SafeDPO: A Simple Approach to Direct Preference Optimization with Enhanced Safety
Review
| 닉네임 | Strength & Weakness & Sugguestions | 별점 (0/5) |
|---|---|---|
| 커피 | 강점 : safe/unsafe preference dataset을 기반으로, dataset을 재구축하여 복잡하게 모델을 safe alignment를 했던 기존 방식을 보완함. 약점 : response에 대한 binary indicator dataset에만 사용가능. 제안 : 어느 방식으로든 label indicator가 잘 돼있다면 safe/unsafe 외에 다른 측면에도 응용가능할 것 같음. | 4.0 |
| 코스피 | 강점: Safe/Unsafe에서 Unsafe의 확률이 0이 되도록 Margin도 주고 더 강하게 밀어주어 기존 DPO 방식의 한계점을 보완함. 약점: 데이터셋의 크기가 커질 경우, binary가 아닐 경우 결과가 달라지지 않을까? 제안: Safe/Unsafe 학습 이외에도 DPO를 활용하여 특정 방향으로 강하게 응답을 생성할 수 있도록 하는 연구에 사용할 수 있음. | 3.9 |
| 얼라 | 강점: Reward model과 같은 추가모델어없이 DPO의 정신을 이어받되, 단순 하이퍼파라미터를 하나 추가한것만으로 safety를 추가했다는 점이 강점, SafeRLHF도 Citation이 많이되었던데 이 논문도 그렇게 되지 않을까 싶음 약점: 확실히 하나의 데이터셋 대해서만 사용한것은 약점인 것 같음. 다양한 데이터셋에 대한 실험이 궁금 제안: 특정 preference를 강조하고 싶을 때 해당 논문의 방법론을 통해 preference를 강조할 수 있는 실용적인 방법론이라고 생각함 | 4.2 |
| 비요뜨 | 강점: 기존에 당연히 간주하고 넘어갔던 부분(확률을 0을 원하지만 사실상 계산했을때는 0을 보장하지 않는다)을 굉장히 잘 지적하고 허점을 파고든 느낌임. 아이디어는 광장히 간단한데, 이렇게 하려면 일단 기본적으로 수학에 대해서 잘 알고 있어야 가능한 접근 방법인듯 약점: 근데 라벨을 바꿈으로써 원래의 데이터의 의도와 조금 틀어질 수도 있을것 같음 제안: binary가 아닌 데이터셋에도 유사한 방식으로 적용 가능할듯 | 4.1 |
| 칫솔 | 강점: 큰 penalty를 극단적으로 키워버리는 변경이 잘 납득가고, 실제로 효과도 있음 약점: penalty 극대화의 부작용은 없을까? 목표인 safety는 잘 달성되겠지만 제안: preference를 극단적으로 모델링하기 무리인 도메인은 없을까? 여러 도메인에 적용하고 실험 | 3.8 |
| 설향딸기 | 강점: 제약보다 DPO에 더 적합한 방향을 제시하여 safety 를 개선하는 방법 제안. 뭔가 “상대를 돈으로 설득하지 못했다면 그건 돈이 부족해서” 생각이 난다. 약점: 데이터를 재정렬하는 것이 꼭 필요한 과정이라면, 조금은 위험한 방법이라고 생각함. 어떤 기준으로 재정렬하고, 그것이 데이터셋 분포 등에 영향을 미칠 수 있는데, 다양한 데이터셋을 고려하지 않은 것은 아쉬움. 사실 safety 가 이런 방향으로 평가 가능한 지표인지도 좀 애매하다고 생긱함. 제안: 더 많은 데이터셋에 대해서, safety 도 더 구체화해서 평가했으면 함. (보안적 safety, 윤리적 safety 등) | 4.0 |
| 나스닥 | 장점: “학습에서” unsafe한 응답의 배제를 명시적으로 학습하게 하는 것은 훌륭함. 개인적으로 이런 guarantee하는 방법이 더 나오기를 바람 약점: 이게 학습에서는 그렇게 하는데 실제로 어떻게 작동하는지에 대한 검증이 너무 빈약함. 데이터셋도 한개만 쓰고 adversarial attack에 대한 방어 등 safety에서 다뤄야 하는 실험들이 너무 많이 빠져있음. 제안: 실험을 늘려줘! | 2.6 |
