19 March 2026
Beyond Pairwise: Empowering LLM Alignment With (Ranked) Choice Modeling
ICLR'26 Poster
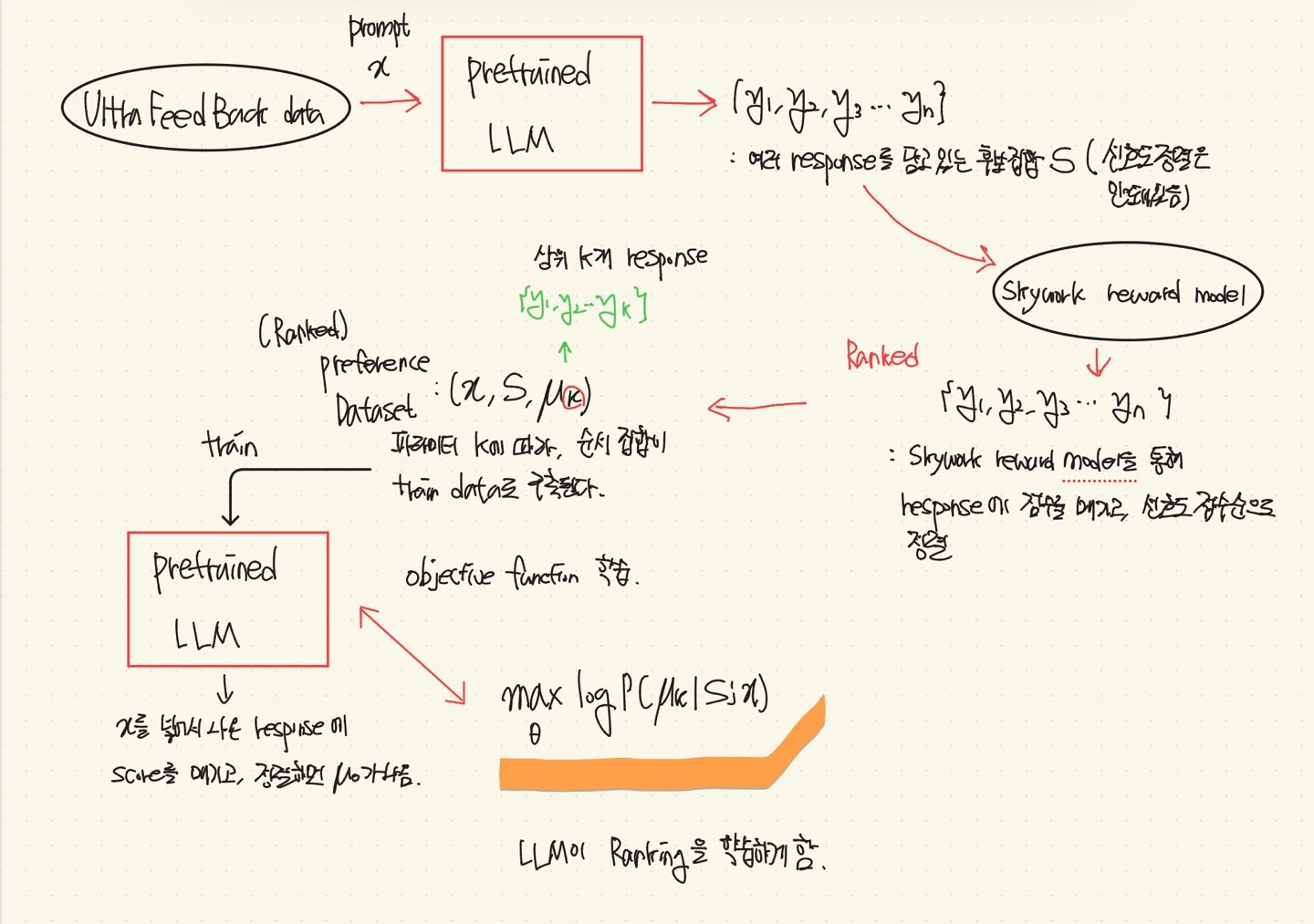
💡RLHF나 DPO와 같은 방법들은 Pairwise(쌍) Preference Optimization에 맞춰져 있어, 더 자세한 정보(Human Feedback)를 학습할 기회를 간과한다.⇒ Response에 대해 Pairwise뿐만 아니라, 그 이상까지 rank를 매겨 모델에 학습을 시켜보자.