26 March 2026
TROLL: Trust Regions Improve Reinforcement Learning for Large Language Models
ICLR'26 Oral
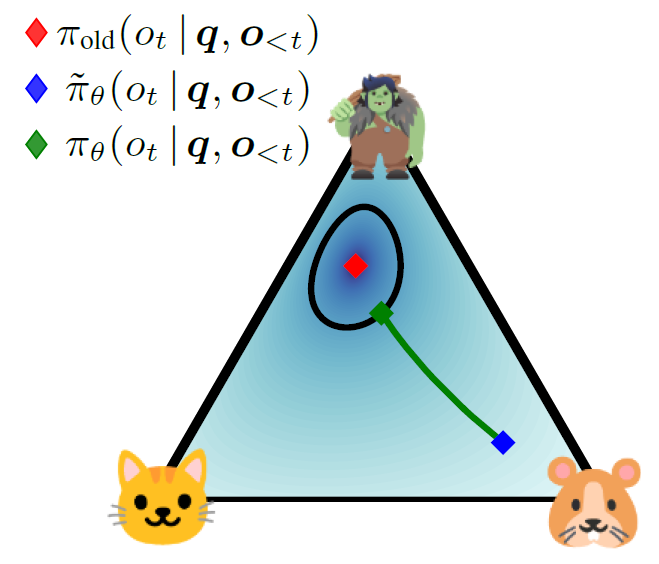
💡LLM을 RL로 학습할 때 모델이 한 번에 너무 크게 바뀌면 망가지므로, 허용된 범위 안에서만 업데이트해서 안전하게 학습시키자
26 March 2026
LoongRL: Reinforcement Learning for Advanced Reasoning over Long Contexts
ICLR'26 Oral
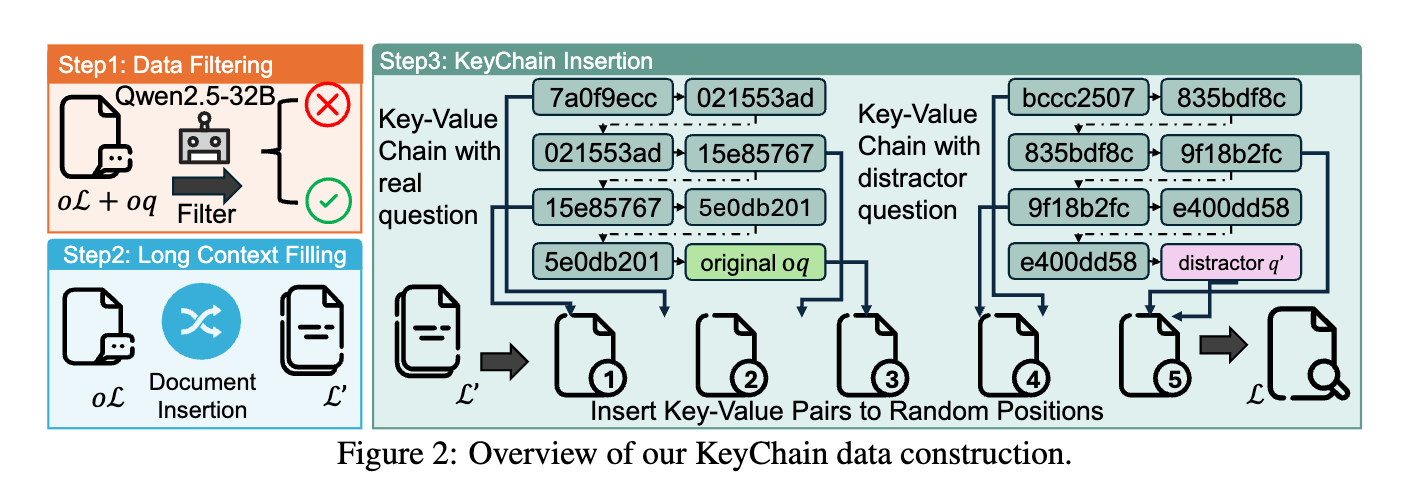
💡short-context(16K) RL 학습만으로 long-context(128K) 추론을 잘하게 하자.어떻게?⇒ UUID 체인으로 질문을 숨긴 고난이도 합성 데이터(KeyChain)로 RL 학습하면, plan–retrieve–reason–recheck 사고 패턴이 발생하여 높은 장문 추론 성능을 7B/14B의 소형 모델로 달성할 수 있다.
