만 너무 over-optimization 된 나머지 실제로 보기에는(ImageReward) 나빠졌다
- DAV-KL은 다양성과 ImageReward에서 가장 우수
- DAV Posterior(테스트 시간 탐색 추가)는 미적 점수 최고 점수 9.18 달성
DAV Posterior란?
DAS: 기존 test time search. 학습 안된 원본 모델인 p0에서 탐색.
DAV: 논문의 em 알고리즘을 통해서 디퓨전 모델 학습 후에 모델만 가지고 샘플링 결과
DAV Posterior: 학습 후에 학습된 모델을 사용하여 추론 때마다 탐색(test time search)을 추가로 수행. 성능이 높지만 시간이 좀 더 걸림
실험 2: DNA sequence design (이산 diffusion)
실험 세팅
- 모델: Masked Diffusion Language Model (MDLM)
- 데이터: 700K DNA 인핸서 서열 (200bp)
- 보상(reward): Enformer 모델의 인핸서 활성도 예측값
- 평가 지표:
- Pred-Activity: 예측 활성도 (reward)
- ATAC-Acc: 염색질 접근성 (생물학적 타당성, 과최적화 탐지)
- 3-mer Corr: k-mer 빈도 상관관계 (자연스러움)
- Levenshtein Diversity: 서열 간 편집 거리 (다양성)
- Baselines: DRAKES (직접 역전파), DDPO/VIDD (RL 기반)
- 결과
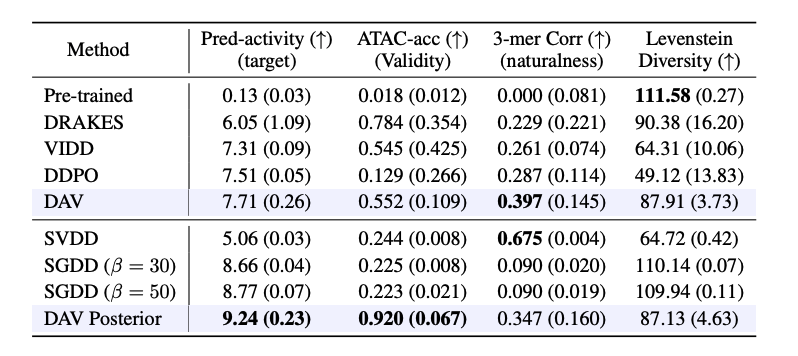
- DAV는 보상, 다양성, 자연스러움 모든 측면에서 균형 잡힌 성능
- DDPO/VIDD는 reward는 높지만 다양성과 validity(타당성)이 낮음 (over-optimization)
- DAV Posterior는 reward(9.24)과 validity(0.920) 모두 최고점