Language Model Personalization via Reward Factorization
Review
| 닉네임 | 한줄평 | 별점 (0/5) |
|---|---|---|
| 댓츠노노 | • 장점: motivation이 명확하고 방법론과 잘 이어짐! 모호하게 느껴질 수 있는 personalization을 innovate하게 reformulate함! • 단점 & 보완점: - | 5 |
| 아이리스 | 장점: 내 머릿속 들어왔다 나갔나 싶다.. 사람은 결국 조금 다른게 크게 드러난다고 생각함. 상식이라는 선이 있으므로, 그 직관을 잘 구현한듯. 단점: 다른 논문에서 썼지만, 사실 개인적으로는 사용자 맞춤은 절대 불가능이라고 생각함. 모든 사용자 개인화는 소거법이라고 생각함. 그런 방식은 아니어서 아쉽지만, 내가하면 되지 않을까? 보완점: 축마다 주는 가중치가 부정 기반이었으면 어떨까? | 4.7 |
| 핸드크림 | • 장점: 새로운 사용자에 대해 빠르게 정렬할 수 있는 방법 • 단점: 초기 행렬 구성에서 많이 벗어나는 사용자는 reward function 설정이 잘 안될 수도 있어보임 • 보완점: base reward function을 유지하되 outlier 사용자를 커버할 방법 | 4.5 |
| 3월 | • 장점: Inference 시 모델 재학습 없이 사용자별 reward weight만 추정해서 비용 효율성 증대 • 단점 및 보완점: 이전 논문들도 그렇고 사용자 선호가 선형 결합으로 표현된다는걸 가정하는데... 예를 들어 사람이 업무 관련해서는 짧고 정확하게, 잡담 관점에서는 길고 친근 한걸 선호하는데 이걸 linear로 반영할 수 있나..? 더 나은 non-linear 방법이 없나? | 4.5 |
| 에너지 | • 장점 : RLHF PPO방식에서 reward를 단순 neural network로 통합해서 preference를 최적화했는데, 사실 preference를 더 자세하게 따져야하는 건 당연한 것이었던 것 같다. reward를 단순 설계하다보니 비유일성 문제가 발생한 것 같고, 해당 논문과 마찬가지로 DPO 등장했던 것에 reward의 한계가 큰 영향을 미친 것 같다. (reward 압축,통합 표현이 문제!) • 약점 : 사실 reward를 표현하는 축에 대해 선호도 축을 충분히 표현 못하지 않을까? 싶었는데 실험 결과에서 증명이 되었다.. | 4.9 |