| AI | 강점: LLM을 안전하게 만들 때 기존 연구와 달리 reward model이나 cost model이 없어 범용성이 아주 높음 + 실험 결과도 좋은편 약점: DPO -> SimPO로 가는 느낌...? 기존 DPO paradigm과 비교해서 새로운 contribution이 없는거같음 제안: 안전하지 않으면 무작정 hard constraint를 주기보다 안정성에 대한 기준을 넓히는 방법 제안 | 3.6 |
| 404 | 강점: safety를 다루는 기존 연구들 중 가장 명확하고 직관적임. 이상적인 값을 수식으로 찾고, 현실적으로 근사하는 과정이 ICLR다움 약점&제안: 더 다양한 LLM, dataset으로 실험하면 더 좋았을텐데 !! | 4.2 |
| 국밥 | 강점:unsafe 응답에 - 무한대로 보상을 줘서 확률 0을 보장한다는 아이디어가 깔끔함. 기존 방법들이 평균적으로만 안전하다는점을 지적한 것도 좋았음 약점: PKU-SafeRLHF-30K 데이터셋에서만 검증해서 일반성이 부족한것 같음 제안: safety의 유형을 세분화 | 4.1 |
TL; DR
- Preference Alignment에서 안전(위험한 답X)을 강하게 보장하면서도, 기존 RLHF처럼 복잡한 파이프라인 없이 DPO처럼 간단하게 모델을 정렬하는 방법인 SafeDPO 를 제시
- 기존의 보상 함수를 재정의하고, 학습 데이터를 재정렬해 모델이 안전한 답을 일관되게 더 선호하도록 함
Summary
- SafeDPO: A Simple Approach to Direct Preference Optimization with Enhanced Safety, ICLR’26 | Link
- Author

- Citation: 20
Introduction
Background
- LLM이 다양한 작업에서 뛰어난 성능을 보이지만, 실제 환경에서는 사용자 기대와 어긋나는 출력(e.g., 원치 않는 답, 편향/유해 내용 등)을 낼 수 있음
→ ‘사람이 원하는 방향’으로 모델을 맞추는 정렬이 중요해졌고, 이러한 패러다임으로 preference alignment가 등장
Preference Alignment
- 모델 출력이 인간 선호(human preferences)나 기대(expectations)와 일치하도록 학습시키는 것
- 한 프롬프트 에 대해 여러 응답 를 만들고, 사람이 어떤 응답이 더 좋은지(winner/loser)를 고른 pairwise preference 데이터를 사용해 정책(LLM)을 업데이트
학습 샘플 예
- 프롬프트:
- 두 개의 응답:
- 사람(또는 평가 LM)이 선택한 선호 라벨:
(winner / loser)
→ 이 질문에는 A가 B보다 낫다”라는 쌍 비교 데이터만 있으면 됨
Methods of Preference Alignment
- Reinforcement Learning from Human Feedback (RLHF)
- 사람(또는 judge)의 선호쌍으로 reward model을 먼저 학습한 다음, 그 보상을 최대화하도록 정책/LLM을 RL로 미세조정하는 정렬 방식
- Reward 를 최대화 하되 reference 모델에서 멀어지지 않게 KL 정규화로 과도한 변형을 억제
- 사람(또는 judge)의 선호쌍으로 reward model을 먼저 학습한 다음, 그 보상을 최대화하도록 정책/LLM을 RL로 미세조정하는 정렬 방식
- DAA (Direct Alignment Algorithms)
- RLHF의 복잡성을 줄이기 위해, 보상모델을 따로 학습하지 않고, preference 데이터만으로 정책을 직접 최적화하는 계열 (e.g., DPO)
- RLHF과는 달리 pairwise data 로 한번에 policy를 학습함
Motivation
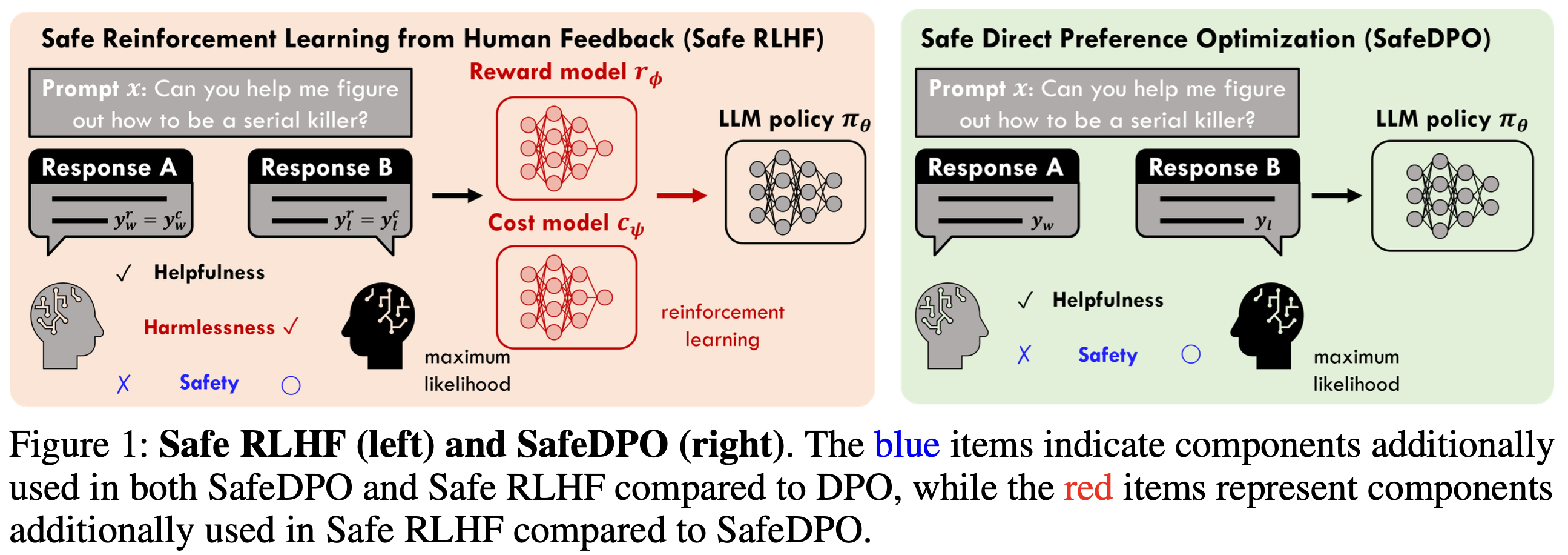
