Exploring the Limit of Outcome Reward for Learning Mathematical Reasoning
Review
| 닉네임 | Strength & Weakness & Sugguestions | 별점 (0/5) |
|---|---|---|
| 댓츠노노 | • 장점: positive trajectory, negative trajectory를 모두 고려하여 sparse reward를 보완함 / reward에 token 별 중요도를 고려함으로서 robustness 꾀함 • 단점&보완점: QWEN 말고 다른 LLM family에 적용하는 실험 부족! (e.g. Deepseek prober 처럼 NR에 특화된 모델들) | 3.8 |
| 아이리스 | 장점; 좋은 기술적 논문임. 개인적으로 trajectory라는 키워드에 관심이 많은데, 강화학습에 잘 적용한 논문이라고 생각함. 단점: 효율성은 잘 모르겠고, 성능도 잘 모르겠음. 보완점: 물론 강화학습이 그렇지만, 못 푸는 것을 풀 수 있게 만들었는지 실험하는 것도 재밌을듯. 개인적으로도 생각 중인 방향이라 궁금함. 이전에 관련된 연구가 있었는데, 생각나면 적겠습니다 | 3.8 |
| 핸드크림 | • 장점: 샘플링 통해 각 질문에 대한 positive/negative 답변을 모두 얻고 학습에 사용. 중간 보상 사용 • 단점: 샘플링 답변의 품질이 보장될 것인지, 토큰별 기여도가 좋은 중간 보상일지 의문 • 보완점: 학습 데이터 품질 보장하는 단계 추가 | 3.5 |
| 3월 | • 장점: 수학문제 추론에 적합한 환경을 설정함. 중간 추론 과정인 trajectory가 가장 어울리는 분야라고 생각함! • 단점: reward 모델이 틀리면...? 중요하지 않은 토큰이 중요하다고 학습할 수도 있음 • 보완점: 모든 정답에 동일한 reward를 부여하지 않고 불확실성을 고려해서 문제 난이도에 따라 차등 부여 | 3.5 |
| 화이트노이즈 | • 장점: reward가 0/1로 sparse 하다는 motivation이 독특하고 이를 trajectory를 통해 실제로 좋은 성능을 보임 • 단점: BON 샘플링에서 N이 커질수록 계산비용이 많이 들 것 같음 • 보완점: 수학 데이터셋 이외에 다른 데이터셋에도 방법론이 적용 가능할지 궁금함 | 3.1 |
| 피즈치자 | • 강점: process reward를 쉽게 구축할 수 없다는 현실적인 문제점을 잘 직시하고, outcome reward로 도달할 수 있는 상한선을 보려는 시도가 좋음 • 약점: 근데 완전 순수한 'final-answer supervision'은 아니네. trajectory 단위의 활용과 token-level reward등이 들어가기 때문에 trajectory가 충분히 확보되지 않을 때는 그대로 적용하기 어려울듯 • 제안: trajectory selection에서 pos/neg 여부 뿐 만이 아니라 품질에 따라서 결과가 어떻게 달라지는지 궁금함 | 3.9 |
| 에너지 | • 장점 : reward sparse문제를 reasoning에 reward를 분배함으로써, LLM이 결과 기반의 reasoning이 아닌 (과정+결과) 기반의 reasoning을 학습할 수 있게 함. • 약점 : trajectory의 토큰이 많을 때(풀이가 긴 문제, 어려운 문제)는 reward가 비슷하게 분배될 것 같은데 이런 경우는 reasoning을 잘 할 수 있을까? • 보완점 : reward 분배 과정을 더 효율적으로 할 수 있게 초기에 데이터 설정(trajectory 분포)을 건드린다든지.. 추가 방법이 제시될 수 있을 것 같음. | 3.4 |
| 제로콜라 | • 장점: 최종 정답의 맞고틀림 신호만으로는 풀이 과정 전체를 평가하기 어렵다는 문제를 지적하고, reward를 토큰 단위로 쪼개 분배하는 아이디어가 직관적으로 납득이 됨. • 약점: 풀이 길이가 길어질수록 토큰이 많아지고, reward가 그 토큰들에 분배되다 보면 각 토큰이 받는 신호가 너무 작아져서 어떤 부분이 핵심인지 구분이 어려워질 것 같음. • 보완점: 수학 추론 문제에만 집중한 실험이라 다른 분야에도 같은 방식이 잘 작동하는지 궁금하고, 다양한 도메인에 적용해보는 실험이 추가되면 좋을 것 같음. | 3.4 |
| 창백카츄 | 장점: RL 매커니즘을 효율적으로 구현함 약점: 뭔가 연구를 거꾸로 한 것 같음. 방법론의 rationale을 잘 모르겠음. 그래서 별로 임팩트있게 다가오지는 앟음 제안점: 틀리게 된 시점에만 피드백의 강도를 올리는게 좋을 것 같음 | 2.5 |
| 오차 | 장점: RL을 reasoning에 간접적으로 구현함으로써 문제 해결을 효율화한 점이 강점임. 약점: 이게 무슨 의미가 있는지 와닿지 않음. 제안점: Reeward나 피드백 방식을 좀 더 효율적으로 할 수 있도록 Reasoning 방법을 바꾸어 봐도 될 것 같음. | 3.4 |
Author

Citation : 42
TL; DR
Mathematical Reasoning Task 를 할 때, RL을 간접적으로 구현하여 간단하게 풀어보자.
