TROLL: Trust Regions Improve Reinforcement Learning for Large Language Models
Review
| 닉네임 | 한줄평 | 별점 (0/5) |
|---|---|---|
| 댓츠노노 | • 장점: trust region을 정의하고, 그 안에서 효율적으로 optimization수행. 기존 clipping보다 뛰어난 성능을 보임 • 단점: 두 motivation 간 연계성이 부족함. Sparse projection이랑 PPO clipping이랑 뭔 상관인지??? • 보완점: token distribution의 efficiency 강조 실험 | 2.8 |
| 아이리스 | • 장점: 점진적, 유동적 학습이라는 아이디어를 직관적으로 잘 풀어내고, 기존 방법의 한계를 지적하고 잘 풀어냄. 성능적으로 우수함. • 단점:method가 무엇을 해결하는것인지 모호하게 느껴짐. Projection을 일부만 한다는 것도 이해가 조금 어려움. 논문의 기여점이 무엇인지 잘 모르겠음. • 보완점: 학습이 크게 되어도 오히려 최적점에 더 가까워질 수 있지 않나? 동적으로 고려해야 하지 않나? 라는 생각 | 3.5 |
| 핸드크림 | • 장점: 정책 업데이트가 trust region 내에서 일어나는 것은 보장하되 임의의 clipping 기준값을 사용하지 않음. 학습이 안정적인 범위에서 최대한의 효과로 일어나게끔 함 • 단점: policy clipping이 더 효과 좋은 경우는 없을까? reasoning 도메인이 아니라면? • 보완점: 타 도메인 벤치마크 실험 | 4.3 |
| 에너지 | • 장점 : PPO의 reward문제 및 policy update와 관련해서, KL Constraint 부분도 개선가능하다는 것을 보고, 항상 완벽한 알고리즘은 없다는 것을 다시 한번 느낄 수 있었음. 특히 policy의 update 크기뿐만 아니라 방향까지 고려하는 연구임. • 약점 : Top-k를 고려하는게 최선의 선택으로 보이긴 하지만, long tail 토큰을 놓치는것은 어쩔 수 없어 보임. • 보완점 : trade-off는 피할 수 없겠지만, 토큰의 다양성을 챙길 수 있는 여러 방법에 대한 실험이 있으면 좋을 것 같음. | 3.8 |
| 3월 | • 장점: Heuristic에 기반하여 국소적인 관점을 파악하기 어려운 기존 clipping과 달리, 각 토큰마다 constraint를 적용해서 특정 토큰만 과하게 바뀌는 문제를 방지함 • 약점: 학습 안정성에 기여하는 직접적인 원인인 projection, sparsification에 대한 ablation 실험이 부재함. • 보완점: 안정성 때문에 실질적으로 policy가 얼마나 왜곡됐는지 tradeoff를 보여주는 실험을 추가하면 좋을듯 | 3.6 |
| 화이트노이즈 | • 장점: clipping 만 대체하면 된다는 점에서 플러그인 호환성이 좋음 • 단점: PPO논문은 실제로 다양한 도메인에 대한 실험이 있는 바에 비해 해당 논문은 수학쪽 밖에 없음 • 보완점: 수학 이외의 도메인에서도 성능이 어떨지 궁금함 | 3.0 |
| 피즈치자 | • 장점: 기존 CLIP이 근사적인 방법이라는 것을 잘 짚고 이를 명시적으로 직접 개선하고자 하는 시도는 좋은듯 • 단점: token-level 단위로 안정적으로 만들고자 하는데, 이 token 별 낮은 KL이 sequence-level에 대해서 안정성을 보장할지는 의문임 • 보완점: 장문 generation에서의 실험이나 global적인 측면을 추가하면 좋겠음 | 3.9 |
| 제로콜라 | • 장점: PPO clipping은 값 하나로 모든 토큰을 똑같이 제한하는데, TROLL은 토큰마다 개별적으로 얼마나 바뀌었는지 보고 제어한다는 점이 합리적으로 느껴짐. • 단점: Trust region 안으로 projection할 때 기하 평균을 쓰는 게 최적해라고 하는데, 이게 왜 최적인지 충분히 설명되지 않는것 같음. • 보완점: 수학처럼 정답이 명확한 태스크가 아니라, reward 자체가 모호한 도메인에서도 TROLL이 잘 작동하는지 실험이 있으면 더 설득력이 있을 것 같음. | 3.5 |