26 March 2026
Exploring the Limit of Outcome Reward for Learning Mathematical Reasoning
COLM'25
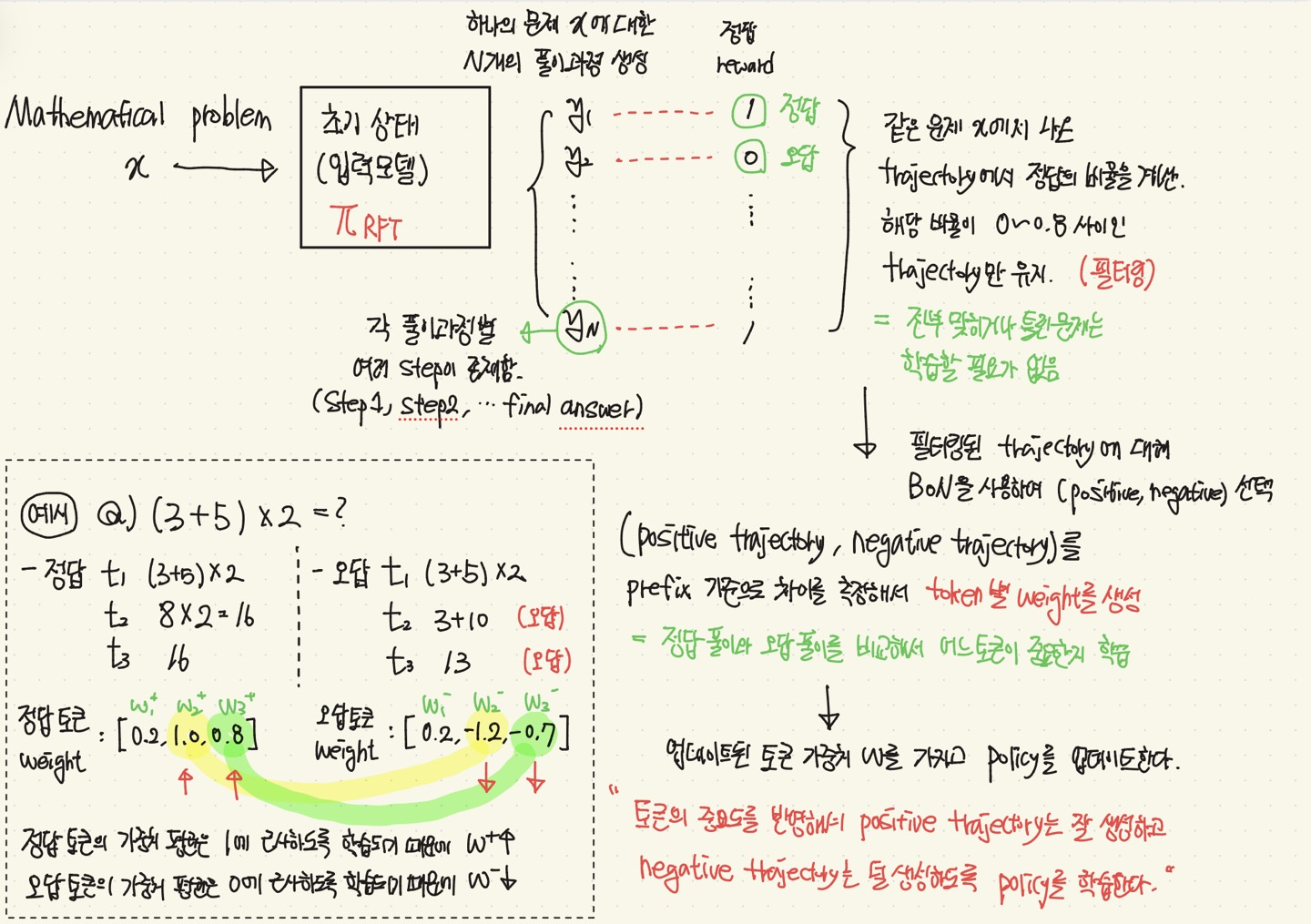
💡Mathematical Reasoning Task 를 할 때, RL을 간접적으로 구현하여 간단하게 풀어보자.(= 강화학습 형태로 수학문제를 효과적으로 풀어보자 !)