| 피즈치자 | • 장점: 사용자마다 personalized된 선호를 다 반영한 모델을 만들 수 없으니, 이를 고려한 문제 접근이 현실적임 • 단점: 사용자의 선호를 선형으로 가정했는데(물론 실험에더 어느정도 증명한것 같지만), 비선형으로 나타나는 경우가 정말 없을까? • 제안: personalization 속성들이 길이, 유머, 정중함, confidence 같은 비교적으로 해석 가능한 스타일인데, 더 미묘한 스타일을 어떻게 반영할 수 있을까(e.g., reasoning 스타일 등등..) | 4.5 |
| 화이트노이즈 | • 장점: 그래도 사용자들끼리 공통된 몇 개의 선호 축이 존재한다고 가정한 지점이 지금까지 본 personalization 논문 중에서 가장 motivated 된 논문 (적당히 → 더 좋은 적당히) • 단점: 사람 취향이라는게 정말 복잡한데 선형 관계로 간단히 표현하는게 맞을까? • 보완점: 문화적으로 상반된 유저들(e.g., 고맥락사회 vs 저맥락 사회)이 같은 축 공간 안에 공존할 수 있는지가 의문 • 제안: 사실 해당 논문의 공통 선호축의 각 파라미터가 어떠한 peference를 나타내는지 해석 불가하다는 한계가 있는데 What’s In My Human Feedback? Learning Interpretable Descriptions of Preference Data (ICLR'26 Oral) 논문에서 제시한 방법으로 데이터셋에서 선호 축을 미리 추출하고 해당 축을 바탕으로 공통 선호축 파라미터를 설정하면 어떨까? | 4.5 |
