Beyond Pairwise: Empowering LLM Alignment With (Ranked) Choice Modeling
Review
| 닉네임 | Strength & Weakness & Sugguestions | 별점 (0/5) |
|---|---|---|
| 코스피 | 강점: Ranking Preference 정보를 학습하여 순서 정보를 표본에 반영함으로써 성능을 높인 점이 강점 약점: Preference가 어떻게 더 Rich해졌는지 모호함 제안: Preference의 정보가 증가되었음을 나타내는 증명이나 설명이 추가되었으면 함. | 3.8 |
| 얼라 | 강점: 여러 벤치마크에서 일관된 성능 향상을 보인 점에서 더 rich한 preference 정보를 학습한다는 입장을 힘을 실음 약점: 굳이 여러 쌍으로 할 필요성을 못 느끼겠음. 데이터 수집 비용이나 이런 점에서 practical한 방법론은 아니라고 생각함 제안: 다중 preference가 중요한 요즘, RCPO가 여러 선호가 동시에 존재하는 alignment 환경에서도 유효한지를 검증해보면 좋겟음 | 3.7 |
| 비요뜨 | 강점: preference에 대한 response 정보가 (과도하게) 많다면 response간 구분이 덜 가서 오히려 학습에 방해가 되지 않을까 생각했는데 전역적인 특성을 아는게 더 효과적인가봄 약점: 실험에도 나와있듯이 적당한 k를 잡는게 중요해보임 제안: DPO에 top/bottom pair을 사용한것으로 보이는데, top2 정보를 추가로 사용한다면 결과가 어떨지 궁금함 | 4 |
| 칫솔 | 강점: preference가 이진선택인 상황에서 선택지가 보다 많도록 모델링하는 건 잘 납득가는 동기. 여러 선택지에 대한 선호를 분포로 보아서 방법론 설계한 것도 잘 납득감 약점: 이렇게 세분화하다 보면 SFT 대비해서 장점이 무엇일지 궁금함 제안: pairwise PO vs. RCPO vs. SFT 장단점 심층 분석 | 3.5 |
| 설향딸기 | 강점: 선호도 최적화 학습에 대해서, 새로운 방향을 제시. 약점: 여러개를 하면, 오히려 noisy 한 정보가 더 많아지고, 왜 그 rank가 되는지도 모호해질 것 같은데, 그걸 학습하는 건 오히려 더 어렵지 않나? 차라리, ranking을 매기고 dual로 계속 반복하는 건 이해가 갈 것 같은데, 굳이 여러개의 prefernece를 매번 한다는 것이 납득이 어려움. 제안: ranking은 그대로 하고, 학습은 DPO로 하면 어떻게 되려나? | 3.6 |
| 나스닥 | 장점: 성능이 올랐다! 약점: 이거 이전에 봤던 논문 아이디어랑 좀 겹치는 것 같음.. instruction evolution해서 각각의 순서에 대한 특성을 활용하는 논문이었는데, 너무 아이디어가 창의적이지 않음 제안: 해석가능성을 가지면서 데이터 정렬을 할 수 있다면 더 좋았을 것. 그리고 evol 방법론과 다르게 hard negative라는 특성을 더 강조할 수 있으면 좋지 않을까? | 2.5 |
| 404 | 장점: preference를 binary하게 반영하는 게 아니라, 더 많은 후보군에 대해 ranking함으로서 정교한 preference를 반영할 수 있음. (아마도?) 단점(이라기보다 궁금한 것): 만약 a>b>c>d 이면, 이걸 RCPO로 한번에 주는 것보다 a>b, a>c, a>d, b>c, b>d, c>d 로 넣어주는 게 모델이 더 잘 학습할 수 있지 않을까? 제안: RCPO가 더 rich한 preference이며 학습에 도움이 된다는 것을, 성능으로만 제시하는 게 아니라, 실제 loss가 어떻게 떨어지고 학습 공간에서의 분포가 어떻게 변화하는지 분석하면 좋을듯 ! | 4 |
| AI | 강점: Pairwise 단위의 preference optimization이 아닌, 여러 응답의 순위를 한번에 반영할 수 있다 단점: Choice 모델에 기반을 하는데,, 실제 human preference는 맥락 지식에 의존하고 항상 일관적이지는 않은데 이런것까지 고려못하는건 아쉬움 제안: Preference를 다양한 관점에서 (e.g., 문화, 가치관) 고려하는게 좋지 않나…? OrthAlign 논문과 결합할 수 있을거같음 | 3.5 |