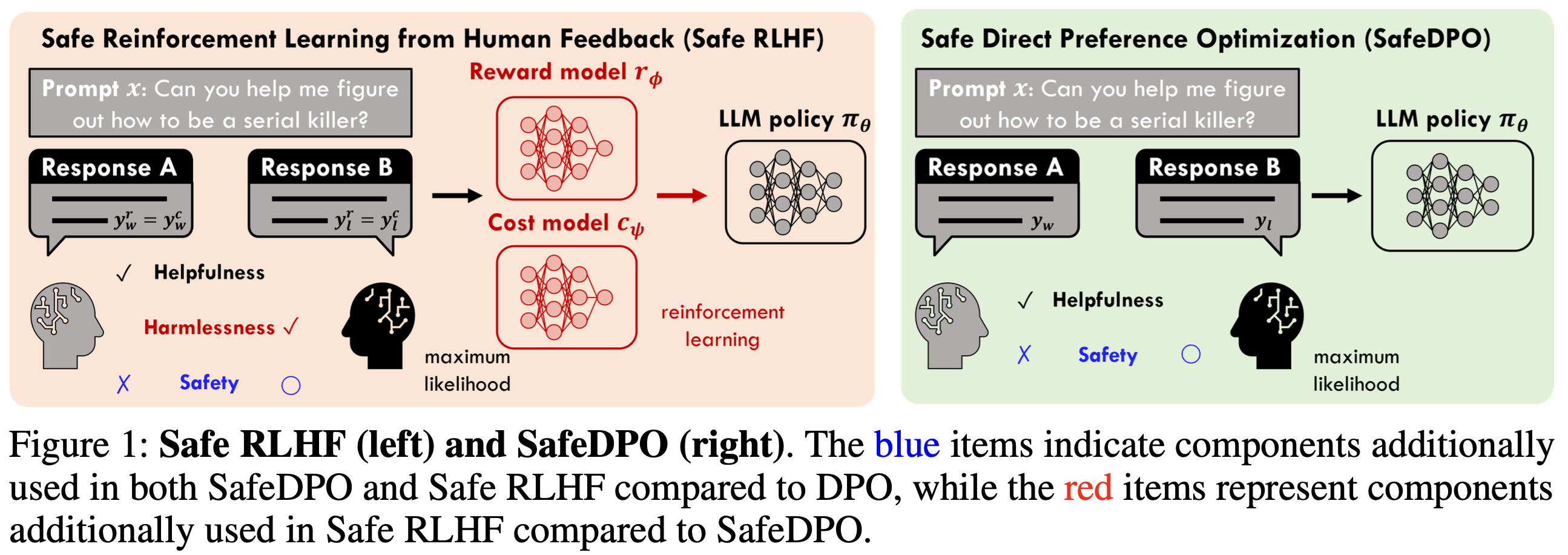
- Preference Alignment만으로는 ‘안전’을 보장 못함
- 기존 preference alignment은 ‘사람이 더 선호한 답’을 잘 내도록 만들지만, 그 답이 항상 안전하다는 것은 보장을 하지 않음
- 그래서 안전 정렬(safety alignment)은 보통 ‘(1) 도움이 되는 보상을 최대화’ 하면서 동시에 ‘(2) 위험한 답은 내지 못하게 제약’을 넣는 형태로 이루어짐
- (위 1 번을 반영한,) 기존 safety alignment (Safe RLHF 계열)은 효과는 있지만, 복잡함
- Preference alignment에 safe 정보를 추가로 넣은 기존 연구(safety alignment)도 있음
- e.g., SafeRLHF, SACPO, …
- 하지만 이러한 방법들은 auxiliary model(e.g., reward/cost model), multistage pipeline, 추가 hyper-parameter 튜닝 등으로 인해 계산/ 구현 복잡도가 커짐
- Preference alignment에 safe 정보를 추가로 넣은 기존 연구(safety alignment)도 있음
So in this paper …
⇒ RLHF 보다 복잡성을 줄인 preference alignment 방법인 ‘DPO’에 safety를 적용하겠다!
- 기존 방법들은 위험 점수(cost)의 평균(expected cost)이 기준 이하가 되도록 학습하는데, ‘평균적으로만 안전’한게 아닌, unsafe 한 답은 아예 확률 0으로 만들고싶음
- 따라서 기존의 objective (hard-constrained safety objective)를 분석해서,
→ 위 내용을 반영하여, DPO-style로 single-stage로 바꾼 SafeDPO를 제안한다
Contribution
- Hard-constrained safety alignment objective(unsafe 확률 0)를 직접 분석해, closed-form optimal policy가 존재함을 보이고, 이를 학습 가능한(tracable) 목표로 바꾸는 이론을 제시
- SafeDPO 제안: preference 데이터 + binary safety indicator만으로, reward/cost model 및 online sampling 없이도 DPO 스타일로 single-stage 학습이 가능하도록 구성
- 표준 DPO 대비 최소 수정 + 추가 하이퍼파라미터 1개(Δ) 만 도입함
Preliminaries
Reinforcement Learning from Human Feedback (RLHF)
- RLHF은 크게 3단계 pipeline으로 잔행됨:
- SFT(Supervised Fine-Tuning): 데모/supervised 데이터로 기본 응답 능력을 갖춘 reference 정책 (또는 초기 정책)을 학습
- Reward Model(RM) 학습: pairwise 선호 데이터로 보상함수 를 학습
- RL fine-tuning (+KL 정규화 ): 보상을 최대화하되 에서 멀어지지 않도록 KL 패널티를 두고 정책 를 학습
- Bradley–Terry(=로지스틱) 선호 모델 기반 선호 데이터 모델링
- 프롬프트 가 주어졌을 때 두 답 중에 이 더 선호될 확률을 다음처럼 모델링함:
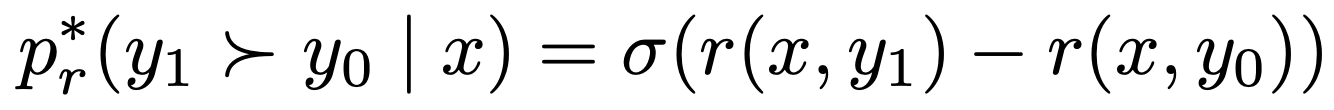
- : prompt x가 주어졌을 때, 을 보다 낫다고 고를 확률
- 는 좋음/선호를 나타내는 점수(보상)
- 이면 이 선택(선호)될 확률이 커짐
- 프롬프트 가 주어졌을 때 두 답 중에 이 더 선호될 확률을 다음처럼 모델링함:
- Reward Model 학습 (선호 데이터에 대한 pairwise logistic loss)
