26 March 2026
TROLL: Trust Regions Improve Reinforcement Learning for Large Language Models
ICLR'26 Oral
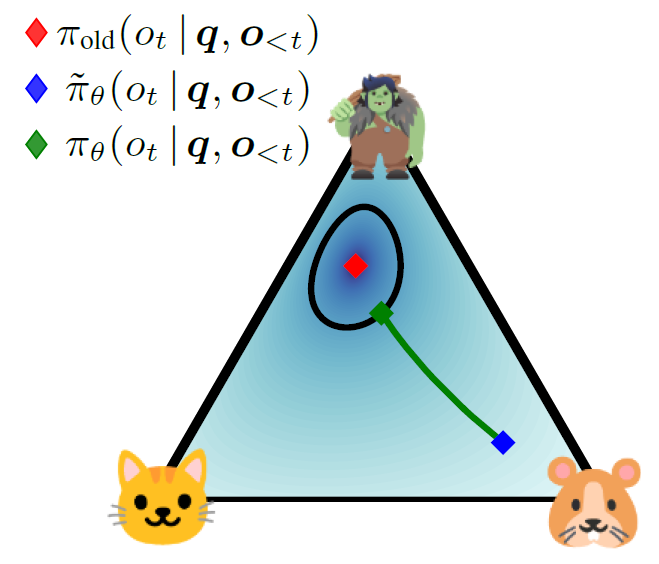
💡LLM을 RL로 학습할 때 모델이 한 번에 너무 크게 바뀌면 망가지므로, 허용된 범위 안에서만 업데이트해서 안전하게 학습시키자
26 March 2026
SEAL: Steerable Reasoning Calibration of Large Language Models for Free
COLM'25