(= 강화학습 형태로 수학문제를 효과적으로 풀어보자 !)
Summary
Introduction & Background & Motivation
Introduction & Background
최근 LLM 모델들은 Reasoning을 잘하는데,
그 원인으로는 RL(강화학습) + COT(긴 사고 과정)기법이 채택됨.
하지만, Mathematical Reasoning을 기존 RL 방식으로 접근할 때, Sparse Reward 문제가 발생함.
또한, 강화 학습의 매 step마다 reasoning을 하는 것은 노동적인 측면에서 매우 비효율적임.
example
❓Q ) 1 + 3 x 2 + 5= ?
= 1 + 6 + 5 (reasoning)
= 7 + 5 (reasoning)
= 12 (reasoning)
step마다 계속 평가하는 것은 비효율적.
⇒ 따라서 결과값에 대해서만 reward를 평가하는 것이 효율적일 것 같지만,
많은 추론과정을 스킵하고 결과에 대해서만 평가하는 것은 Sparse 하다.
수학적 추론을 위해 LLM을 사용할 때,
LLM policy의 입력은 여러 토큰으로 구성된 다단계 추론 과정을 출력하도록 유도한다.
일반적인 RL 방식은, LLM policy가 여러 reasoning trajectory(풀이 과정)을 샘플링(생성)하고,
최종 답변의 정확성만 참고하여 binary feedback(정답1/오답0 reward)을 통해 policy를 최적화한다.
Symbol
마르코프 결정과정 형태(MDP) =
: 지금까지 쓴 풀이 / : 다음에 올 토큰 / : 다음 상태로 가는 규칙 /
: reward / : discount factor
policy = 현재 LLM 모델이 생성 정책(어떤 값을 어떤 확률로 생성하는가 ~ ?)
trajectory = 추론 과정(=풀이 과정)
⇒ Positive trajectory(정답 풀이) / negative trajectory(오답 풀이)
Policy 최적화 objective
= 기존 모델에서 너무 멀어지지 않게, Reward를 최대화
위의 수식을 풀면,
최적 policy의 형태가 나온다. (= 기존 확률 x exp(보상 기반의 weight))
Best of N sampling
하나의 문제를 N번 풀게해서 제일 reasoning(풀이)을 잘한 답 하나를 고르는 것
Reward 구조
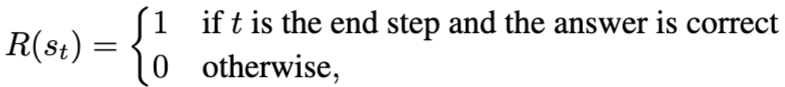
문제에 대한 최종 답변에 대해서 정답(1), 오답(0)으로 결과에 대해서만 reward를 부여함
Problem)
- 결과에 대해서만 reward를 고려하므로, sparse하다.
(실제 추론과정까지 포함하면 token수가 많은데, reward를 한번만 고려하는건 이상함)
- 틀린 추론 과정이 있어도 정답만 맞으면 된다.