| 제로콜라 | • 장점: 사람마다 선호가 완전히 제각각이 아니라 공통된 몇 개의 축으로 표현될 수 있다는 가정이 직관적이고 좋음 • 약점: 사용자의 선호가 여러 축의 선형 결합으로 표현된다고 가정하는데, 같은 사람이 상황에 따라 선호가 달라지는 경우를 선형 모델로 잡아낼 수 있을지 의문이 생김. • 보완점: 현재 실험에서 사용된 선호 축은 비교적 해석하기 쉬운 스타일 속성인데, 문화적 배경이나 가치관처럼 더 복잡한 개인 선호까지 같은 방식으로 포착할 수 있는지 다양한 사용자 집단을 대상으로 추가 실험이 있으면 좋을 것 같음. | 4.5 |
| 창백카츄 | 장점: 개인화를 하기에 아주 좋은 방법론이라 생각하고, 문화적, 지리적 bias를 쉽게 반영할 수 있어 보임! 약점: 저자들이 합성한 데이터의 reliablity가 조금 의심됨. Prefer axis가 독립적인지도 잘 모르겠음. 이것에 대한 실험이 있나? 제안점: 실제 human study나 case study를 보여주면 더 좋을듯 | 3.5 |
TL; DR
💡
여러 사용자의 선호를 공통된 선호 축(e.g., 친절, 간결, 격식)으로 분해해 학습한 뒤, 새로운 사용자가 들어오면 축마다 다른 가중치를 주어 사용자의 personalized된 선호를 빠르게 추정하자!

- Cited: 19
Introduction
Motivation
- 기존 RLHF의 한계
- Universal Preference Model: 각 사용자 별 선호가 아닌 모든 사용자에게 보편적으로 align된 모델
⇒ ⭐ 평균적인 인간 선호에는 align될 수 있지만, 각 사용자 별 선호를 반영하는 personalization은 한계
RQ 사용자 별 선호라는게 완전 제각각이 아니라, 공통된 몇 개의 선호 축(low-dimensional preference space) 위에서 표현될 수 있지 않을까?
Contribution
- Personalization via Reward Factorization (PReF) 프레임워크 제안: Personalization을 reward factorization 문제로 재정의
- 사용자마다 reward model을 따로 학습하지 않고, 공통 base reward functions를 먼저 학습한 뒤 새로운 사용자에 대해서는 축별 가중치만 추정