| 국밥 | 강점: Pairwise가 rich한 정보를 학습하지 못한다는 동기가 단순하지만 생각하기 어려운 방법이라고 생각이 됨. top k 방식이 pairwise 보다 더 자연스러운 방식인것 같다. 단점: k와 s의 최적값이 태스크마다 달라질것 같은데 실제 적용하기에 실용성이 떨어지지 않을까. 제안: top2가 최적이라는 설명에 왜 그런지 좀 더 근거가 있으면 좋을것 같음 | 3.6 |
| 커피 | 강점 : DPO와 RLHF의 논문을 접하면서, 항상 pairwise로 학습을 하는 것이 당연하게 여겨졌는데, 여러 rank 비교 정보도 choice model과 확률 분포가 정의가 된다면 반영할 수 있다는 것을 알게 된 논문이었음. 약점 : 그렇다면 당연히 많은 정보를 담고 있는 것이 좋지 않을까 싶었지만, pairwise와 k≥2 각각 에서 성능적인 측면, 비용 측면의 trade-off를 잘 고려해야할 것 같음. 또한 논문에서만 봤을 때는 choice model의 다양성도 부족해 보임. 또한 크게 봤을 때 모델의 구조도 기존의 RLHF 방식과 큰 차이는 없어 보임. 제안 : 다양한 choice model에 대해서도 추가 실험을 통해 명확한 일관성을 주었으면 좋겠음. | 3.6 |

인용수 : 0
TL; DR
RLHF나 DPO와 같은 방법들은 Pairwise(쌍) Preference Optimization에 맞춰져 있어,
더 자세한 정보(Human Feedback)를 학습할 기회를 간과한다.
⇒ Response에 대해 Pairwise뿐만 아니라, 그 이상까지 rank를 매겨 모델에 학습을 시켜보자.
Summary
Introduction & background(⭐)
기존 LLM을 Fine-tuning하는 기법으로 RLHF, DPO가 새로운 패러다임으로 부상하였음.
⇒ 하지만, 이러한 방식들은 “Preference Pairs” 에만 의존하여 rich한 다수 정보들을 2개로 줄여버리기 때문에 가치있는 정보들을 버릴 위험이 있다.
이러한 문제를 해결하기 위해 RCPO(Ranked Choice Preference Optimization)을 제시함.
RCPO는 모델이 입력 프롬프트 x를 받으면,
후보 response 집합에서 “순서” 정보를 학습해 모델이 preference 순서를 학습하게 한다.
⭐ 확률분포로 정의가 가능하면, MLE 표현이 가능하고, Objective(=-loss) 표현이 가능하다.
⭐ Choice model : 여러 개의 선택지 중에서 어떤 것이 선택될 확률을 표현한 모델
⇒ Ranking data를 확률로 쓰기 위해 사용한다!
⭐ Reward model : response의 품질을 점수로 평가하는 모델
- Conceptual Framework : LLM의 Fine-tuning과 Choice Modeling을 연결한다.
⇒ Choice Model이 확률분포이므로, LLM Fine-tuning→Choice model→MLE 연결이 가능하다.
- Concrete Example of Choice model : 대표적인 Choice model 예시로 MNL과 Mallows-RMJ를 사용.
⇒ 각 choice model별로 objective 함수를 정의
- Experiments : RCPO Framework를 Llama-3-8B-Instruct, Gemma-2-9B-it, Mistral-7B-Instruct에서 평가.
⇒ In-distribution, out-of-distribution benchmark에서 평가함.
Motivation
- Rich한 정보를 잃을 수 있는 Pairwise 방식에서, 꼭 Response 표본을 2개로 두어야 할까?
⇒ 2개 이상을 설정해보자.
- 2개 이상으로 설정한다면, 해당 후보 Response들은 어떻게 만들까?
⇒ 모델에서 나온 후보 response들을 reward model을 기반으로 점수를 매겨 만든다.