19 March 2026
Why DPO is a Misspecified Estimator and How to Fix It
ICLR'26 Oral
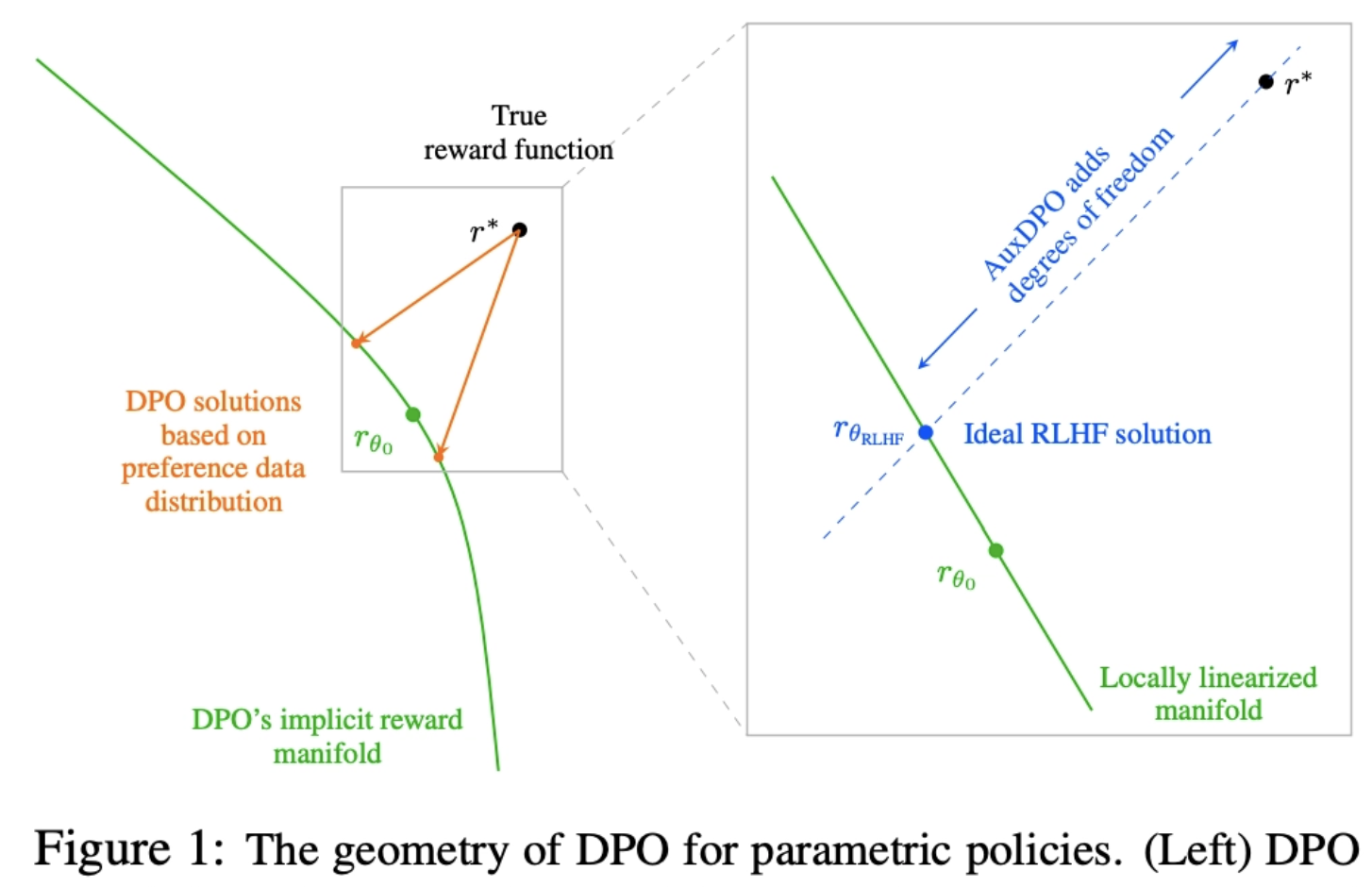
💡DPO의 전제가 realistic하지 않음을 위상학적으로 파헤침 AuxDPO를 통해 DPO의 Misspecifection를 완화하자!
