Why DPO is a Misspecified Estimator and How to Fix It
Review
| 닉네임 | Strength & Weakness & Sugguestions | 별점 (0/5) |
|---|---|---|
| 커피 | 강점 : DPO는 기존 RLHF의 마지막 복잡한 2단계(reward, RL)를 우회하기 때문에, 무조건적으로 좋은 줄 알았지만, reward의 정확성을 잃게 되어 trade-off가 생기는 것을 알게되었음. 약점 : LLM 파라미터도 많을텐데, 실제로 null space 탐색이 용이할까? 또한 DPO에서 추가 계산이 생긴만큼 cost도 증가하지 않을까…? 제안 : reward의 정확성을 고려하면서 null space 를 효율적으로 탐색하는 방법이 필요할 것 같음. | 4.3 |
| 코스피 | 강점: DPO가 무조건 정확도가 높다고 알고 있었는데, 분포 자체의 영향으로 신뢰성이 떨어지는 점을 언급한 것이 이 논문의 강점. 약점: Null Space의 차이와 추가적인 자유도를 고려하는데 여기서 오차가 생길 수 있는 부분이 있지 않을까? 제안: Failure Mode를 고려한 Optimization을 하는 방법도 좋을 것 같음. | 4.5 |
| 얼라 | 강점: misspecified estimator 라는 개념 자체가 몹시 흥미로움. ICLR Oral은 대단하구나 약점: Null space 방향으로 보조 변수를 설정할 때 어떻게 초기화 최적화할지 모호함 제안: 좀 더 큰 모델이나 다양한 alignment에서도 동일하게 되는지 추가 검증이 더 필요해보임 | 4.5 |
| 비요뜨 | 강점: 말로만 들으면 굉장히 추상적일 수 있게 느낄만한것을 fig로 잘 설명한거같음. DPO의 보상/ 정책 공간이 좁아서 생기는 문제를 '추가 변수로 표현력을 늘리는 식으로 직관적으로 개선을 시도함 (근데 확실히 내용이 어렵다) 약점: null space는 결국 모델의 정책 최적화 과정에서 (보상의?) 변화가 없는 공간을 뜻하는것 같은데, null space 선택에 따라 달라질 수 있을것 같음. 제안: pairwise보다 풍부한 랭킹 피드백을 쓸 때의 투영이 어떻게 변화하는지 궁금함 | 4.2 |
| 칫솔 | 강점: 수학적으로 강건하게 오류분석하고 해결방법 제안했는데, 이론적으로도 강하고 경험적으로도 성능 향상 큼 약점: 비용이 어느정도로 증가했을지 궁금함, 많이 증가하는지? 제안: 보다 큰 모델에 대한 실험결과. 효율성 관련 분석이나 개선 | 4.7 |
| 설향딸기 | 강점: DPO가 가지는 유한 공간에서의 근사 문제를 규명하고, 해결함. 매번 느끼지만, 결과만 놓고 보면 직관적인데, 이걸 어떻게 생각했을까하는 생각이 든다. DPO에서 reward를 사용하지 않아도 보완하는 방법이라고 생각함. 약점: null space가 자유도를 고려하지만, 결국 데이터 분포에 영향 받는 점은 매한가지 아닌가? 제안: 오히려, 이 연구의 방법론과 결과를 봤을 때 굳이 DPO에서 reward를 제외해야 할 근거를 딱히 생각하지 못하겠음. main reward가 아니더라도, 보조 reward 형태로 도입하는 것이 데이터 분포에 더 견고한 방법이지 않을까? | 4.3 |
