19 March 2026
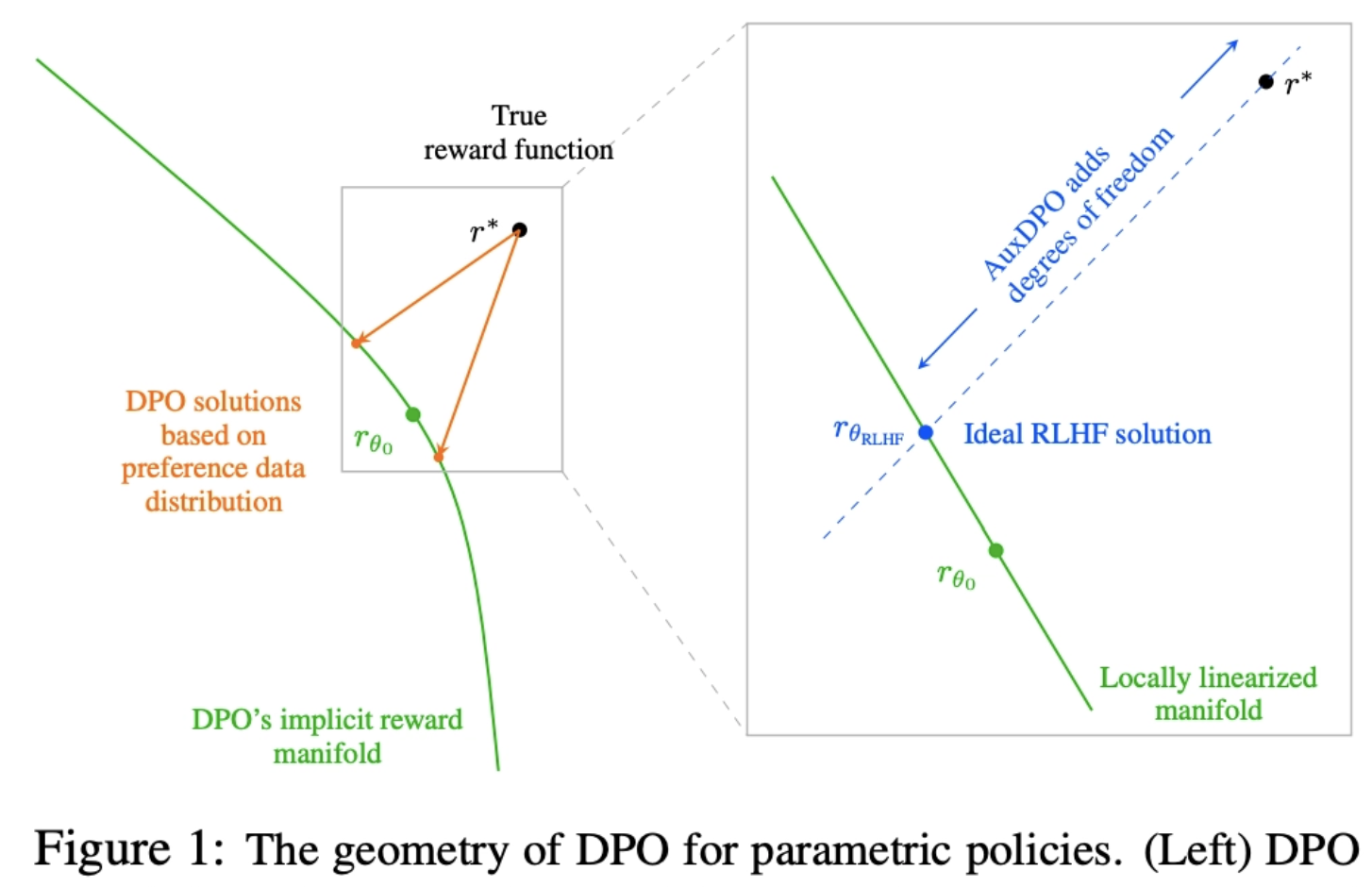
Why DPO is a Misspecified Estimator and How to Fix It
ICLR'26 Oral
💡DPO의 전제가 realistic하지 않음을 위상학적으로 파헤침 AuxDPO를 통해 DPO의 Misspecifection를 완화하자!