(이렇게 되면, 잘못된 풀이법이 학습됨)
Motivation
계산 결과에 대한 reward는 0,1 값이고, 이 값에만 의존하는건 너무 sparse 하다.
(positive trajectory가 sparse한 경우, gradient가 없음)
⇒ Outcome reward만 보고 모델을 update하면 안된다
Contribution
기존 방식에서는 negative trajectory가 더 학습이 되었으므로, positive trajectory가 더 잘나오게 보정
- 문제를 풀려면 정답 풀이과정이 충분히 학습돼야함.
- positive trajectory가 적어도 하나는 꼭 뽑힐 수 있게, BON을 사용
- negative trajectory도 학습할 수 있게 추가 보정함.
outcome reward의 결과 의존 문제를 trajectory의 token 의존도로 분해해서 학습
- trajectory에 등장하는 풀이과정의 토큰에 가중치를 매긴다면, 어느 풀이과정이 중요한지 학습 가능함.
- Outcome reward 1(정답), 0(오답)에 맞춰 토큰별 가중치를 학습.
- 업데이트 된 가중치를 기반으로 Policy Update
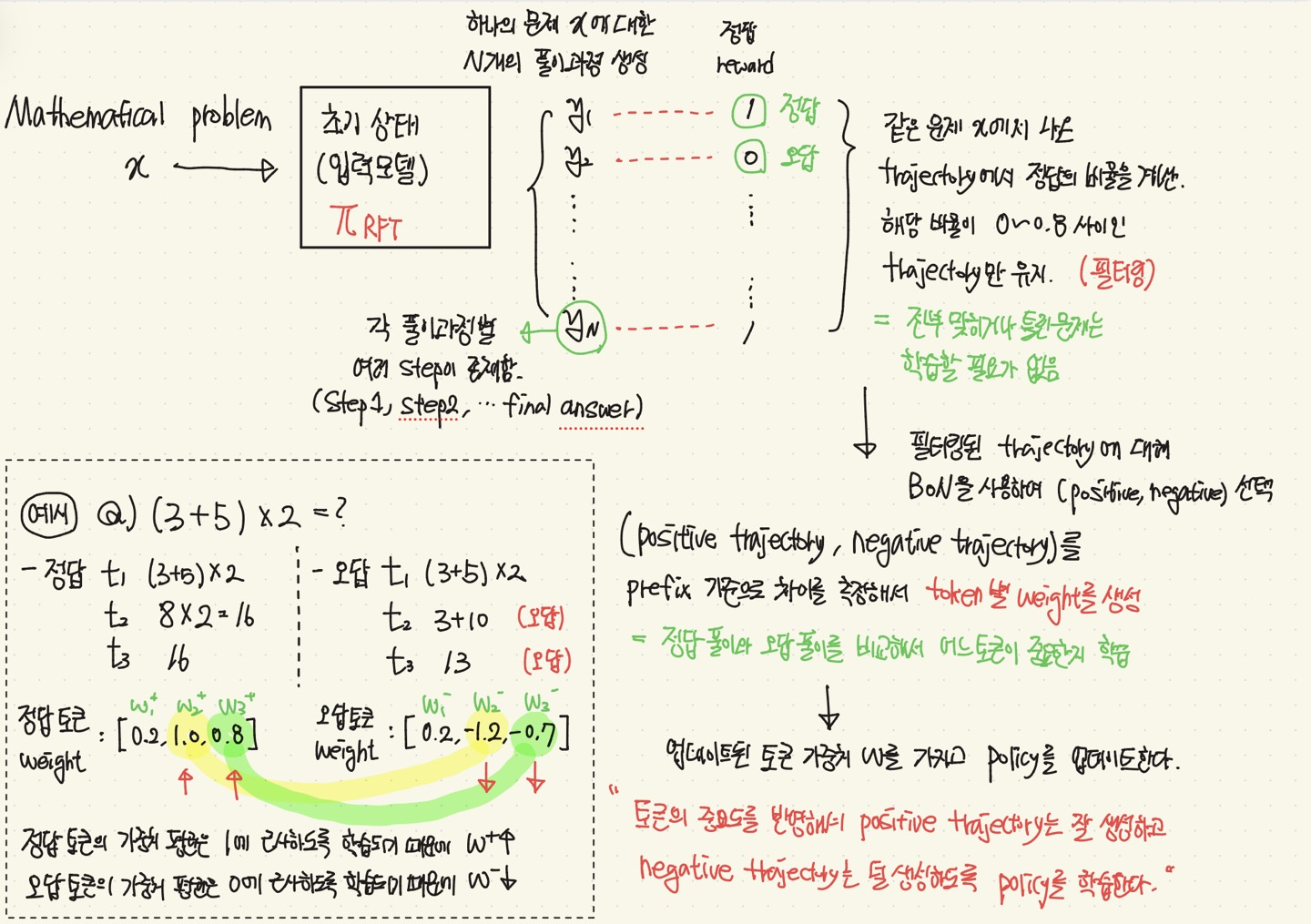
전체 파이프라인
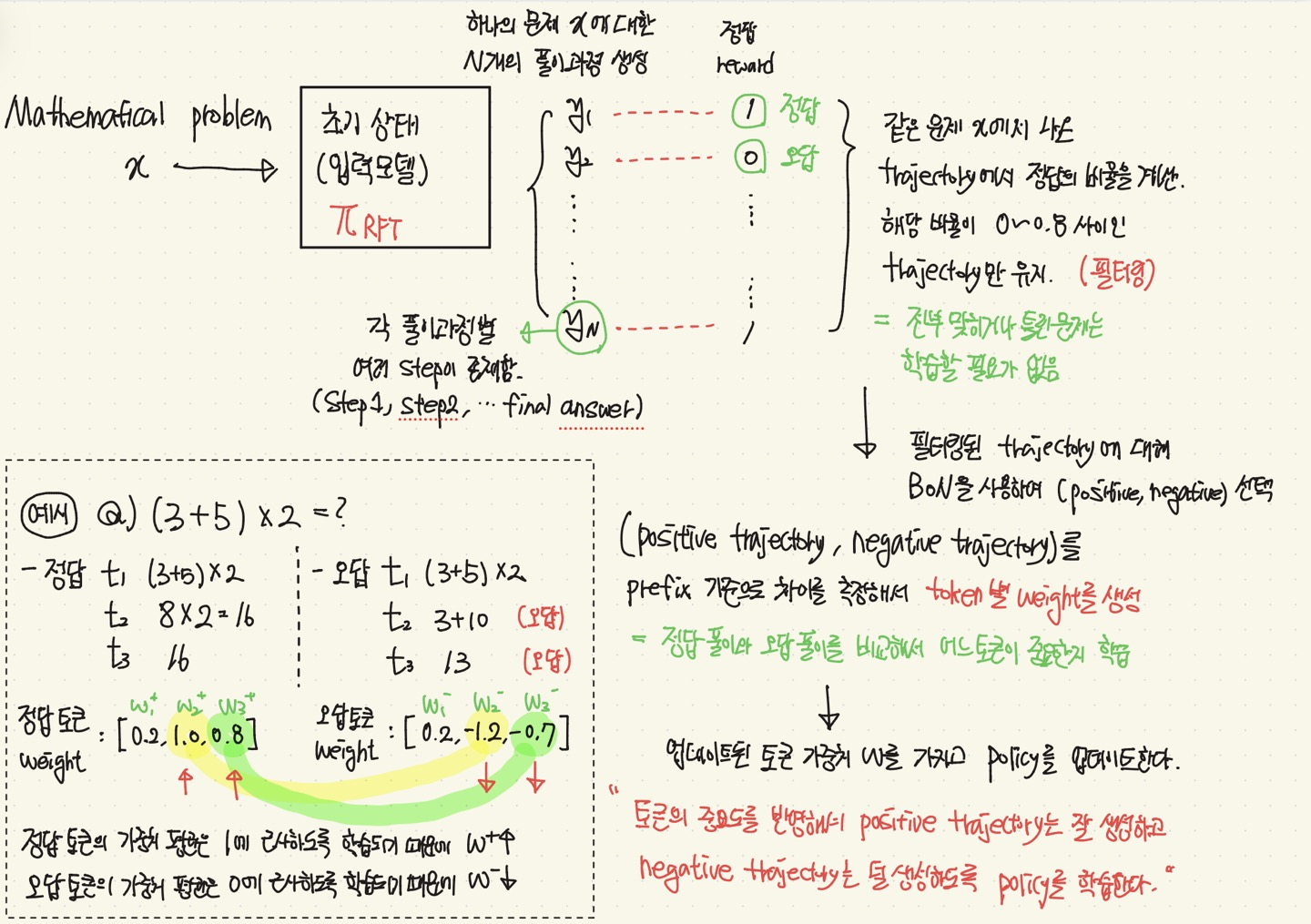
Method
Learning from positive sample
: positive trajectory s가 뽑힐 확률샘플량 N을 늘릴수록, 적어도 1개 이상은 positive가 뽑힘.