| 오차 | • 장점: 단순 Clipping은 값을 제한하여 정보를 충분히 반영하지 못한다는 단점이 있는데 이 방법은 Trust Region으로 Project을 함으로써 Gradient문제를 해결한 점이 이 연구의 강점으로 보임. • 단점: Sparse Projection 방식인데 이러면 계산 비용이 낮아지지만 최적인 상태가 유지되는지 의문임. 여기에 대한 실험이나 증명이 부족함. • 보완점: TROLL이 PPO Cliping보다 LLM에서의 성능이 높아진다는 실험 결과만 제시하지 말고, 다양한 Task에 대해서 실험을 진행하는 일반성이 추가되었으면 함. | 3.6 |
| 창백카츄 | 장점: 기존 논문들이 그냥 PPO 갖다쓰는데 반해, 이게 optimal한지 검토하고 optimal한 point를 제시하는 것은 아주 기여가 큼! 이제 강화학습 쓰는 논문들은 PPO 대신 TROLL을 써야 할지도.. 약점: policy gradient가 클 때 항상 안좋은 것인지에 대한 검증이 미흡한 것 같음, 이미 선행연구가 있나? 제안점: Case study를 보여주면 더 와닿을 것 같음! | 4 |
TL; DR
💡
LLM을 RL로 학습할 때 모델이 한 번에 너무 크게 바뀌면 망가지므로, 허용된 범위 안에서만 업데이트해서 안전하게 학습시키자
Summary
- 연구진: 카를스루에 공과대학, 마이크로소프트
- 인용수 : 2
Preliminary
Trust Region method란?
“한 번에 너무 멀리 가지 말고, 안전한 범위 안에서만 업데이트하자”
- 일반적인 gradient update 수식
-
⇒ Gradient가 크면 변화량이 너무 커져 성능 안정성이 악화됨
⇒ RL에서는 reward variance가 크고 policy가 조금만 바뀌어도 결과가 크게 변하기에 치명적
-
- 그러면 어떻게 정의하나? ⇒ KL Divergence로 정의
-
- 새로운 policy와 기존 policy가 너무 달라지지 않도록 제한을 둠
⇒ 최적화 목표: reward 최대화하면서 policy 변화는 작게!
-
- 일반적인 gradient update 수식
PPO (Proximal Policy Optimization)이란?
“KL constraint 계산이 너무 오래 걸리니 clipping을 활용하여 근사하자!”
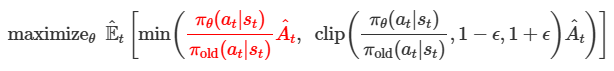
- 새로운 policy가 특정 action을 얼마나 더/덜 선호하는 지 비율 정의
-
- 그러나 여전히 비율이 너무 커지거나 작아질 수 있음 → Clipping을 하자
- 비율이 정상 범위 이내인 경우 → → 좋은 action이므로 그대로 사용
- 비율이 너무 커지는 경우 → → Clip해서 과도한 업데이트 방지
- 비율이 너무 작아지는 경우 → → Clip해서 과도한 업데이트 방지
- 새로운 policy가 특정 action을 얼마나 더/덜 선호하는 지 비율 정의
연구 동기
LLM의 post-training 단계에서
- RLHF / RLVR 등 강화학습 기반 fine-tuning이 표준 방법이 됨
- 대부분의 방법은 PPO 기반 policy gradient 알고리즘을 사용
- 모델이 생성한 토큰에 대해 advantage 계산
- 기존 policy와 새로운 policy의 비율 계산을 통해 policy gradient 업데이트
- 업데이트 폭이 너무 커지지 않도록 clipping 적용
⇒ policy 변화가 너무 커지는 것을 막아 훈련 안정성 확보
이 논문은 다음 질문에서 출발함
“LLM 강화학습에서 PPO clipping이 아닌 더 principled한 trust region 방식이 필요하지 않을까?”