- Choice model을 LLM과 연결시킬 수 있을까?
⇒ 모델 Fine-tuning에는 Objective 함수가 필요한데, 이것은 확률 분포와 MLE를 기반으로 두기 때문에, Choice model을 확률 분포로 정의할 수 있다면 가능하다.
- 후보 Response를 2개 이상으로 설정했다면, 결과의 갯수도 영향이 있을까?
⇒ Preference 순서 정보가 많다면 당연히 좋아보인다. 실험에서 확인.
⭐ 결과적으로, Preference에 따른 순서 정보를 모델이 학습함으로써, 지역적 정보에서 전역적인 순서 정보를 알게된다!
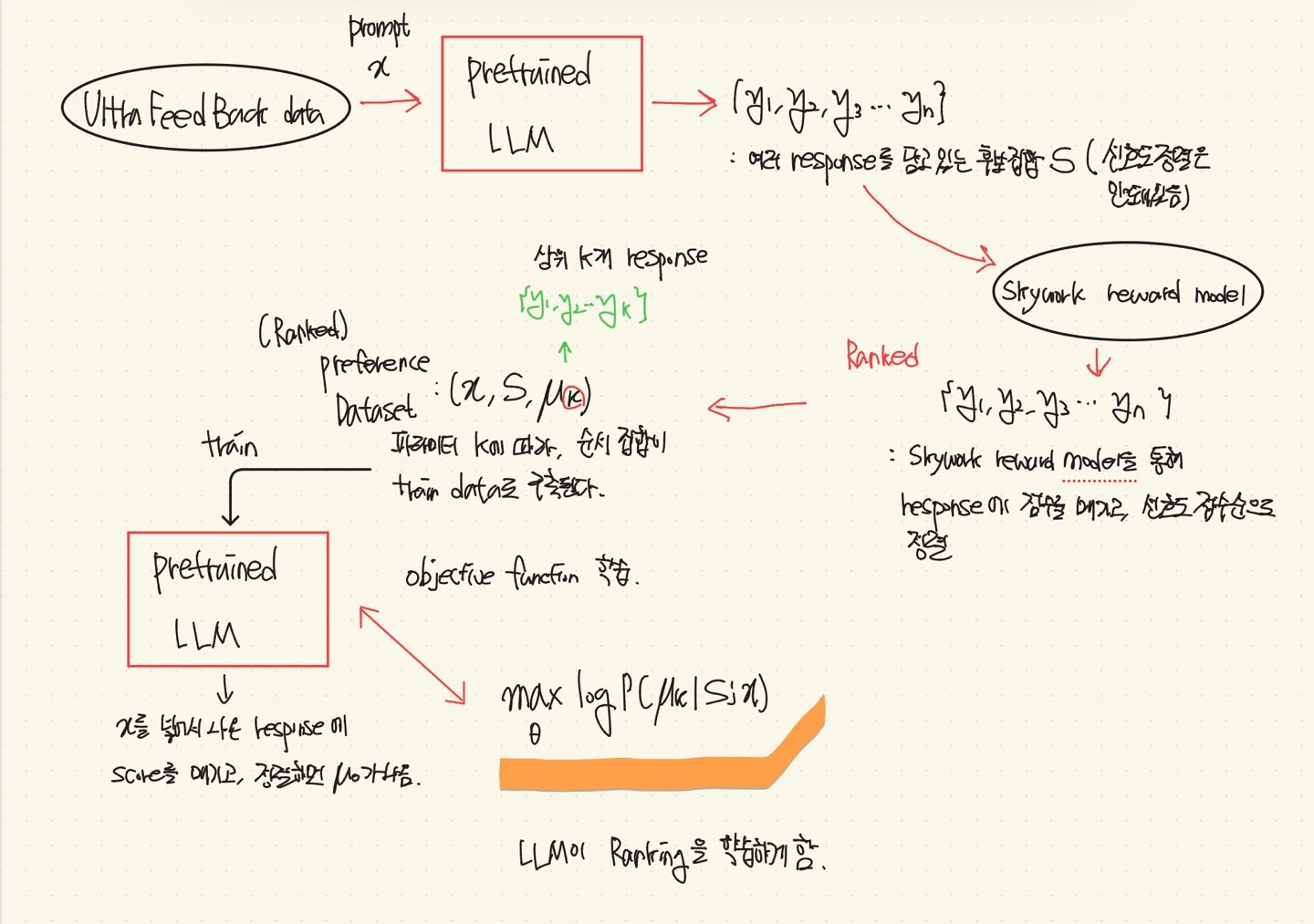
**아래 figure는 Pairwise, Single-Best Feedback, Top-k Feedback 구조이다.

Contribution
전체 파이프라인
(1) 이미 훈련된 LLM을 가져옴
Llama-3-8B-instruct, Gemma-2-9B-it, Mistral-7B-instruct
(2) Choice model 선택(MNL, Mallows-RMJ)
MNL이란?
utility 기반의 choice model
각 response는 utility(점수)를 갖는다. → 점수가 높을수록 선택될 확률이 커진다.

Mallows-RMJ Model이란?
Rank 기반의 choice model ⇒ 순위가 어떤 확률로 생성되는지 정의하는 모델

(3) 선택된 Choice model을 바탕으로 objective function 정의(=Loss)
MNL의 확률분포, objective function
Single-best(결과가 하나)
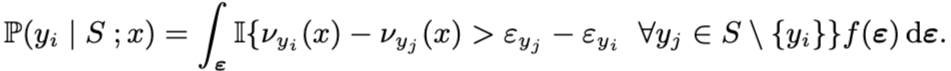
Top-K(결과가 여러 개)
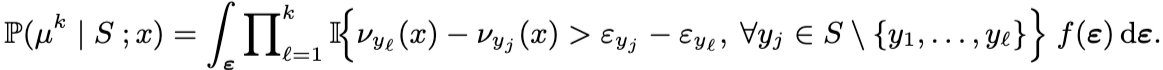
closed form으로 각각 재표현할 수 있다.
Single-best
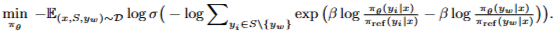
⇒ winner resonse와 나머지 response를 전부 동시에 비교함.