| 나스닥 | 강점: DPO같이 prove를 가지고 있는 논문들은 보통은 현실적인 issue(더 좋은 데이터는 보통 더 상세하기에 길이가 더 김)를 담고 있어서 그것들을 타겟팅하는데, 모델단의 issue를 짚고 넘어가는 것은 진짜 소수만 할 수 있을 것 같고, 굉장히 중요한 문제점을 짚었다는 생각이 듦! Soundness가 11/10! 약점: 비교 모델들이 좀 out-dated된 듯 함!! 앞에서 잘해놓고 왜 토끼들을 상대하지? 제안: 유한한 것이 문제라면 작은 모델, 작은 데이터 사이즈부터 큰 모델, 큰 데이터 사이즈까지 올리면서 DPO와의 간극 차이를 보이는 것이 이론적인 성과를 강조하는 데에 도움될 것! | 5 |
| 404 | 강점: DPO와 같이 파급력이 큰 학습 기법의 고질적인 (그러나 모두가 놓치고 있는) 부분을 캐치함. 매우 똑똑하고 연구력(?)이 뛰어나서 부러움. 또한 저자들의 motivation를 수식적/기하학적으로 표현하고 주장하는 능력이 뛰어남. 약점&제안: 더 많은 task/더 다양한 backbone LLM에 대해서 실험했으면 내용이 더 풍부해졌을 듯 | 4.5 |
| AI | 강점: 얼핏보면 단순히 RLHF의 변이로 볼 수 있는 DPO를 사실은 reward를 추정하는 통계 문제로 해석하는 발상이 놀라움 약점: 산업 도메인과같은 대규모 데이터에서는 데이터마다 추가 변수를 만드는 방식이 다소 제한적일 순 있을듯? 제안: 모델이 움직이는 local 영역을 넘어 global 관점의 해석이 필요 | 4.7 |
| 국밥 | 강점: DPO가 데이터 문제가 아니라 설계 수준에서 misspecification이 있다는걸 수학적으로 증명하고 보조변수로 이동 방향을 늘린다는 아이디어가 대단하다고 생각함 약점:실험의 LLM 크기가 작아서 대형 모델에서도 동일한 misspecification 문제가 있는지 알 수 없을것 같다. 제안:모델 파라미터 크기에 따른 DPO와 AuxDPO의 차이를 보여주는 실험 | 4.5 |
TL; DR
DPO의 전제가 realistic하지 않음을 위상학적으로 파헤침
AuxDPO를 통해 DPO의 Misspecifection를 완화하자!
Summary
- 연구진: 인도과학원(IISc Bangalore), HP AI Research
- github: x
- 인용수: 0회
Background & Motivation
Preference-based alignment
💡given comparison data (s, , ), the goal is to shape a policy π whose induced responses align with a latent reward model that generated those preferences.
** : state, : action, : winning action, : losing action
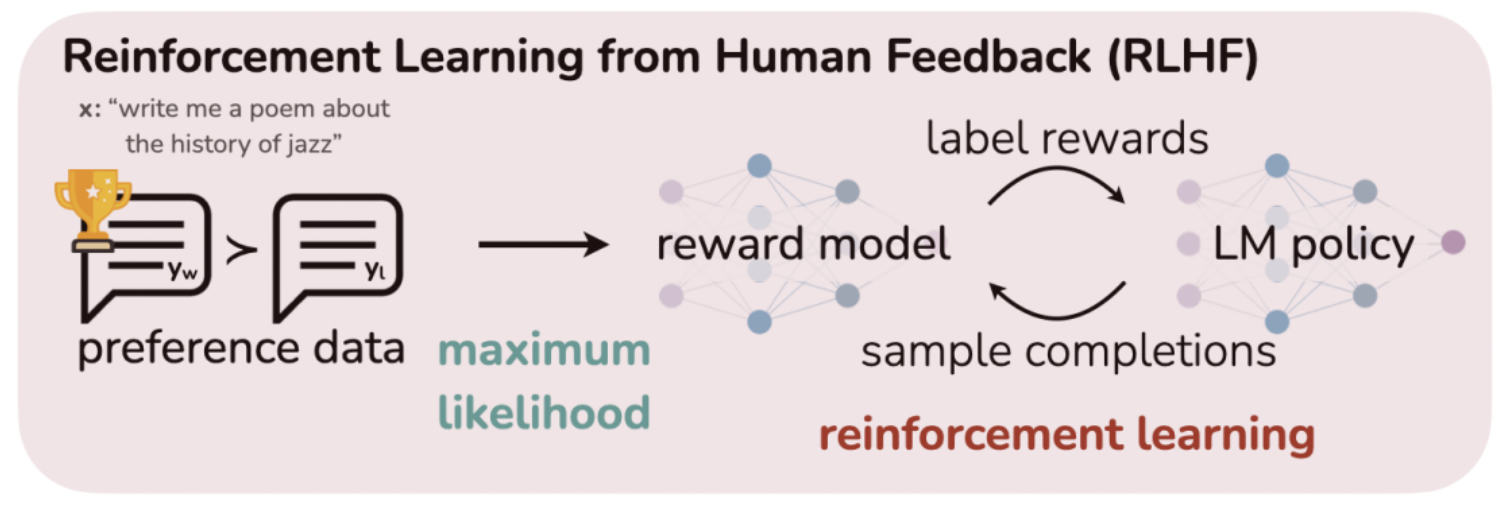
Direct Preference Optimization: Your Language Model is Secretly a Reward Model (NIPS’23) - policy model을 두단계에 걸쳐 학습해야 함
- pretrained model (1차 학습)을
- reward model의 prefer로 steering (2차 학습)
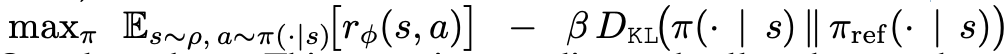
- 따로 reward model도 학습시켜야 함
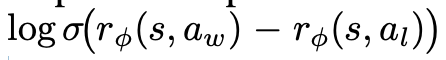
⇒ computational cost가 너무 큼 !!