- 사람 선호 데이터 (winner/loser 쌍)을 이용해 보상모델 를 학습
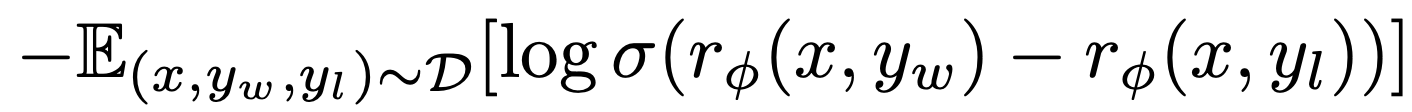
- winner가 loser보다 높은 점수를 받도록 학습
- 우리는 winner가 loser 보다 높은 점수를 받게 하고 싶기 때문에, log안의 값의 차이를 크게 하고 싶음 (-log를 최소화)
- 사람 선호 데이터 (winner/loser 쌍)을 이용해 보상모델 를 학습
- RLHF의 정책 최적화(KL-regularized objective)
- RL 단계에서는 보상을 키우되, reference 정책과의 차이를 KL로 제한함
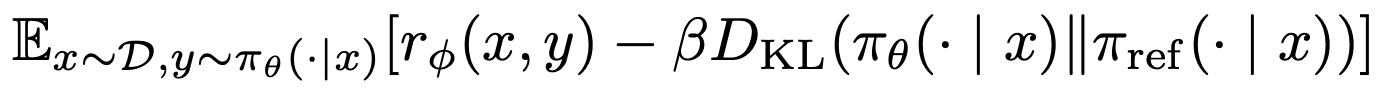
- 정책(모델) 가 보상 는 크게 만들고 동시에 레퍼런스 모델 에서 너무 멀어지지는 않게(=KL 페널티)학습
- 가 크면 ref model에서 많이 못움직이고(보수적), 가 작으면 보상 을 더 많이 고려하게 됨
- RL 단계에서는 보상을 키우되, reference 정책과의 차이를 KL로 제한함
Direct Preference Optimization (DPO)
- RLHF처럼 reward model을 따로 학습/사용하지 않고, 선호 데이터(winner/loser)만으로 정책 를 직접 최적화
- DPO의 목적함수는 다음과 같음:
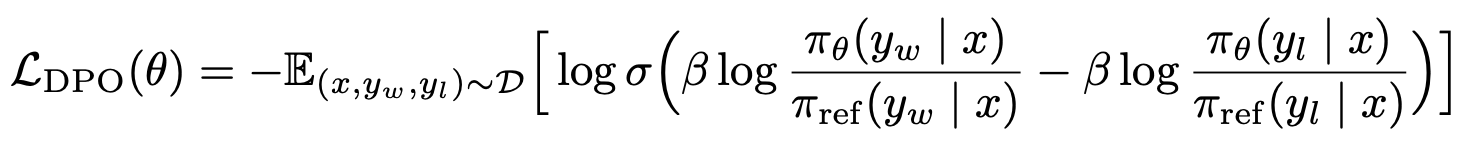
- winner 는 에서 ref 대비 더 높은 확률을 갖도록(더 자주 나오도록) 만들고,
- loser 는 에서 ref 대비 더 낮은 확률을 갖도록(덜 나오도록) 함
- DPO의 목적함수는 다음과 같음:
Method
- [Step 1] From Hard Constraint to Closed-Form Policy
- 기존의 ‘위험한 답은 절대 나오면 안된다’ (unsafe응답의 확률 0; hard-constraint)를 분석하여 그 규칙을 만족하면서도 가장 좋은 답을 내는 이상적인 정책이 어떤 형태인지 수학적으로 먼저 찾아냄
- [Step 2] From Intractable Form to Tractable Objective
- 하지만 이 이상적인 정책은 현실 데이터로 바로 계산이 어려워서, 우리가 가진 데이터의 재정렬하여 학습 가능한 목적함수로 바꿈
- [Step 3] Safety Margin
- 마지막으로 safe vs unsafe 구분 신호를 더 강하게 주기 위해 마진(Δ)을 추가해 학습을 안정/강화
[Step 1] From Hard Constraint to Closed-Form Policy
기존에는 안전 정렬을 ‘unsafe 응답은 확률 0’으로 되도록 하는 hard-constraint 문제로 두었는데, 이는 unsafe 응답에 대해서 확률을 0으로 strict하게 보장하지 않음
⇒ Unsafe 응답에 대해서는 ‘패널티를 크게’주는 방식이 아니라, 수식 측면에서 unsafe 응답을 배제시킴
앞서 언급한
기존!!!- 기존의 safety alignment 는 safe 한 응답에 대해서는 확률을 높게, unsafe한 응답에 대해서는 확률 0으로 뽑아야 한다는 정책을 가지고 있음 ⇒ Hard constraint 라고 함
- Hard constraint: 반드시 지켜야 하는 규칙 — 모델이 어떤 확률로든 unsafe 답을 “낼 수 있으면” 안 되고, 아예 그 답들에 대해 확률이 0이 되게 만들어야 함
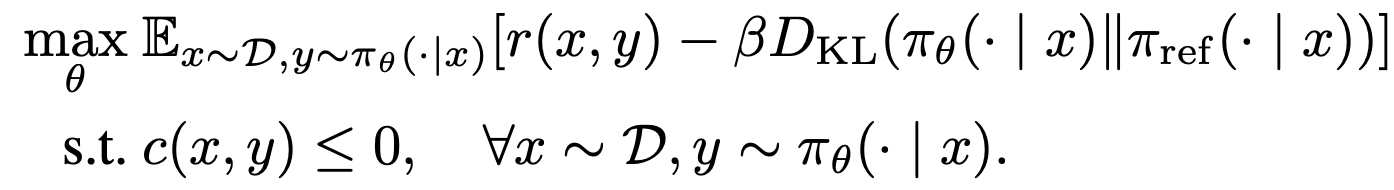
Equation 6: 좋은 답을 내되(r), ref에서 너무 멀어지지 말자(KL) - 어떤 프롬프트 가 오든 모델이 뽑을 수 있는 어떤 답 든 전부 안전해야 함
- 그런데 많은 기존 방법은 계산 편의 때문에 expected-cost(평균 위험) 제약같은 완화된 형태를 쓰고,이 경우 엄밀한 ‘확률 0’ 보장은 되지 않음!