- base reward를 한 번 학습해두면 새 사용자는 전체 모델 재학습 없이 사용자별 가중치 벡터만 추정하면 됨
- Active learning 기반 적응 도입: 가장 불확실성을 많이 줄여줄 질문/응답쌍을 선택해 데이터 효율을 높임
Methods
Step 1. 공통 선호 축 학습(Offline)
- 여러 사용자들의 preference 데이터를 모아 응답을 몇 개의 공통 base reward functions로 표현할 수 있도록 학습
- 수백 명의 유저에게 응답 쌍 을 보여주고 선호 데이터를 수집 ⇒ 유저 x 응답쌍 행렬 구축
Sparse Preference Matrix 응답쌍1 응답쌍2 응답쌍3 응답쌍4 응답쌍5 유저A 응답 선택 응답 선택 유저B 응답 선택 응답 선택 유저C 응답 선택 유저D 응답 선택
- 수백 명의 유저에게 응답 쌍 을 보여주고 선호 데이터를 수집 ⇒ 유저 x 응답쌍 행렬 구축
- 이 데이터를 바탕으로, 응답을 몇 개의 공통 base reward functions로 표현하도록 모델을 학습
- 하나의 응답은 여러 공통 선호축 위에서 점수를 받고, 각 사용자는 축들에 서로 다른 가중치를 줌
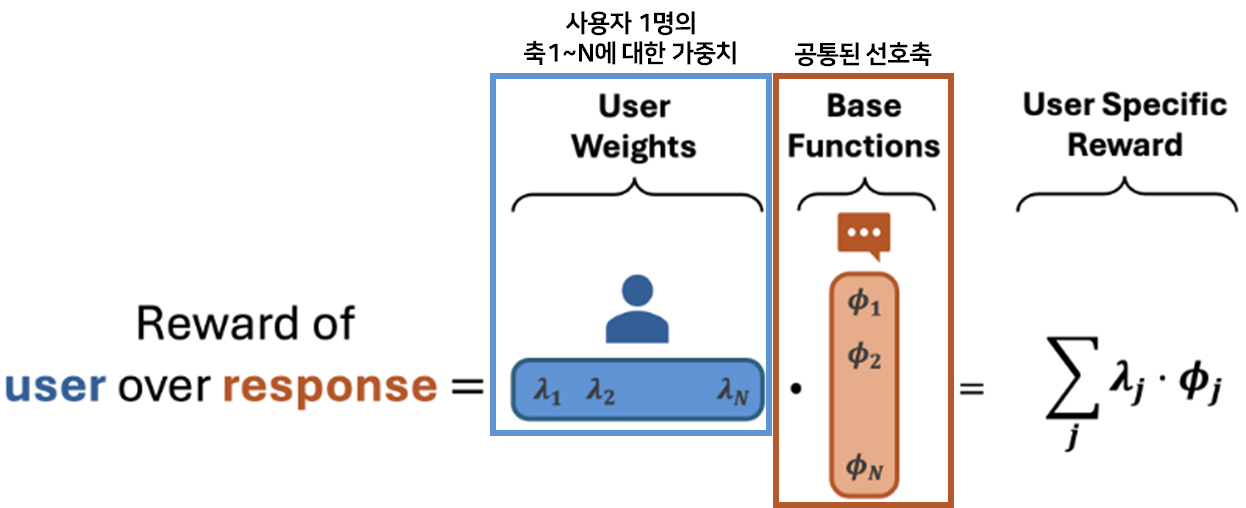
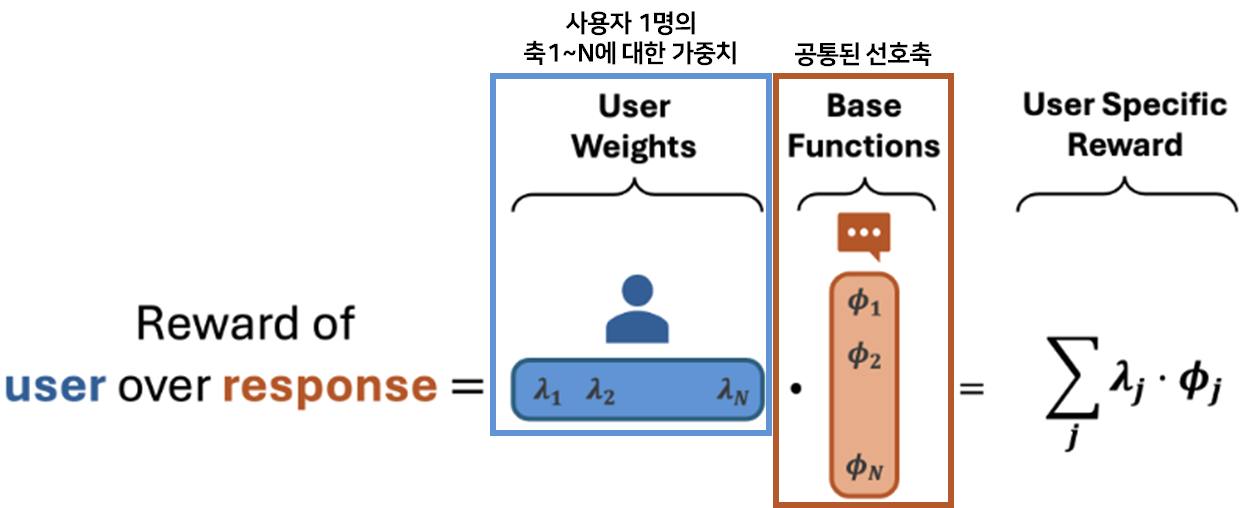
- 행렬 분해(Matrix Factorization)
- 행렬 (User Factor): 사용자들이 각 선호 축에 대해 가지는 가중치 ()
- 행렬 (Item Factor): 각 응답 쌍이 어떤 선호 축의 특징을 가졌는지에 대한 점수 ()
- 사용자 의 보상 함수 ( dot product)
- : 공통된 선호축(모든 유저 공유) e.g., : 간결함, : 격식, : 친절함, : 창의성
- : 유저 의 고유 가중치
- 프롬프트와 응답을 입력받아 차원 벡터 를 출력하는 신경망을 학습
- SVD 초기화, L2 정규화 사용
⇒ 사용자마다 완전히 별도 모델을 만들지 않고, 모든 사용자에게 공통으로 쓸 수 있는 reward 모델
Step 2. 새 사용자의 선호 벡터 추정(Online)
- 새로운 사용자에게 몇 개의 비교 질문을 통해 사용자가 공통 축들을 어떤 비율로 좋아하는지 추정