기존 PPO clipping 메커니즘의 한계
- Clipping은 이론적으로 정확한 trust region이 아닌, 단순히 비율을 자르는 heuristic 방식임
- Clipping 범위를 벗어나면 gradient가 사라지는 문제 발생 → 느린 수렴
- 하이퍼파라미터에 민감하여 낮은 reproducibility를 보임
- Continuous action 중심이라 discrete 토큰 분포를 가지는 LLM에 바로 적용이 어려움
제안 아이디어
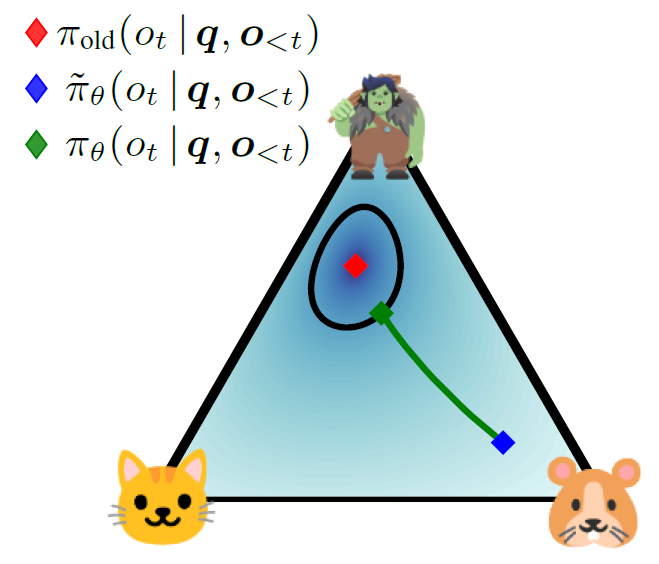
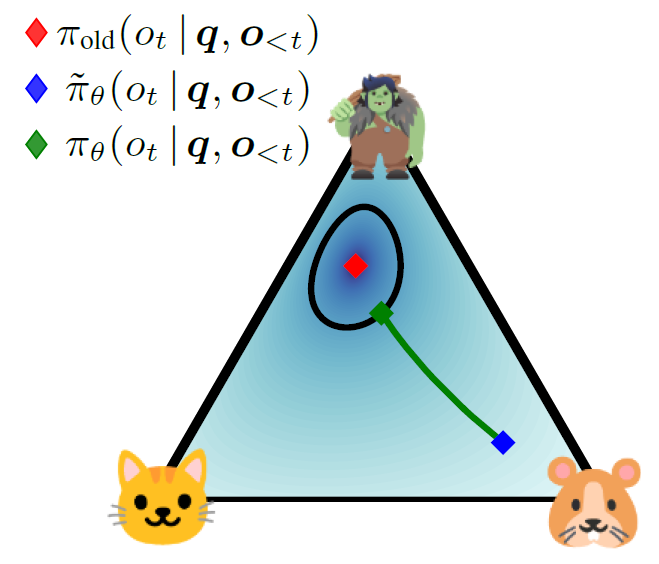
그림 설명
- 3 토큰 분포 (고양이 / 트롤 / 햄스터) 를 나타냄
- 기존 policy는 트롤 토큰을 선호하고, 새로운 policy는 햄스터쪽으로 이동
- 근데 너무 멀리 이동시키면 안되니까 trust region 안으로 projection해서 끌어오자!
- 근사 방식인 clipping이 아닌, 정확한 trust region을 활용하여 projection하자!
- 새로운 policy와 최대한 가깜게 유지하면서 old policy와 KL 거리 제한
- Token-level KL constraint
- LLM은 시퀀스이기 때문에 각 토큰 분포에 대해 trust region 적용
- Sparse projection (LLM scaling 문제 해결)
- 확률 높은 토큰만 유지하여 projection 계산 비용을 낮춤
Methods
Trust Region Projection
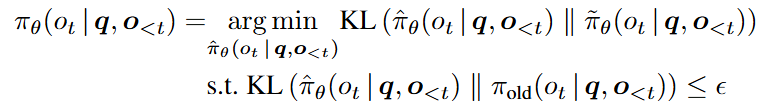
- 새로운 모델이 만든 policy 와 최대한 가깝되, 기존 policy 와 너무 멀어지지 않는 분포를 찾아라!
⇒ 그럼 최적해는 무엇이야?
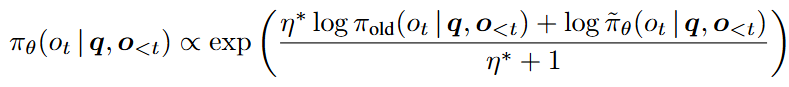
- 기존 policy와 새로운 policy의 기하 평균
- KL constraint가 붙은 최적화 문제를 풀면 log-space에서 linearization → 이후 exponential 취하면 기하 평균이 됨
- 기존 policy와 새로운 policy의 기하 평균
- 한편, projection은 일부 토큰에만 필요하다!
- 대부분 토큰은 이미 KL constraint를 만족해서 그대로 사용하고, 일부 토큰만 projection 필요
- 새로운 모델이 만든 policy 와 최대한 가깝되, 기존 policy 와 너무 멀어지지 않는 분포를 찾아라!
Sparse & Efficient Representations of Token Distributions
- Qwen3의 vocab size는 151936
- 토큰 하나당 15만개의 확률을 계산해야 함 → 너무 비싸서 현실적으로 불가능
⇒ 분포를 sparse하게 만들어서 중요한 토큰만 남기자!