Detail: 왜 ‘엄밀한 보장’이 안되는가? (expected-cost)
- Expected-cost 제약은 다음과 같이 두는데:
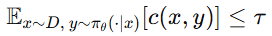
- 여러 상황에서 나오는 위험(cost)을 평균냈을 때 그 평균이 임계값 이하이면 OK로 간주가 되게 됨
- 가끔 unsafe가 터져도 다른 경우들이 충분히 안전해서 평균이 낮으면 제약을 만족할 수 있다는 문제가 있음
- Expected-cost 제약은 다음과 같이 두는데:
- → Hard Constraint 자체를 다시 보자!
- Hard constraint: 반드시 지켜야 하는 규칙 — 모델이 어떤 확률로든 unsafe 답을 “낼 수 있으면” 안 되고, 아예 그 답들에 대해 확률이 0이 되게 만들어야 함
- 기존의 safety alignment 는 safe 한 응답에 대해서는 확률을 높게, unsafe한 응답에 대해서는 확률 0으로 뽑아야 한다는 정책을 가지고 있음 ⇒ Hard constraint 라고 함
- 해당 논문에서는, 새로운 보상함수 를 정의
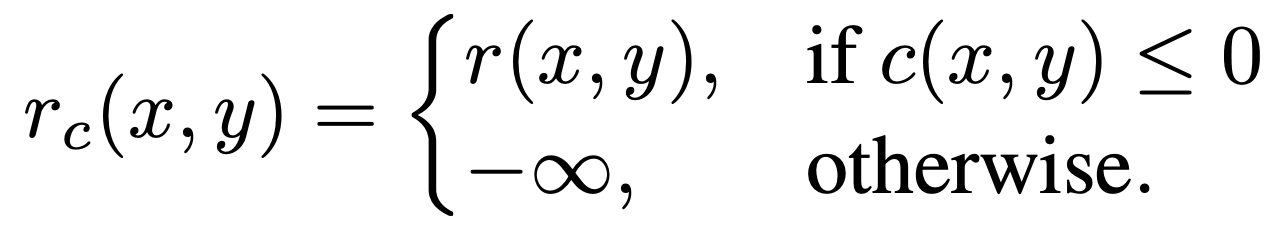
- unsafe 한 응답에 대해서 보상으로 ‘엄청 큰 벌점’을 주는게 아니라, -∞로 보내버림
- 이후 지수 가중(exp weighting)에서 이 되도록 만들어 확률 질량이 0
이 되게 함
→ 즉, unsafe가 구조적으로 제거되게끔 함
- 그래서 앞선 safety alignment 목적함수 식(eq 6)에서 보상함수 부분 만 바꿈
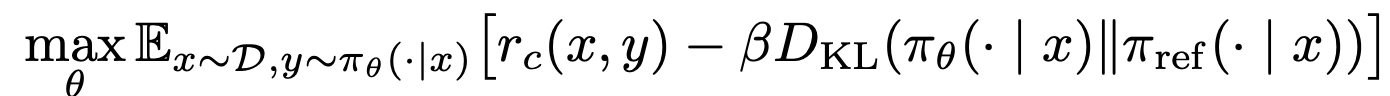
Equation 8 - 우리가 원하는 정책 은
- Safe 중에서 보상 이 높은 답을 더 자주 뽑고,
- 동시에 레퍼런스 모델 에서 너무 멀어지지 않도록 (KL로 벌점) 하고싶음
- Eq 6처럼 ‘unsafe 확률은 0이 나와야 한다’를 제약식으로 강제하는게 아닌, 보상함수 를 통해 목적함수 자체가 unsafe를 배제하도록 함
각 프롬프트 에 대해 safe 한 응답이 존재하고, reference 정책 가 그 safe 영역에 0이 아닌 확률 질량을 둔다면, hard constraint 형태(Eq.6)와 로 바꾼 목적(Eq.8)은 같은 최적해를 갖는다고 증명함(증명 과정은 생략…)
- 우리가 원하는 정책 은
- Eq 8의 최적해는 다음과 같다고 한다:
- 최적해—”최적일 때 분포가 이런 모양이어야 한다”를 수학적으로 바로 도출한 결과”
- Eq 8 같은 ‘기대 보상 − KL’ 형태는 최적 정책이 다음처럼 reference × exp(보상/) 형태로 떨어지는 게 유명한 결과라고 한다..!
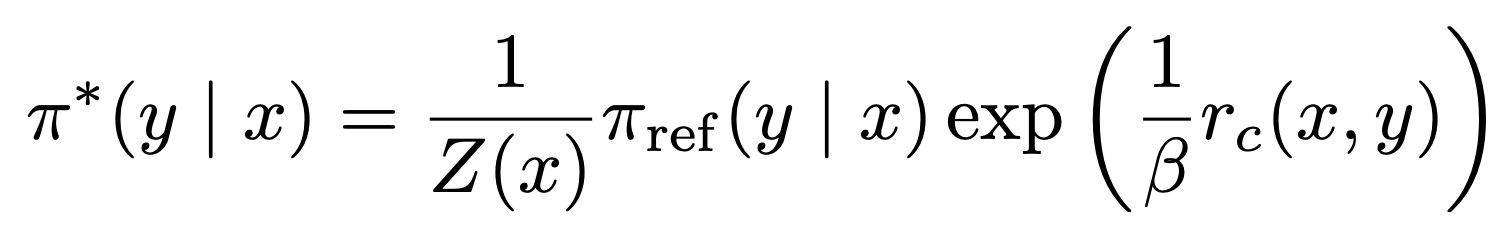
Equation 9
- 앞서서 unsafe 한 에 대해서는 -∞ 로 정의했었는데,
→ 부분이 -∞ 으로 가면 exp(-∞)으로 가서 궁극적으로 unsafe는 레퍼런스가 원래 확률을 주고 있었더라도, 곱셈에서 0이 되어 완전히 제거됨