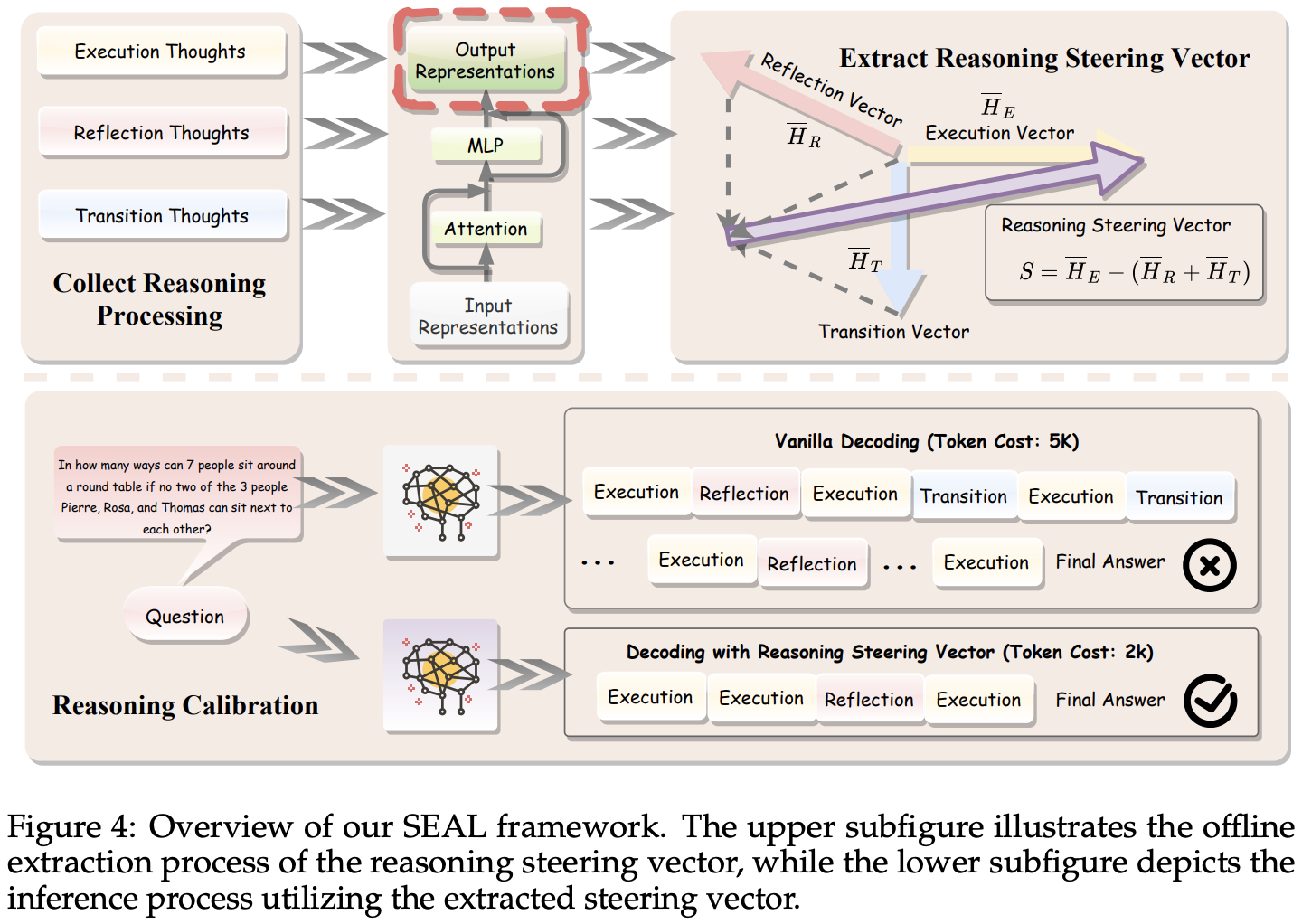
💡너무 길고 복잡한 reasoning 경향을 완화하자!⇒ reasoning process를 세단계로 분류하고, 그 중에 어떤 걸 줄여야 할지 분석하자
26 March 2026
Refusal Tokens: A Simple Way to Calibrate Refusals in Large Language Models
COLM'25
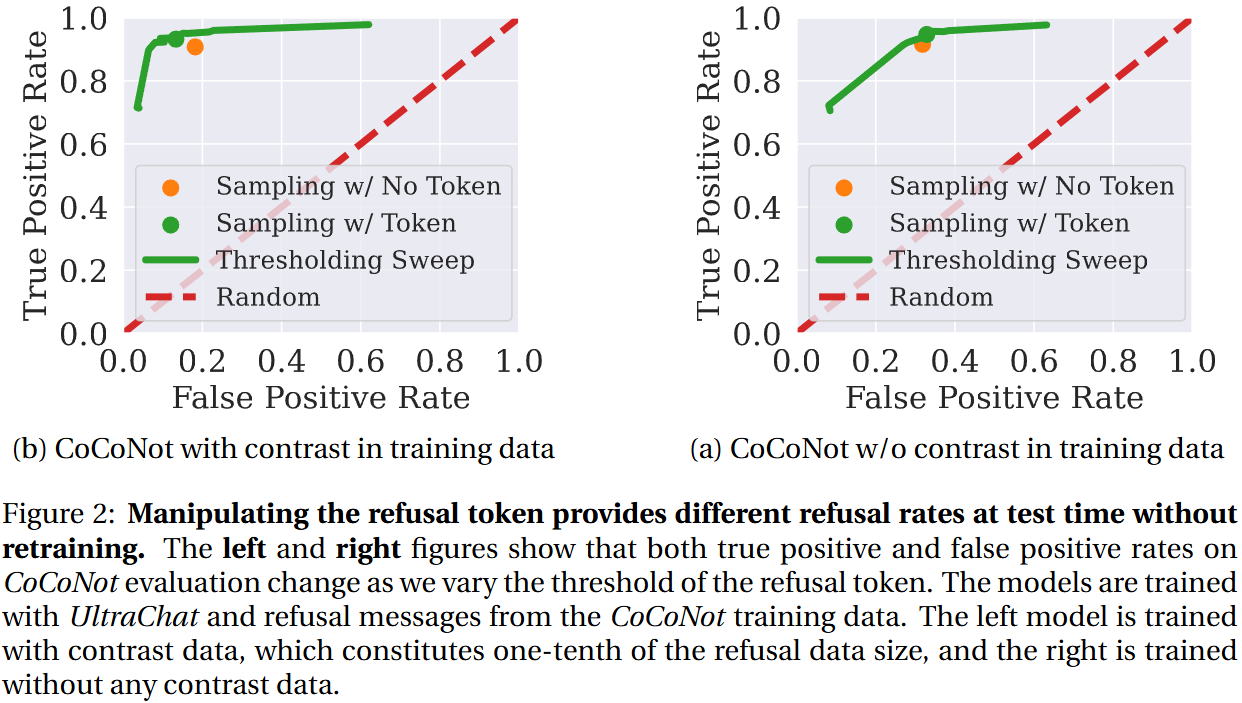
💡Refusal token으로 모델의 응답 거절을 더 섬세하고(성능↑), 유연하게(inference 단에서 조절 가능) 한다!