- 현재 λ 추정이 가장 불확실한 축에 해당하는 응답쌍을 능동적으로 선택(Active Learning) 해 데이터 효율을 극대화
Active Learning사용자에게 아무 질문이나 묻지 않고 사용자의 취향을 가장 빨리 알아낼 수 있는 질문을 골라서 묻는 것
- e.g., 답변 A와 B 중 어느 쪽이 더 좋은가?
- 현재 λ 추정이 가장 불확실한 축에 해당하는 응답쌍을 능동적으로 선택(Active Learning) 해 데이터 효율을 극대화
⇒ 새 사용자에 대해 는 고정한 채, logistic regression으로 사용자의 weight vector만 맞추면 됨
Step 3. Personalized 응답 생성
- LLM을 새로 학습하지 않고, Personalized Reward로 응답 선택
- 학습된 공통 축 와 새 사용자의 가중치 를 결합해 personalized reward를 계산
- 추론 시, 이 보상 값을 가지고 응답 선택
Experiments
setup
- model: qwen 2.5 계열
dataset
- Attributes
- 저자들이 만든 synthetic personalization 데이터셋
- 7개의 preference attribute 정의하고, 각 attribute마다 positive/negative trait를 둠
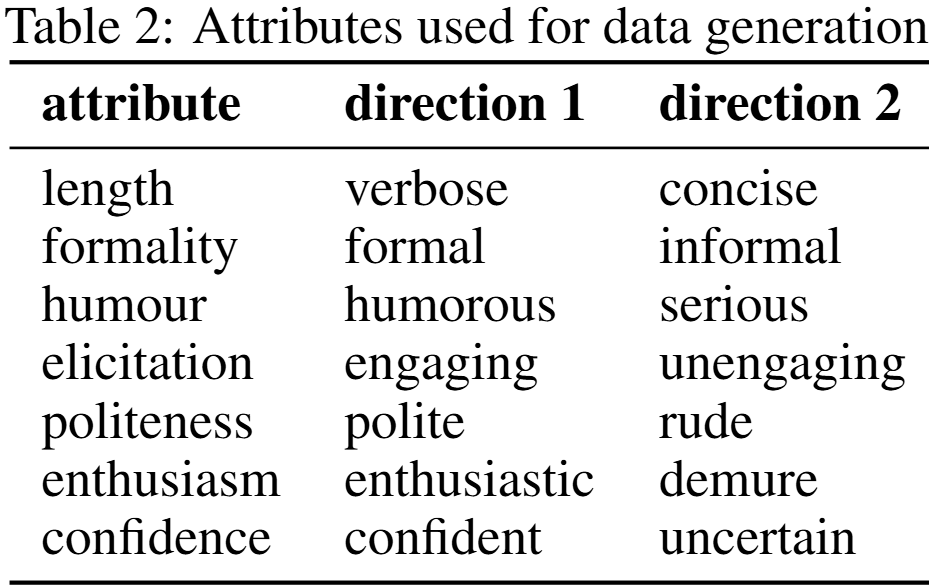
- 사용자마다 두 개의 trait를 랜덤하게 부여해 84명의 synthetic user 만듦
- AlpacaEval 프롬프트 기반으로 사용자당 100개의 preference를 수집
- PRISM
- 전 세계 다양한 응답자들의 LLM 선호 데이터를 담은 데이터셋
- 1.5K users, 3K prompts and answers
- Attributes
metrics
- User Preference AUC-ROC: 응답쌍 중 어느 것을 사용자가 선호할지 맞히는가
- Win rate: 개인화 reward를 이용해 생성한 응답이 비개인화 baseline보다 얼마나 더 선호되는가
Baseline