19 March 2026
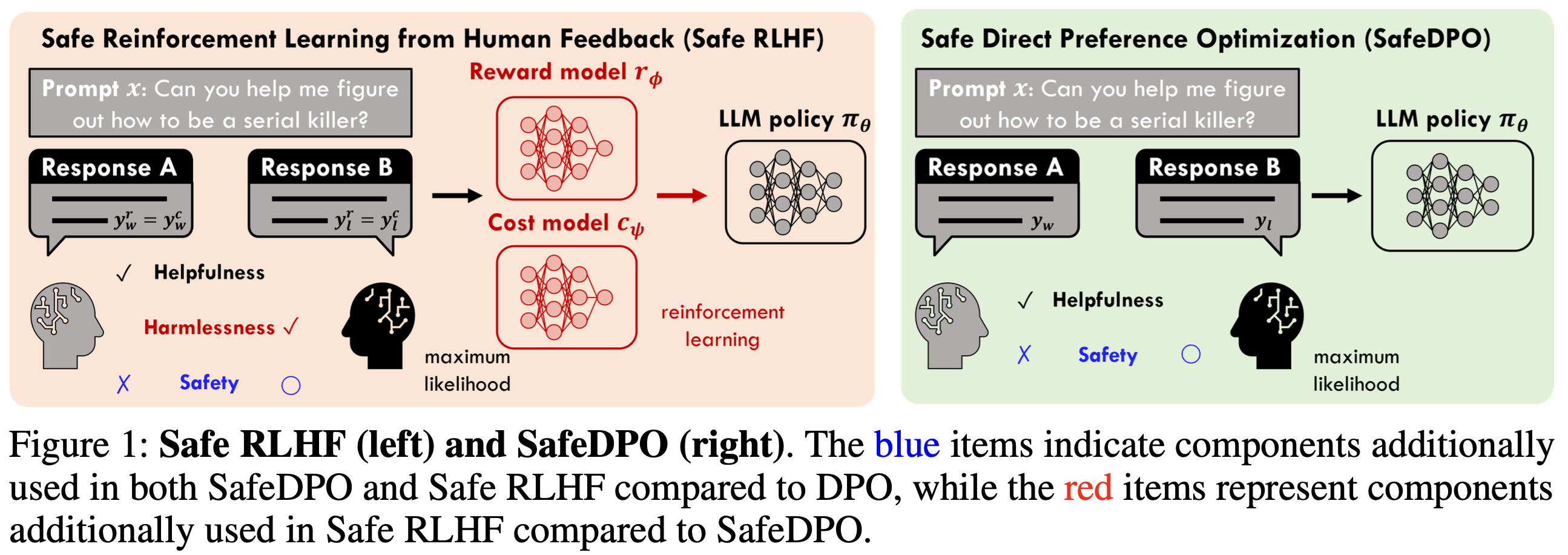
SafeDPO: A Simple Approach to Direct Preference Optimization with Enhanced Safety
ICLR'26 Oral
💡Preference Alignment에서 안전(위험한 답X)을 강하게 보장하면서도, 기존 RLHF처럼 복잡한 파이프라인 없이 DPO처럼 간단하게 모델을 정렬하는 방법인 SafeDPO 를 제시기존의 보상 함수를 재정의하고, 학습 데이터를 재정렬해 모델이 안전한 답을 일관되게 더 선호하도록 함
19 March 2026
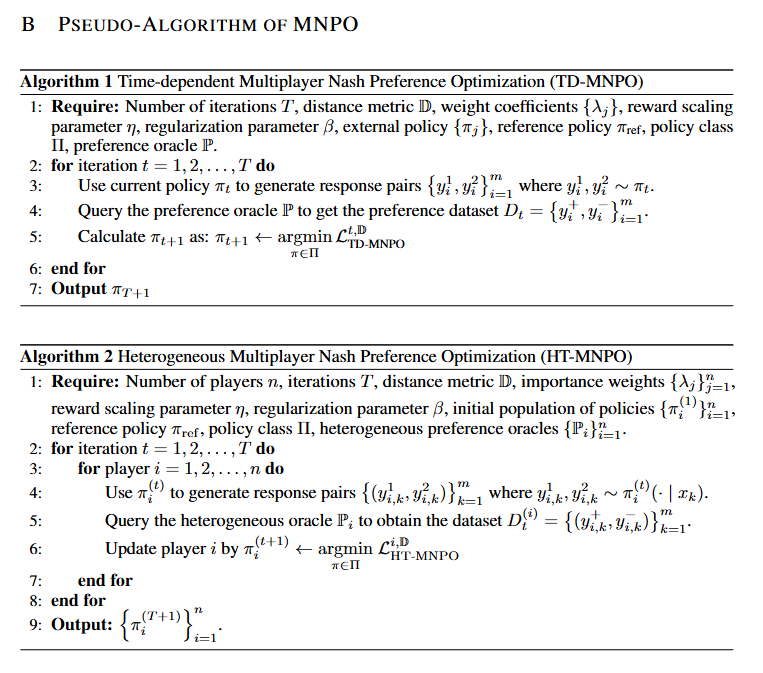
Multiplayer Nash Preference Optimization
ICLR'26 Poster
💡alignment가 가져야 할 목표는 보상을 최대화하는 것이 아니라, 다수 가치 및 정책 집단 속에서 그 누구에게도 지지 않는 안정적 균형 상태를 가지는 것이다!