19 March 2026
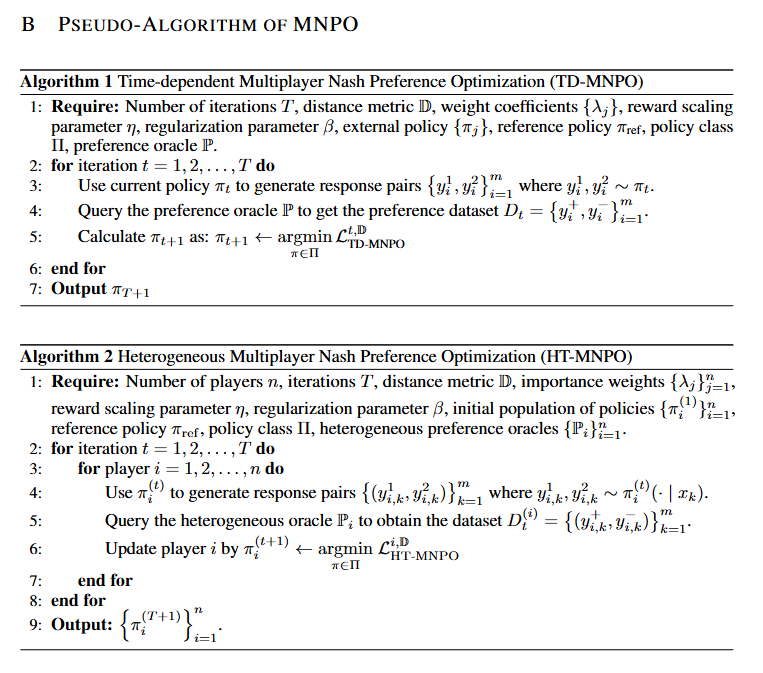
Multiplayer Nash Preference Optimization
ICLR'26 Poster
💡alignment가 가져야 할 목표는 보상을 최대화하는 것이 아니라, 다수 가치 및 정책 집단 속에서 그 누구에게도 지지 않는 안정적 균형 상태를 가지는 것이다!
19 March 2026
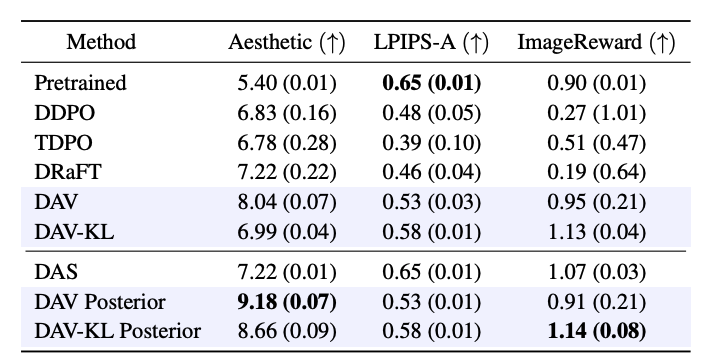
Diffusion Alignment as Variational Expectation-Maximization
ICLR'26 Poster
💡Diffusion 모델을 목적 함수에 맞게 diffusion alignment할 때 발생하는 reward over-optimization 과 mode collapse 문제를 EM알고리즘 (E단계(test time search) → M단계(forward-KL)의 반복)으로 해결하자!