Top-K(결과가 여러 개)
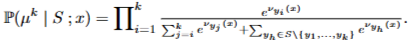
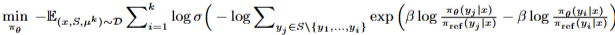
Mallows-RMJ Model 확률분포, objective function
Single-Best
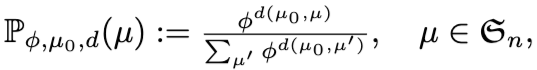
Top-K
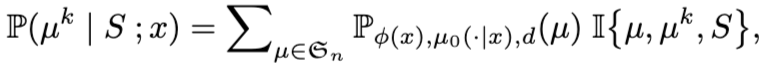
closed form으로 각각 재표현할 수 있다.
Single-best
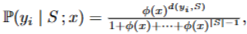
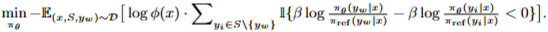
Top-K
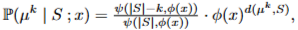
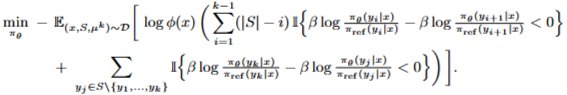
(4) TrainData Set을 통해 Ranked based preference data를 만듦.
UltraFeedback Dataset을 사용함.
- LLM에 UltraFeedback Dataset의 프롬프트 x 입력
- x를 받고 LLM이 생성한 여러 응답(후보 집합)에 대해 reward model로 점수를 부여 후 정렬
- (X,S,μk) 형태로 데이터 구축
(5) 위에서 생성된 데이터와 objective function으로 LLM을 Fine-tuning

- Mallows-RMJ-PO-Top-2 방식이 가장 성능이 좋기에, 대표적으로 설명함.
- 높은 순위에 대한 가중치는 올리고, 낮은 순위의 가중치는 낮춤.
- 또한 S에서 랭킹의 위치와 reward의 비슷한 정도에 따라서 업데이트 강도를 조절한다.
Experiment & Result
- out-of-distribution : AlpacaEval 2.0 / Arena-hard-v0.1 (명령어 수행 벤치마크)
AlpacaEval 2.0 = Fine-Tuning LLM과 GPT-4-Turbo에서 생성된 답변에 대한 WR과 LC로 측정.