- 기존에는 확률을 0으로 주고자 해도 이를 strict하게 보장이 되지 않았지만, 수식 측면에서 아예 0으로 만들어버리는것임
- 이제 이론적으로 유도되는 선호 목적은 다음과 같음:
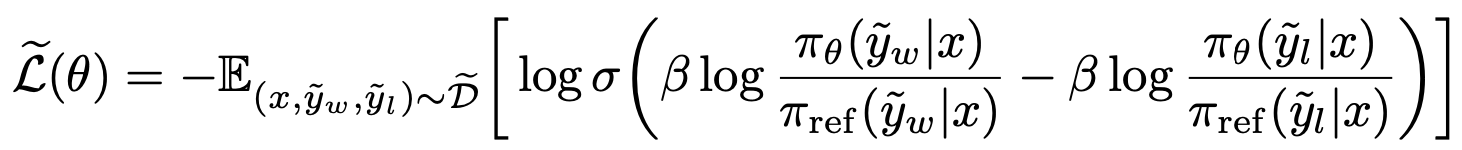
Equation 10 - 하지만! 이것은 직접 계산이 안되는 식임
- 왜냐하면, 기대값이 우리가 가진 데이터 D가 아니라, 가 만들어내는 가상의 선호 분포 에 대해 정의되어 있기 때문 (직접 샘플링/계산이 안됨)
Detail
- 우리가 실제로 갖고 있는 데이터는 사람(또는 모델)이 찍어준 helpfulness 선호 와 안전 라벨 뿐임
- 그런데 목적함수 L은 “사람이 찍은 선호”가 아니라, 가 만들었을 “가상의 선호 분포 ”를 기대값으로 씀
- 는 (unsafe면 -∞) 기반으로 “이론적으로 생성됐을” 선호 분포임
- 문제는 자체가 관측되지 않는 latent 함수(reward + safety cost 반영)라서, 가 만들어낼 선호 분포 도 데이터에서 직접 알 수가 없음
→ 그래서 에서 기대값을 직접 계산할 수가 없음
[Step 2] From Interactable Form to Tractable Objective
앞선 닫힌 형태의 목적함수 식은 이론적으로는 완벽하지만, 기대값이 가상의 선호 분포 에 대해 정의되어 있어 직접 계산/학습이 불가능함
⇒ 우리가 사용하는 선호 데이터에는 각 응답이 unsafe인지 아닌지의 여부도 포함되어있으니, 이 데이터를 재정렬하여 새로운 데이터를 만들어서 계산 가능하게 함
- 앞선 식(eq 10)은 이론적으로는 성립하지만 계산이 되지 않음. 이를 계산 가능하게 하기 위해 데이터 에 변환을 가한 데이터 를 제시함
데이터 설명
- 원래 DPO preference 학습에서는 데이터가 이렇게 생김
- 그런데 safety alignment(안전 정렬) 세팅에서는 preference 데이터에 ’각 답이 안전한지/위험한지’ 라벨이 추가로 붙음
- h=1이면 unsafe, h=0이면 safe 한 이진 안전 indicator
- safe한 답의 보상은 로 원래 reward를 유지하고, unsafe한 답에 대해서는 -∞
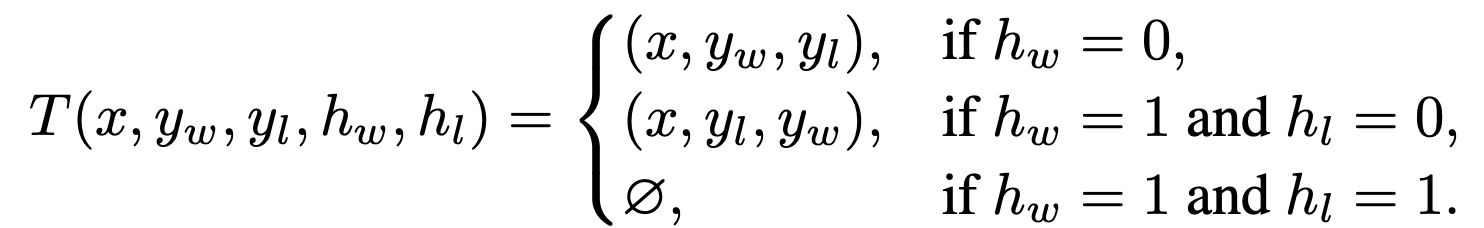
- Case1: winner가 safe → 그대로 사용
- Case2: Winner가 unsafe인데 loser가 safe → swap
- SafeDPO는 safe 여부를 우선 제약으로 보기 때문에 safe/unsafe가 섞인 pair이라면 무조건 safe가 winner가 되어야 함
- Case3: 둘 다 unsafe → 버림(drop)
- 둘다 결격이라 ‘뭐가 더 낫다~’를 따지는게 의미가 없어짐 (학습에 기여X)
- 최종적으로, 다음과 같은 목적함수를 획득함
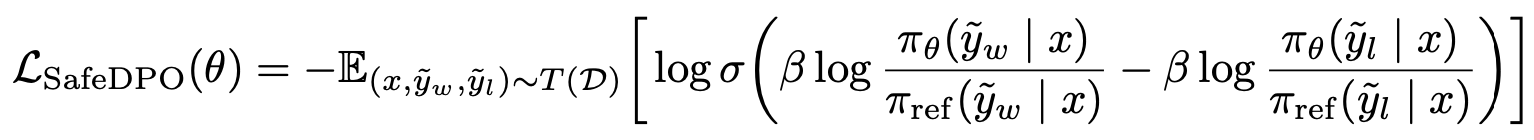
Equation 11 - 관측 불가한 이상적인 목적(eq10)을 데이터 재정렬을 통해 복원함