why?) 논문에서는 sampling시 오답이 많이 뽑히는 문제를 전제로 reward sparse를 지적함. 따라서, 적어도 하나의 positive trajectory가 선택될 수 있게 BoN을 사용함.
e.g.,)
- 기존 RL : 문제를 보고 계산 → 틀림 → 업데이트 (이 경우에 정답에 대한 정보가 부족하므, reward sparse)
- BoN : 문제를 보고 계산을 10번 생성 → 생성된 결과 중에 정답을 sampling
: Constraint
: BoN에서 몇 번 샘플링하는게 좋을지 선택⇒ 최적의 n 고르는 과정
정답 trajectory를 잘 생성하도록 하면서, 기존 policy에서 너무 멀어지지 않게 함.
💡 으로 만든 positive distribution을 따르도록 policy을 업데이트하는 loss
Learning from negative sample
= positive 확률은 높지만, negative 확률은 낮음
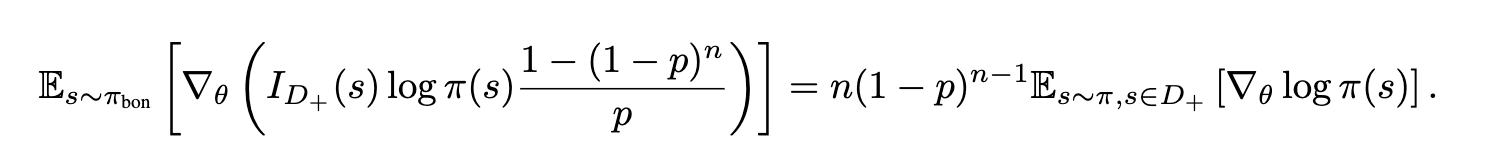
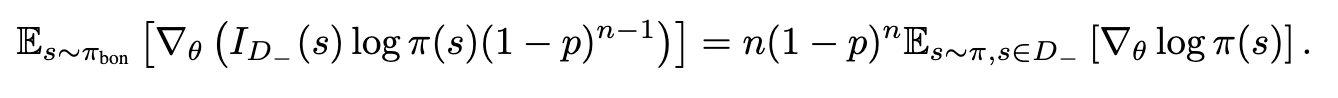
⇒ negative gradient의 지수가 한 번 더 곱해지므로, gradient 불균형이 존재.
💡 으로 만든 positive distribution에서 negative를 보정 후 policy을 업데이트하는 loss
Dealing with Long Reasoning Chains
정답은 마지막에 알 수 있지만, 중간 추론 과정도 고려해서 학습해야 한다.
⇒ token 별 중요도를 추정 (Reward를 추론 과정에 분배)
: Q(행동)을 V(상태)로 보고, t 상태에서 앞으로 받을 reward 점수
: 토큰이 하나 추가됐을 때, 결과를 얼마나 바꿨는지 측정하는 식
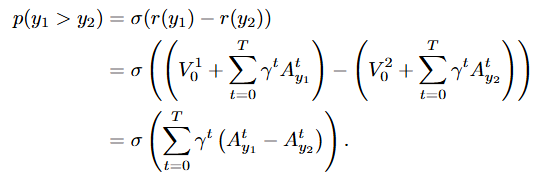
: 동일한 질문에 대해 정답과 오답이 나오면, 각 추론과정의 token별 기여도 차이를 계산함.
즉, 정답과 오답의 reward 차이는 각 trajectory별 token별 기여도 차이의 총합.