⇒ 메모리 OOM 방지 및 계산 효율성 증가How?
- 확률 기준 top-K 토큰 선택
- 확률을 누적합해서 특정 threshold (e.g., 99.9%)까지 채우는 토큰만 유지
- 모델이 실제로 선택한 토큰은 포함시켜 gradient 계산에 활용
- 확률 기준 top-K 토큰 선택
- Qwen3의 vocab size는 151936
Experiments
실험 목적
- PPO clipping을 TROLL로 교체하면 성능이 좋아지는가?
- 다양한 모델과 RL 알고리즘에서도 효과가 유지되는가?
- 수학 reasoning / 코드 생성 같은 실제 RLVR task에서도 효과가 있는가?
데이터셋
- DAPO-Math : 수학 추론 능력을 RL로 학습하는데 사용됨
- Math-Eval: 여러 수학 벤치마크 통합본, 올림피아드 수준 문제
- GSM8K: 초등학교 수준 문제
- Eurus-2-RL: 수학 추론 & 코드 생성 문제 포함
활용 LLM
- Qwen3-{0.6B~14B}
- Qwen2.5-{0.5B~7B}
- Llama3.1-8B, Llama3.2-3B, Apertus-8B, Smol-LM3-3B
실험 결과 1: Qwen 활용한 실험 성능
“Qwen3 모델을 GRPO로 학습 시, PPO clipping 대신 TROLL을 사용하면 어떤 변화가 생기는지?”
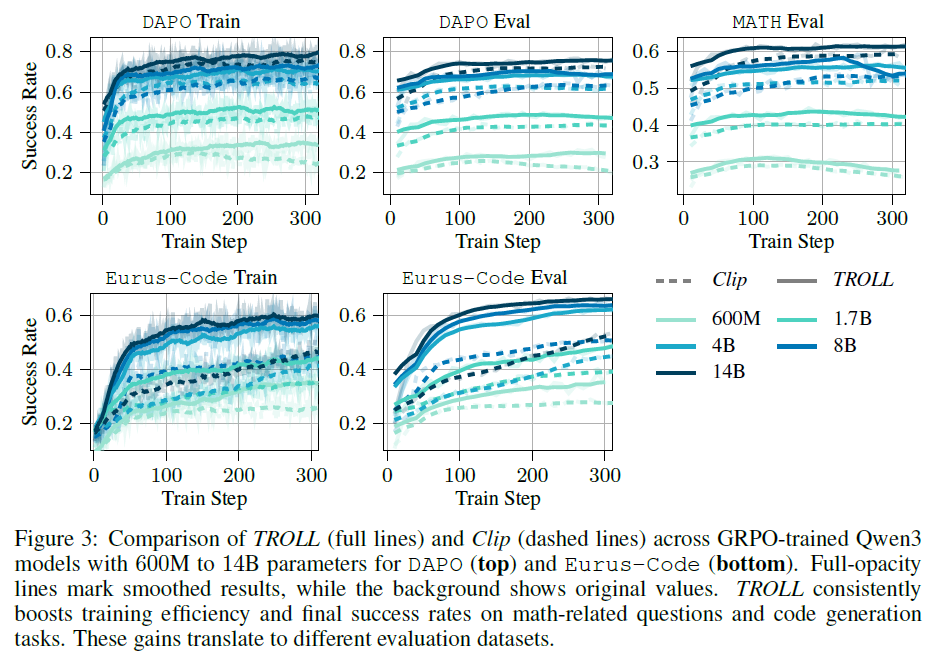
- 모든 모델에서 TROLL이 더 빠르게 학습 ⇒ 학습 효율성이 더 좋다!
- 최종 성능이 더 높으며, 작은 모델에서도 큰 개선이 이뤄짐
- 코드 생성 데이터에 대해서도 동일한 패턴을 보임
“TROLL이 다양한 RL 알고리즘 활용 시 PPO clipping보다 실제로 성능을 개선하는지?”