- policy model을 두단계에 걸쳐 학습해야 함
- DPO (Direct Preference Optimization)
Direct Preference Optimization: Your Language Model is Secretly a Reward Model (NIPS’23) - 2차 학습(KL-regularized objective) 대신에, human이 선호하는/덜 선호하는 preference data를 활용함
- how to?
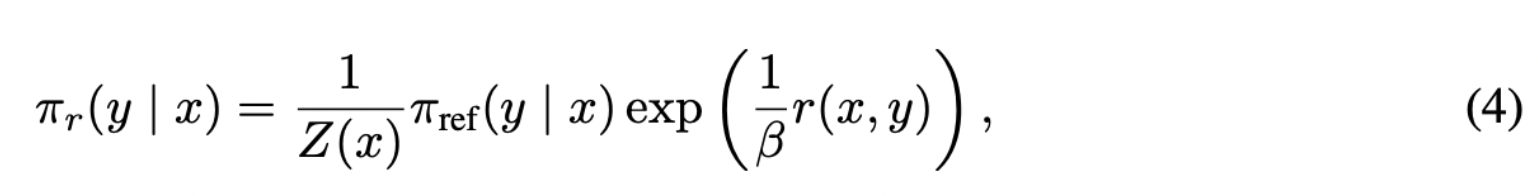
Direct Preference Optimization: Your Language Model is Secretly a Reward Model (NIPS’23) 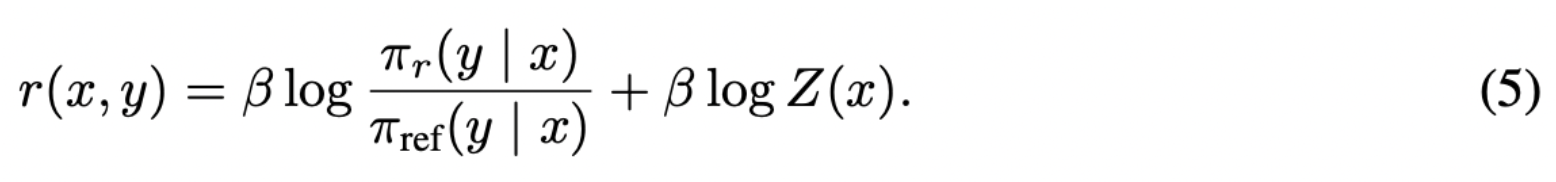
Direct Preference Optimization: Your Language Model is Secretly a Reward Model (NIPS’23) policy 수식에 변형을 통해, reward 함수(Eq 4)를 policy 함수의 확률 분포(Eq 5)로 표현하고,
이를 근사하여 2차 학습(KL-regularized objective)를 근사화
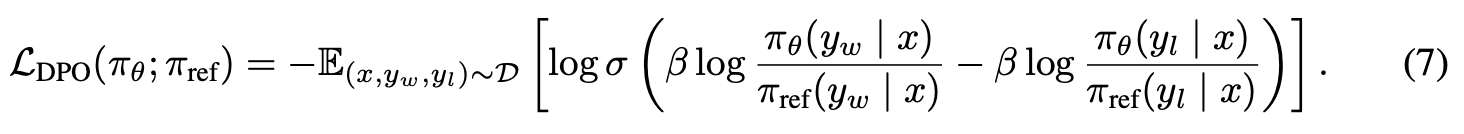
Direct Preference Optimization: Your Language Model is Secretly a Reward Model (NIPS’23)
⇒ 1번의 training만으로 학습
⇒ cost를 줄일 수 있어, Preference-based alignment 의 대안이 됨
- how to?