💡 reward 차이를 token별 기여도 차이의 합으로 나타냈으므로, 처음부터 trajectory 자체를 token의 합으로 표현해보자
(reward 총합의 차이 = reward별 차이 합) , (reward 총합 = reward별 총합)
- 그래서, Reward를 token 기여도 총합으로 나타낼 수 있다
: trajectory reward를 token별 기여도 합으로 표현
: 기여도 평균
:모델이 예측하는 토큰 기여도
- 최종 Loss
= (L1 Loss + L2 Loss) 와 (각 trajectory의 토큰별 가중치)를 결합한 형태임.
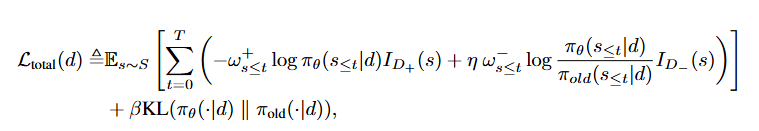
- 정답을 더 많이 생성하되, 중요한 token에 가중치를 부여
- 오답이 나올 확률을 보정하면서, 틀린 token에 강한 페널티
- KL constraint로 policy 이탈 방지
💡토큰의 중요도를 반영해서, positive trajectory는 잘 생성하고, negative trajectory는 덜 생성하도록 plicy를 학습함. (policy update)
- 그래서, Reward를 token 기여도 총합으로 나타낼 수 있다
Implementation
초기 모델(policy)로 Qwen2.5-7B, Qwen2.5-32B를 사용하여, RFT를 초기화
기존 초기 모델에 OpenDataLab Dataset, Numina, MATH Training set을 질문으로 넣고, 나온 답변을 실제 정답과 Exact Match를 통해 reward를 부여함! (정답 1, 오답 0)
그렇게 나온 (질문, reward) 쌍을 가지고, RFT를 초기화함.
Dataset : Numia, MATH, AMC/AIME
- 위 데이터들의 각 문제에 대해 RHF 모델로 64개의 배치(질문)에 대해 16개의 trajectory(풀이)를 sampling. = (1024개의 trajectory)
- 각 trajectory를 Qwen2.5-72B-instruct와 rule-based-verifier를 통해
정답(reward)를 매김 (정답인 추론은 1, 오답은 0).
- 그리고, 총 정답률이 0~0.8 사이인 문제만 사용함. (필터링)
- 필터링된 문제의 trajectory에 대해서, positive, negative pair를 선택
선택된 pair를 사용하여 token별 가중치를 학습함.
여기서, 이다.
16개의 trajectory 중 (positive, negative) pair 가중치를 보고, 공통 부분은 상쇄되고, 차이 부분을 학습.
(여러 trajectory가 합쳐지면서 토큰별 가중치가 학습됨)
⇒ 어떤 reasoning 패턴이 정답으로 이어지는지?
Hyperparameter
- Learning Rate = Policy(5e-7), reward(2e-6)
- Warmup(10 step warmup)
- Cosine Annealing
- Optimizer : AdamW
- KL coefficient : β=0.01
- 총 80스텝 training을 하고, 10 step마다 평가 진행
(1스텝마다 policy와 weight를 update)
- 더 복잡한 수학문제(삼각함수, 확률 통계, 급수) 같은 경우에는 같은 스킬의 문제를 더 수집하여 RFT 단계에서 재학습.