Arena-hard-v0.1 = Fine-Tuning LLM과 GPT-4-0314에 대한 WR을 측정
⇒ Q : 이렇게 하는 의미는?
⇒ A : [Fine-Tuning 모델 출력과 평가자 역할의 모델 출력]을 두고, GPT-4.1-mini를 통해 어느 것이 더 적합한 출력인지 평가한다.
Arena-Hard-v0.1에서는 GPT-5-mini를 심판역할에 추가 사용함.
- in-distribution
[Fine-Tuning 모델 출력과 기존 Test Dataset의 Preference Response] 를 두고 GPT-4.1-mini를 통해 어느 것이 더 적합한 출력인지 평가한다.
Llama-3-8B-Instruct
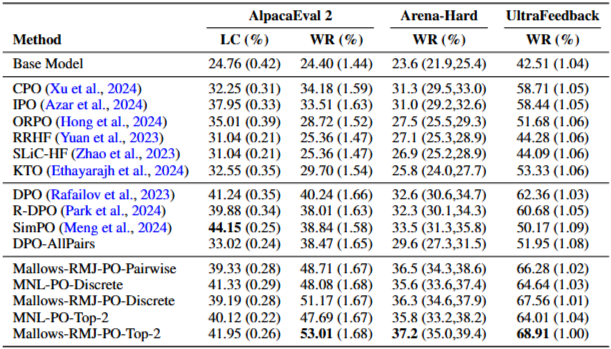
- 전반적으로 Mallows-RMJ-PO-Top-2가 성능이 가장 좋음을 확인할 수 있음
- Top-2인 이유?
⇒ Top-2 Feedback으로 학습하는 것이 일반적으로 Top-1보다 더 나은 성능을 보인 것을 확인.
- Choice model의 영향
어떤 Choice model을 쓰느냐에 따라서, 성능이 좌우된다.
⇒ Q) AlpacaEval 2 dataset의 LC 부분에서 SimPO의 성능이 왜 더 좋을까?
⇒ A) LC는 길이 보정을 한 후의 비교 결과로, SimPo가 길이에 덜 의존적이고, 안정적이기 때문.
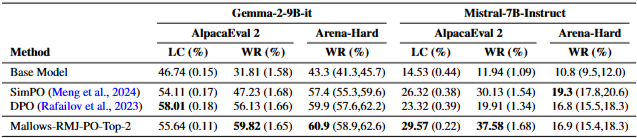
다른 LLM 모델에 적용했을 때의 결과
Ablation Study
마찬가지로, Llama-3-8B-Instruct를 사용하고, 순위의 갯수 K와 집합 크기 S를 살펴봄.

- K와 성능은 항상 비례하지 않음.
⇒ K가 커질수록, 정렬 과정과 항목들을 구별하기 어려워짐.
- S는 성능에 일반적으로 비례하지만, S=3만으로도 S=2(Pairwise)에 비해 상당한 개선을 달성함.
⇒또한, S가 커질수록 negative sample이 생겨, LM이 구별 능력을 학습할 수 있음.
💡S와 K의 균형을 맞추는 중간 정도의 값이 이상적이다.
- K와 성능은 항상 비례하지 않음.
- out-of-distribution : AlpacaEval 2.0 / Arena-hard-v0.1 (명령어 수행 벤치마크)
conclusion
RCPO는 Preference Optimization(선호도 최적화)과 Choice Model Estimation(선택 모델 추정법)을 연결하는 Framework임.
MLE를 사용하여 RCPO는 Pairwise, Single-Best, Top-K Preference Data를 통합함.
Utility-Base와 Rank-Base Choice model을 예시로,
RCPO는 Pairwise보다 더 풍부한 피드백을 보존해내는 성능 개선 결과를 보여줌.
💬 기존 연구는 Preference Pairwise에 대해 학습하므로, rich한 정보를 학습하지 못했다.
⇒ RCPO는 여러 response에 대한 ranking preference 정보를 choice model의 확률로 변환하여, LLM에 학습시킨다.
⭐ 더 rich한 preference 정보를 학습할 수 있다.