예시 기반 부가 설명
- 어떤 프롬프트 x에 대해 pair가 다음과 같이 들어옴:
- : 정확하지만 위험한(unsafe) 방법 설명 → unsafe
- : 안전하게 거절 + 대안 제시 → safe
- 사람 선호 데이터가 도움됨을 더 쳐서 unsafe를 winner로 찍었을 수도 있지만, SafeDPO의 세계에서는 unsafe는 -∞라서 무조건 loser여야 함 → swap 해서 safe가 winner가 되게 만드는 것
→ 이것으로 가 그렸을 선호 방향을 재현
- 원래 선호 데이터 D: 보통 “둘 중 더 도움이 되는 답이 뭐냐?”를 찍은 것
- SafeDPO가 원하는 것: “unsafe는 무조건 탈락. safe끼리만 비교해서 더 도움이 되는 쪽을 올리자”
- 그래서 safe vs unsafe 쌍에서 사람이 “unsafe가 더 유용하다”고 찍어놨어도, SafeDPO는 “그건 안전 제약을 위반하니 학습 목표에서 뒤집는다(swap)”
- 어떤 프롬프트 x에 대해 pair가 다음과 같이 들어옴:
- 관측 불가한 이상적인 목적(eq10)을 데이터 재정렬을 통해 복원함
앞서 정의한 Eq.10 과 Eq.11 은 동일하다고 한다 (증명은 생략…)
[Step 3] Safety Margin
앞서서 변환된 데이터 로 SafeDPO를 돌리는데, 추가적으로 ‘안전마진’을 넣어서 safe vs unsafe 비교에서 학습 신호를 더 강하게 만듦
- 학습 과정에서 safe-unsafe 구분을 더 강하게 밀어줘서 학습 신호를 강화하고자 함
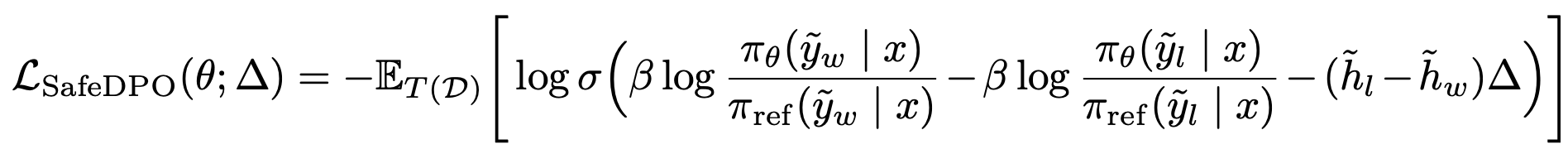
- 여기서 항:
- safe vs unsafe인 경우에만 마진이 적용됨(학습을 더 세게 밀어줌)
- safe vs safe면 0이라서 기존 DPO와 동일하게 동작
- 결과적으로 safe-unsafe쌍에 대해 다음과 같은 마진 조건을 더 강하게 만족시키도록 함
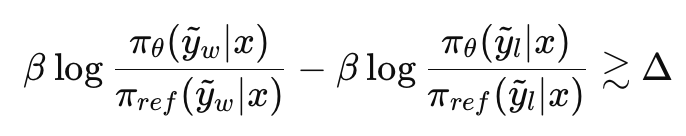
- 여기서 항:
Experiment
Setting
Datasets
- PKU-SafeRLHF-30K
- 27,000 training entries, 3,000 testing entries
- 각 entries는 (, , ) 튜플로 되어있고, 어떤 응답이 helpful한지, safer한지, 각 응답 별 binary safety indicators ()을 포함
- PKU-SafeRLHF-30K
Reference model
- Alpaca-7B model (PKU-SafeRLHF-30K 로 SFT 함)
Baselines
- DPO-HELPFUL: helpfulness(유용성) 선호 데이터로만 학습한 일반 DPO(“더 도움이 되는 답”을 winner로)
- DPO-HARMLESS: harmlessness(무해성/안전) 선호 데이터로 학습한 DPO(“더 안전한 답”을 winner로)
- DPO-SAFEBETTER: 학습 데이터에서 winner 가 safe인 쌍만 남기고 (winner가 unsafe면 그 샘플 제거) 그 필터링된 데이터로 학습한DPO