Experments & Result
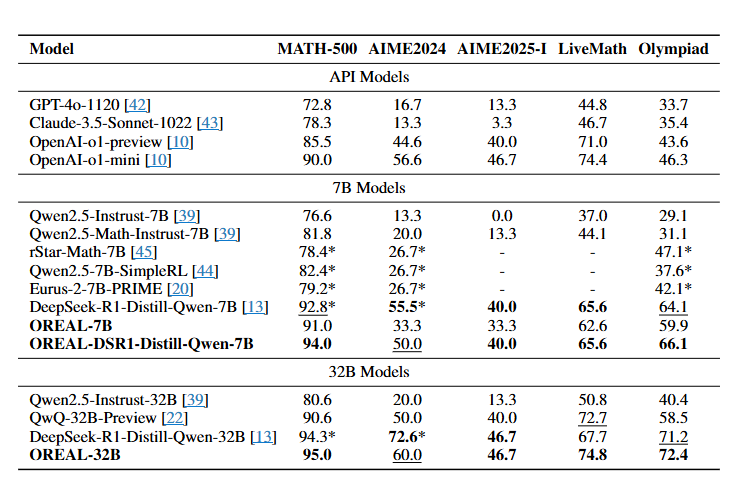
- 평가 데이터셋 : MATH-500, AIME2024, AIME2025 (Part1), LiveMathBench, OlympiadBench (수학 문제 데이터셋)
- OREAL-7B 모델이 RL 만으로 좋은 성능을 냄. (작은 모델임에도 좋은 성능. Distillation을 사용안함)
- 기존 최고 모델이었던 DeepSeek-R1-Distill-Qwen에 적용시 성능 향상
- AIME 데이터셋에서는 낮은 성능을 보이지만, 훈련 데이터의 품질 및 질문의 난이도가 원인이라고 판단
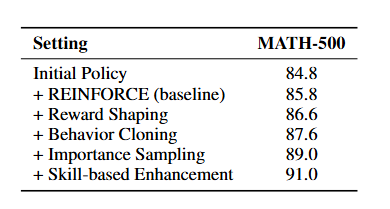
7B 모델을 기반으로 모듈을 점진적으로 추가시키면서 MATH-500에 대해 성능 평가
- Reward Shaping = L2
- Behavior Cloning = L1
- Importance Shaping = L_total
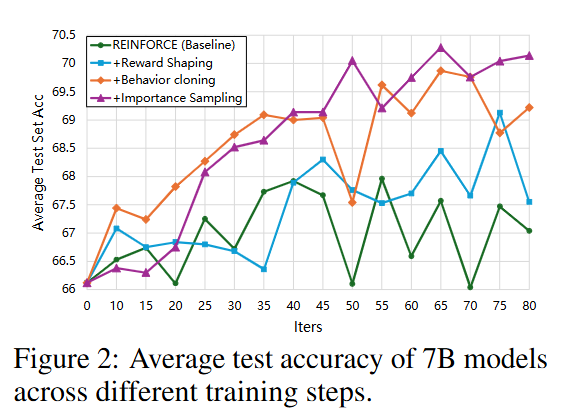
7B 모델에서 각 모듈을 추가함으로써 기존 RL Baseline 성능을 완화할 수 있음.
최종적으로는 Importance Sampling이 가장 좋은 결과를 보임을 확인할 수 있음.
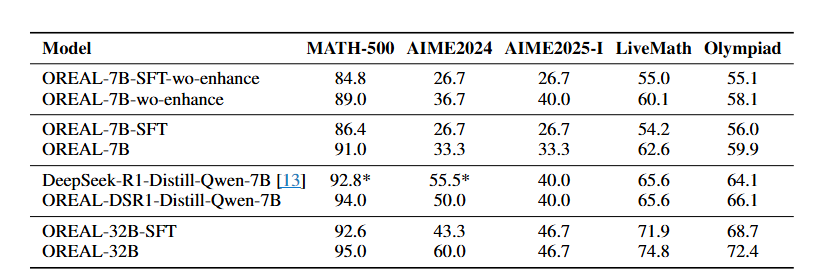
- 좋은 초기 모델(Policy)을 사용할수록 최종 성능이 높음을 확인
⇒ OREAL 프레임워크는 성능을 올리는 역할을 하는 것을 볼 수 있고, 좋은 초기 모델일수록 성능 향상이 높음.
conclusion
- OREAL 프레임워크는 BoN 샘플링, / 토큰별 기여도 학습 방식을 사용해 mathematical reasoning 에 대해 잘 할 수 있음.
- 하지만, 이 접근법들은 초기 policy model(base model)이 충분한 knowledge를 갖고 있다는 전제에 의존함.
- 따라서, policy model에 knowledge deficiency가 없어야 하고, 데이터의 균형잡힌 품질이 보장되어야 함. (난이도가 어려우면 맞추는게 어렵다)
⇒ Future work로 data construction process를 언급하며, 부족한 부분을 개선.
RL을 간접적으로 구현했다 !
= 직접적으로 RL을 쓴 건 아니지만, Reward를 추론 과정에 가중치 형태로 분배해서 간접적이라는 표현을 사용한 것.