- Standard RLHF: 모든 사용자를 하나의 전역 reward로 학습
- Model per User: 사용자마다 개별 reward model 학습
Baseline 대비 성능 평가
목표새로운 사용자에게서 피드백을 받았을 때, 누가 가장 사용자의 선호를 빠르게 학습하는지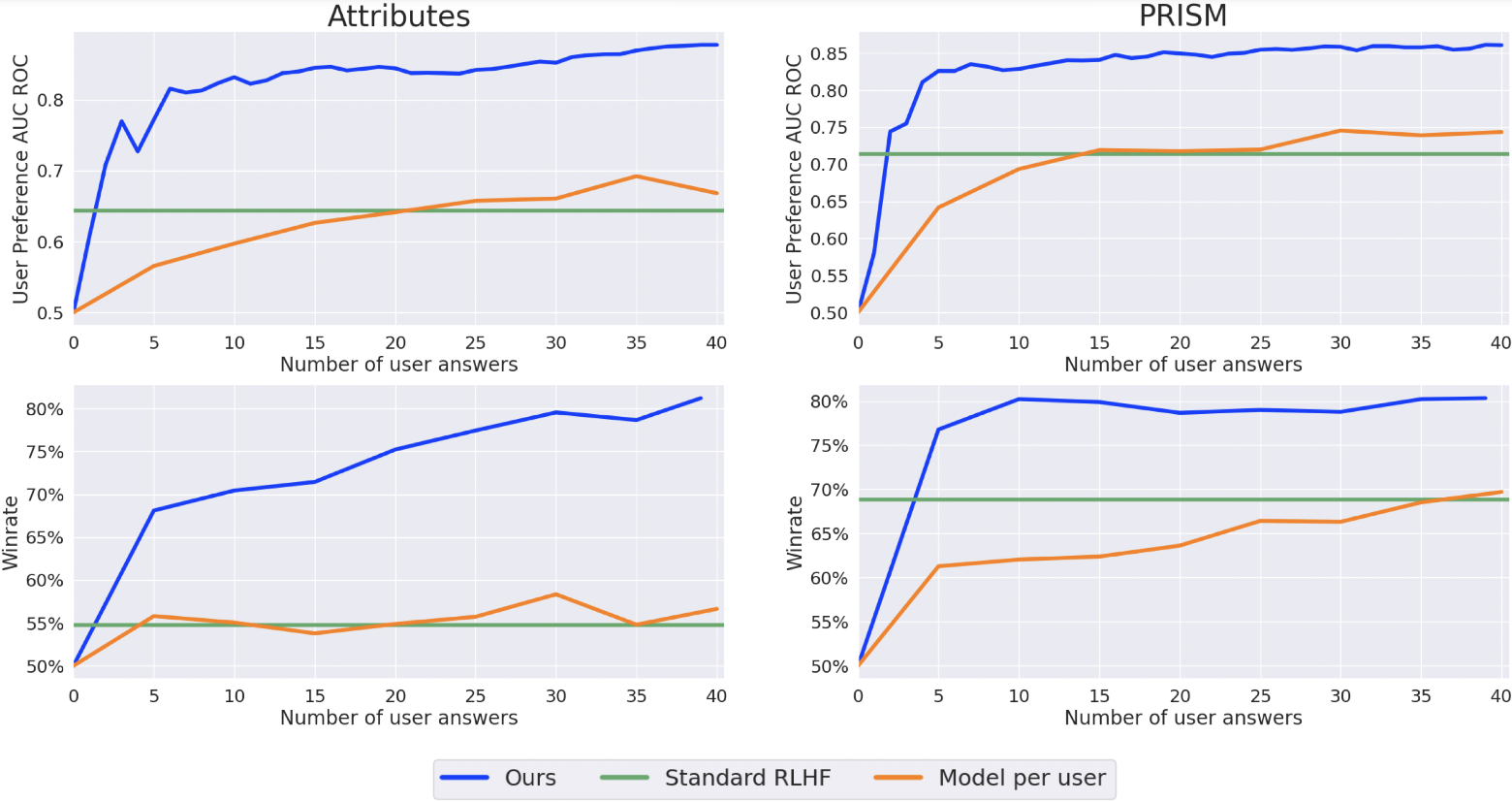
- 실험결과
- Standard RLHF
- 개인화 모델이 아니므로 성능 변화 X
- Model per user
- 사용자 별 데이터가 적기 때문에 많은 응답이 쌓여야 성능이 오르기 시작함
- PReF(Ours)
- 적은 수의 사용자 응답만으로도 personalization 성능을 빠르게 올림
- x축: 새 사용자에게서 받은 선호 응답 수
- y축
- User Preference AUC-ROC: 응답쌍 중 어느 것을 사용자가 선호할지 맞히는가
- Win rate: 개인화 reward를 이용해 생성한 응답이 비개인화 baseline보다 얼마나 더 선호되는가
- Standard RLHF
기존 Personalization Methods 와 비교

- VPL: few-shot에서는 강하지만, in-context 방식이라 사용자 예시가 많아지면 성능
- PReF: 사용자 피드백이 10개 이상 넘어가면 SOTA
Ablation Study
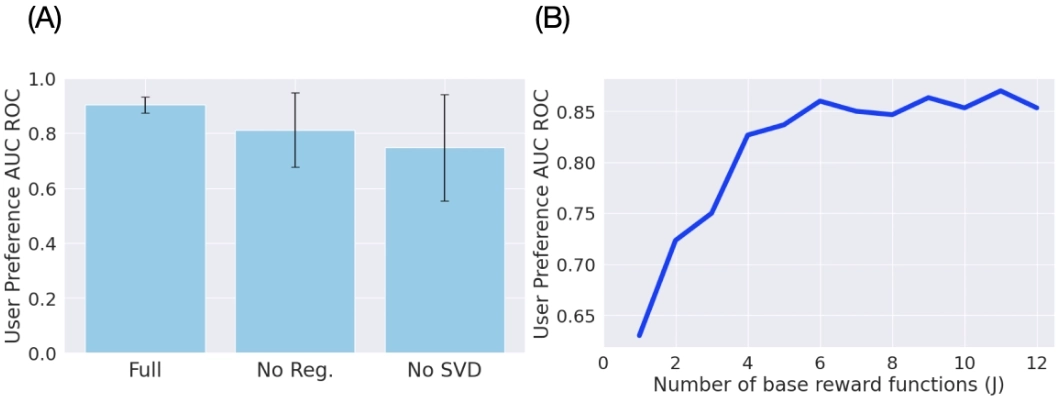
(A) SVD 초기화와 regularization이 진짜 필요한가?
- Full: 전체 방법 사용
- No Reg.: w/o regularization
- No SVD: w/o SVD initialization
⇒ 정규화 SVD 초기화 없이는 성능 저하와 불안정해짐
(B) base reward function 개수 는 몇 개가 적절한가?
- x축: 공통 선호 축 개수
- 실험 결과
- 가 1~3일 때는 성능이 빠르게 오르지만 4~6까지는 성능이 그다지 오르지 않음
→ 선호 축을 많이 늘린다고 성능이 계속 오르지는 않는다
⇒ ⭐ 사람의 공통된 선호가 실제로 저차원 구조를 갖는구나!