19 March 2026
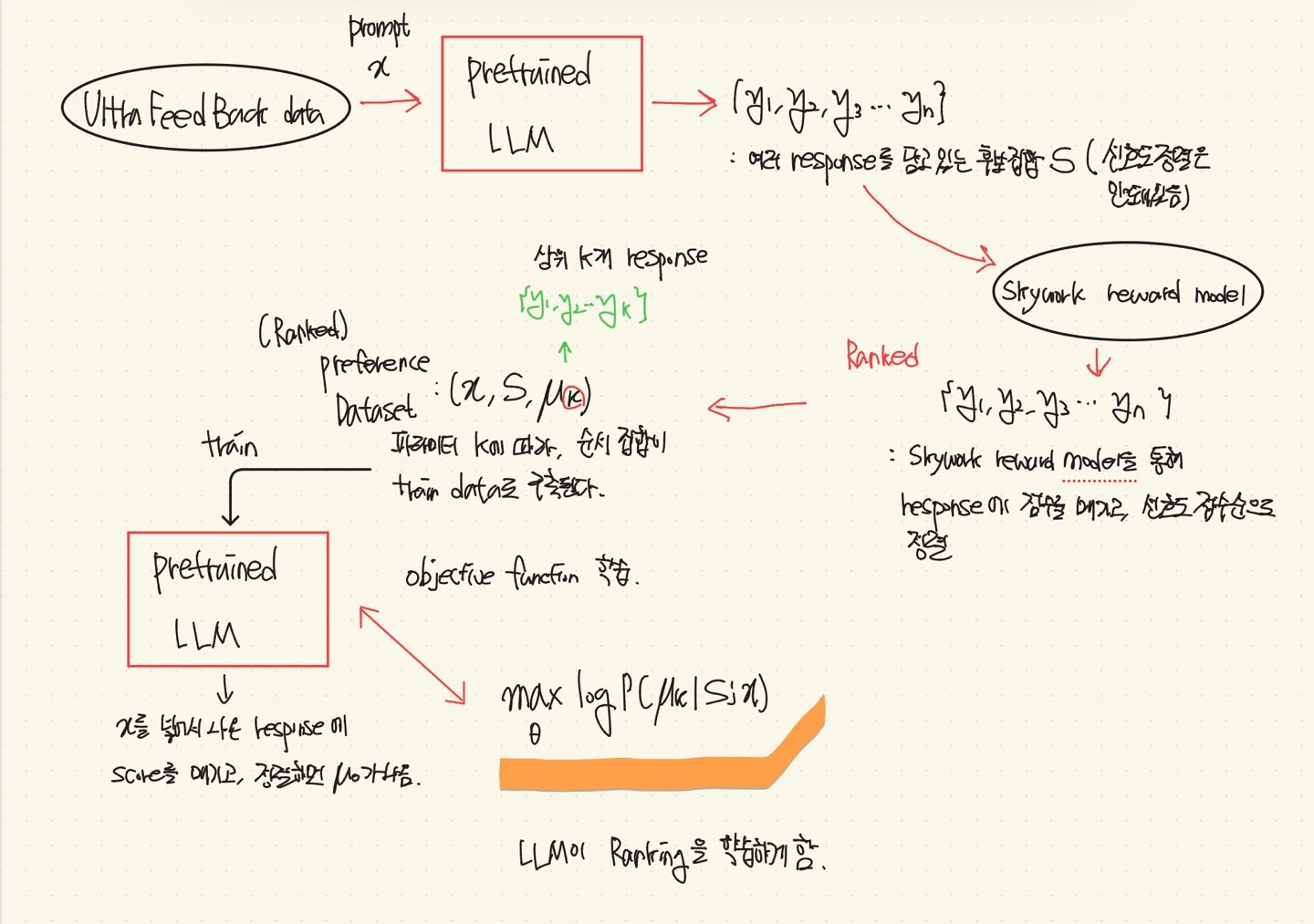
Beyond Pairwise: Empowering LLM Alignment With (Ranked) Choice Modeling
ICLR'26 Poster
💡RLHF나 DPO와 같은 방법들은 Pairwise(쌍) Preference Optimization에 맞춰져 있어, 더 자세한 정보(Human Feedback)를 학습할 기회를 간과한다.⇒ Response에 대해 Pairwise뿐만 아니라, 그 이상까지 rank를 매겨 모델에 학습을 시켜보자.