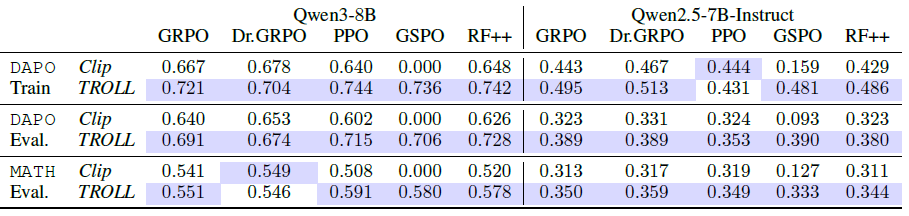
- TROLL이 학습 안정성을 크게 개선
- PPO clipping 자체가 RL 최적화를 제한시키고 있을 가능성 시사
실험 결과 2: 다른 LLM에도 동일한 효과가 나타나는 지 검증
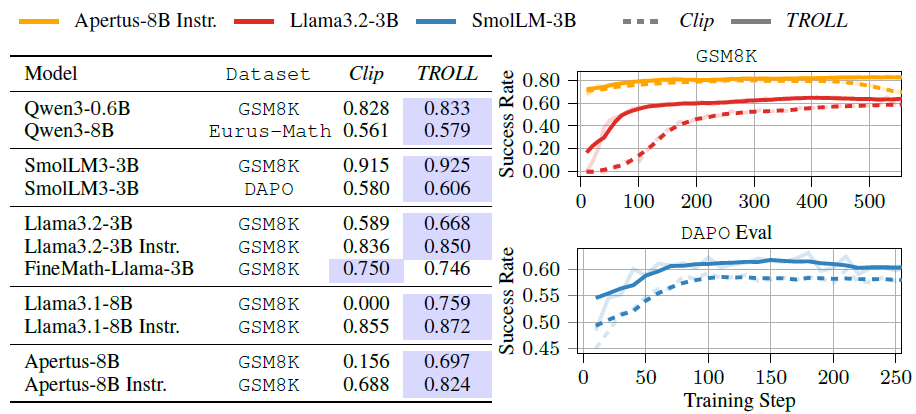
- 대부분 LLM에 대해 TROLL이 더 높은 성능을 보임
- Clip에서 학습이 실패하는 경우 존재 (e.g., Llama3.1-8B)
- TROLL은 학습을 훨씬 빨리 시작하며, 학습 안정성도 개선함
실험 결과 3: 하이퍼파라미터 분석
- KL bound (Trust region 크기) & Sparsification 토큰 수 조정 실험
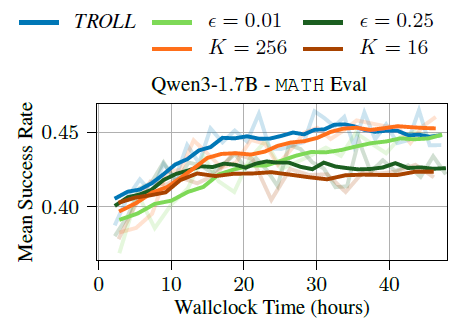
- KL bound가 작은 경우 policy 변화가 매우 제한되어 학습 속도 감소 but 최종 성능은 동일
- KL bound가 큰 경우 성능 감소 및 학습 품질 악화
- Sparsification 토큰 수가 작은 경우 실제 분포 approximation 악화 ⇒ policy 업데이트 품질 악화
- Sparsification 토큰 수가 너무 큰 경우 연산 비용은 증가하지만 성능 개선은 그닥
- KL bound (Trust region 크기) & Sparsification 토큰 수 조정 실험
실험 결과 4: Entropy 관점 해석
- 기존 문제: PPO-like clipping은 엔트로피를 줄이는 방향으로 학습됨 (과도한 업데이트 방지)
→ 분포가 특정 방향으로 쏠리는 현상 발생
→ 새로운 reasoning 전략에 대한 학습이 어려워짐
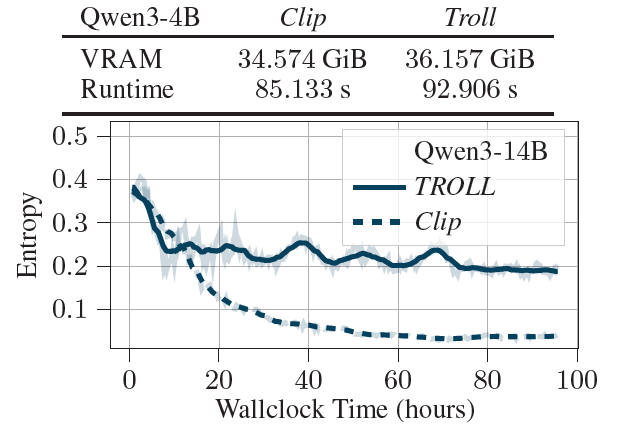
- TROLL은 계속 높은 엔트로피를 유지한다!
- KL constraint 안에서 projection을 수행하여 이전 policy와의 거리를 유지→ gradient가 계속 유지됨
- 기존 문제: PPO-like clipping은 엔트로피를 줄이는 방향으로 학습됨 (과도한 업데이트 방지)