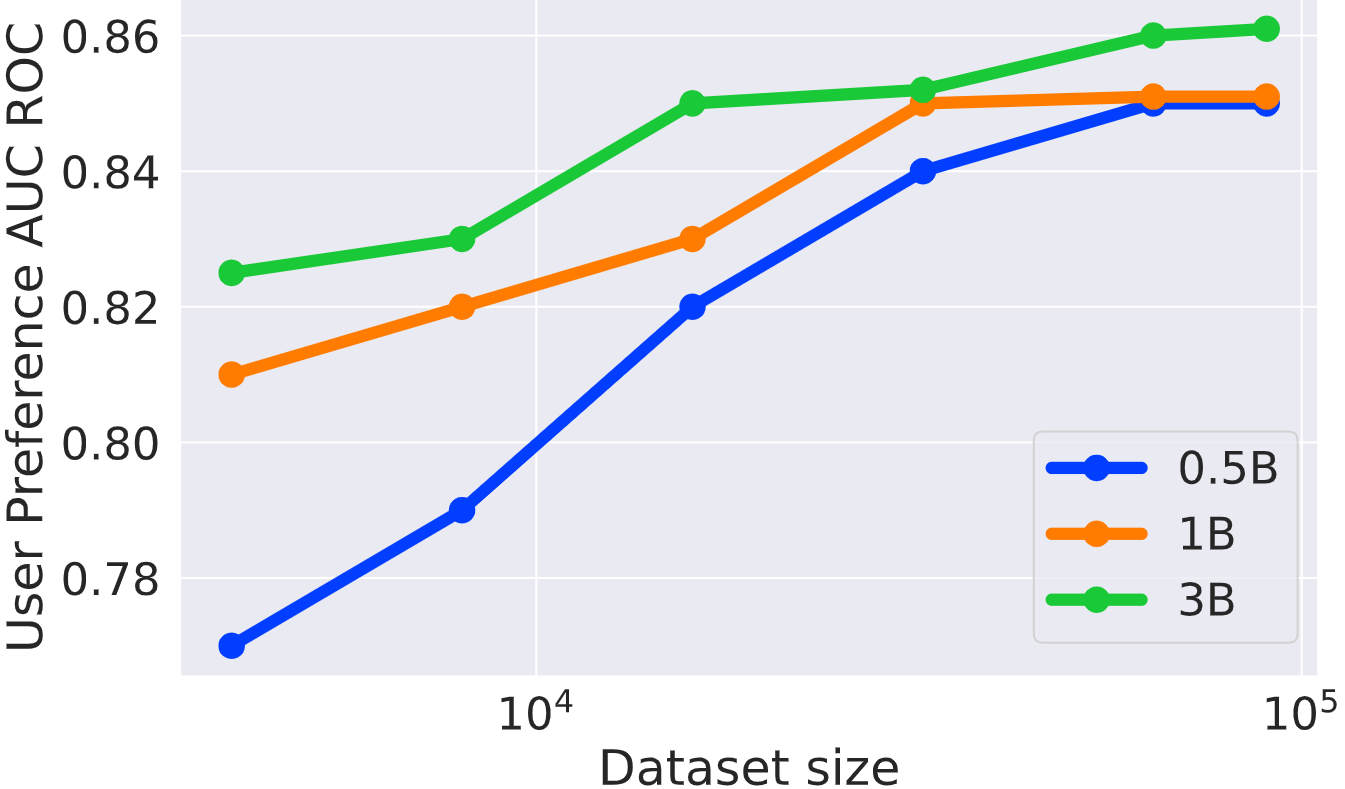
데이터셋 크기에 따른 성능 비교
목표 데이터셋 크기과 base reward model ↔ 사용자 선호 예측 성능 사이의 연관성
- 데이터셋 = PRISM 기반 학습 데이터
- 실험 결과
- 데이터셋이 커질수록 모든 모델의 성능 향상
- 같은 데이터 크기에서의 성능: 3B > 1B > 0.5B
- 데이터가 충분히 많아질수록 모델 간 성능 차이 줄어듦
⇒ 더 큰 reward model과 더 많은 데이터는 personalization 성능을 향상시킴
human eval
- MIT/Harvard 계열의 28명 자원자를 대상으로, 앞 15개 비교에서 취향을 학습하고 뒤 15개에서 평가
- personalized response가 기본 GPT-4o 응답보다 67% win rate를 보임