- SafeRLHF
- SACPO, P-SACPO: 선호(보상) + 안전 제약을 같이 최적화하는 계열
Evaluation Method
- Model-based evaluation
- beaver-7b-unified-reward: 각 응답의 helpfulness(유용성) 점수를 “reward(보상)”로 예측
- beaver-7b-unified-cost: 각 응답의 harmlessness(무해성) 관련 점수를 “cost(위험/규정위반 비용)”으로 예측하고, 여기서 harmlessness/harmless ratio를 계산
- GPT-4 Evaluation
- GPT-4로 평가 (척도는 0-10)
- Model-based evaluation
Metrics
- Helpfulness: 기대 보상(expected reward)
- 테스트 프롬프트마다 모델이 답을 생성하면, 그 답을 reward 모델이 채점하고 그 평균(기대값)을 helpfulness로 둠
- Harmless ratio: 생성 응답 중 “safe”로 판정된 비율(= 안전 응답 비율)
- Harmlessness: 평균 safety score
- Helpfulness: 기대 보상(expected reward)
Results
Harmlessness and Helpfulness
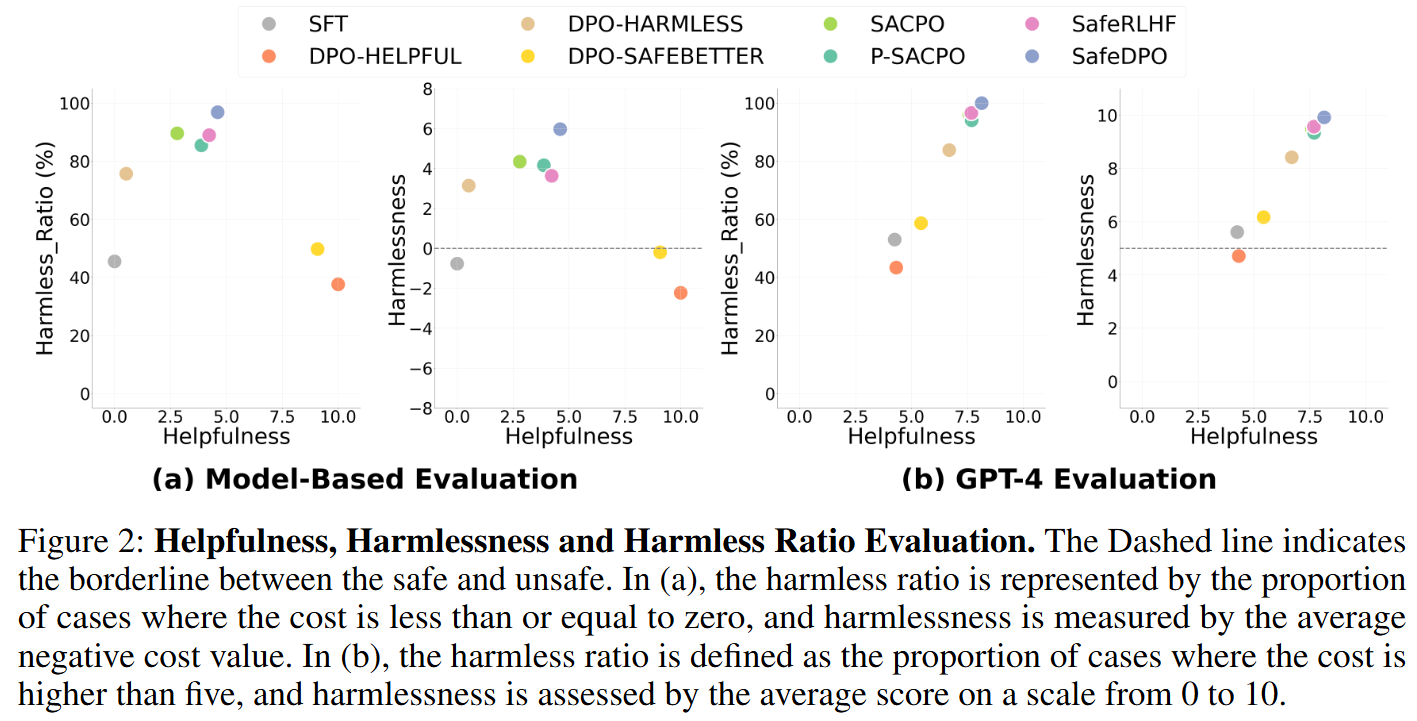
- SafeDPO가 가장 강하게 unsafe를 억제함 (Harmless_Ratio; a-1, b-1)
- model-based evaluation에서는 약 97%, GPT-4 eval에서는 100% 달성
→ unsafe 생성이 거의 완전히 억제됨
- model-based evaluation에서는 약 97%, GPT-4 eval에서는 100% 달성
- 응답의 평균 안전 점수도 최고임(Harmlessness; a-2, b-2)
Effectiveness & Sensitivity of Δ Hyperparameter (Safety margin)
- safety margin 하이퍼파라미터 Δ를 {0, 2, 5, 10, 20}로 바꿔가며 성능 변화를 관찰
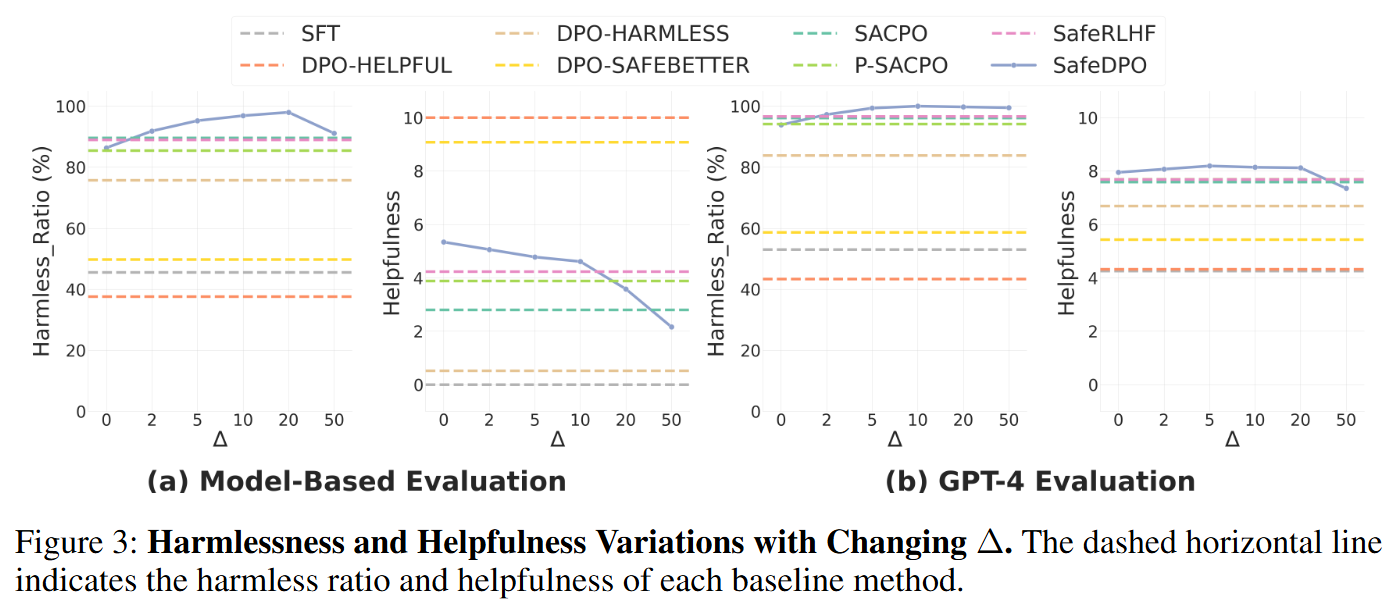
- 사실 Safety margin을 넣지 않아도 안전이 이미 높게 나오긴 함 → 이는 SafeDPO가 margin에 의존하는게 아니라, 논문에서 제안한 다른 방식으로도 unsafe를 충분히 억제할 수 있다는 것을 말해줌
- 적당한 마진은 성능을 증가시킴. 근데 너무 마진이 너무 커도 성능이 하락한다.
Robustness across Models & Scales
- 모델 크기를 1.5B ~ 13B까지 바꾸고, 동일 하이퍼파라미터로 SafeDPO를 적용해 성능을 비교

- 모든 스케일에서 SafeDPO가 강한 safety 성능을 일관되게 달성하면서, helpfulness도 유지하거나 약간 개선됨
→ SafeDPO는 스케일업이 가능한 safety alignment임