- “policy class가 tabular”이라는 이상적인 가정을 전제로, KL-regularized policy optimization을 근사화 한 것임
**
policy class: neural network(θ)가 정의하는 conditional distribution 즉, input에 대한 output 분포**
tabular하다: 특정 row(e.g. input)와 특정 column(e.g. output)에 해당하는 값(e.g. reward)이 table처럼 정의될 수 있다!즉, policy class가 모든 조건부 분포를 표현할 수 있는 tabular class여서, 모든 (Input s, output a)에 대해 conditional probability distribution 을 가진다
⇒ 실제로는 그렇지 않다!!
why?Transformer는 neural architectures라서, parameter의 수가 유한함! (non-tabular)
- 2차 학습(KL-regularized objective) 대신에, human이 선호하는/덜 선호하는 preference data를 활용함
- Main Motivation
non-tabular policy class에서 DPO loss를 최소화하는 것이 full two-stage RLHF와 동등한가? 만약 그렇지 않다면, ideal RLHF-optimal policy과 어떻게 다른가? ideal RLHF-optimal policy의 성능과 동일하다는 보장이 있는가? 만약 그렇지 않다면, 해결책이 있는가?
Contributions (What they’ve revealed)
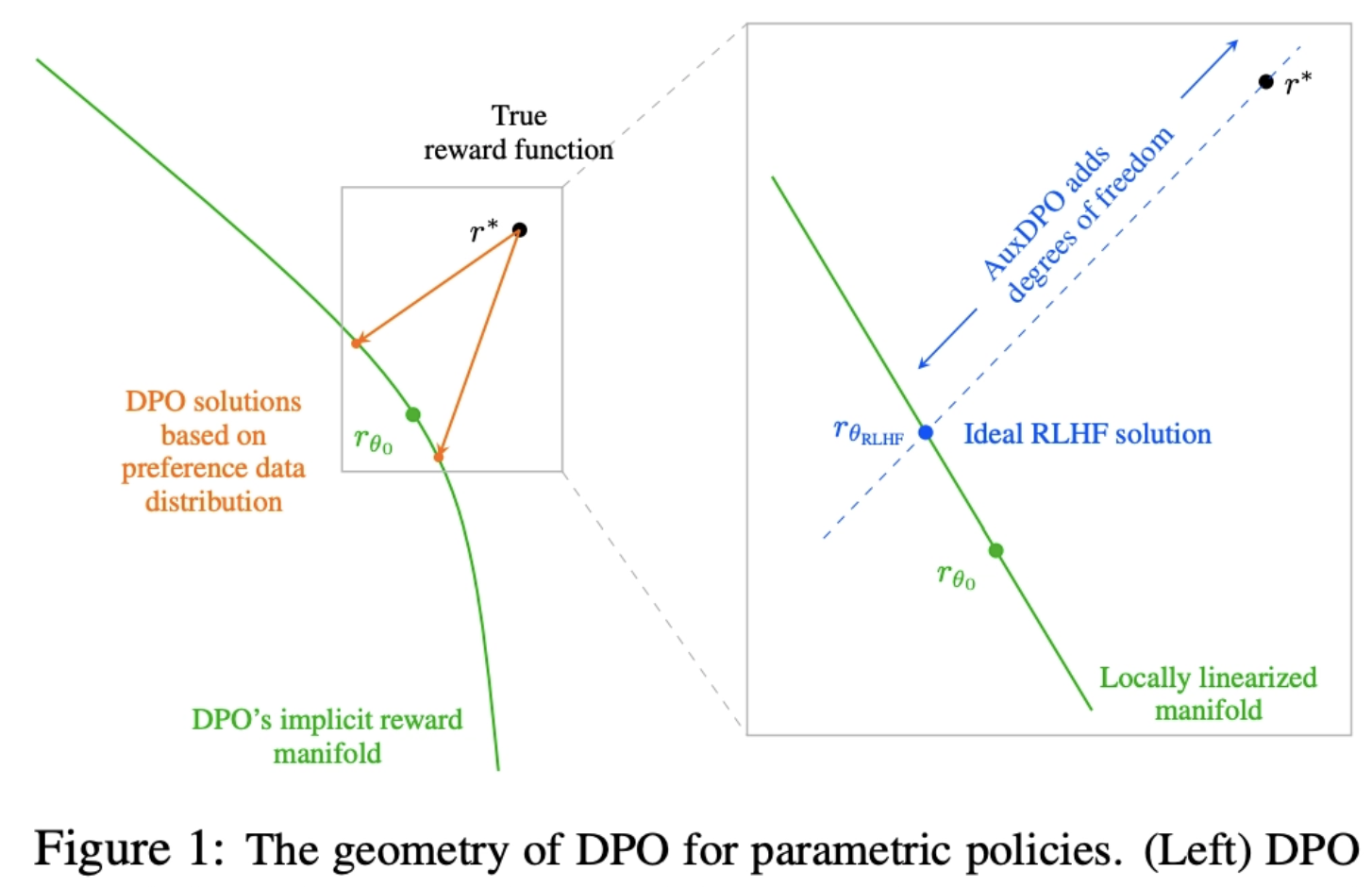
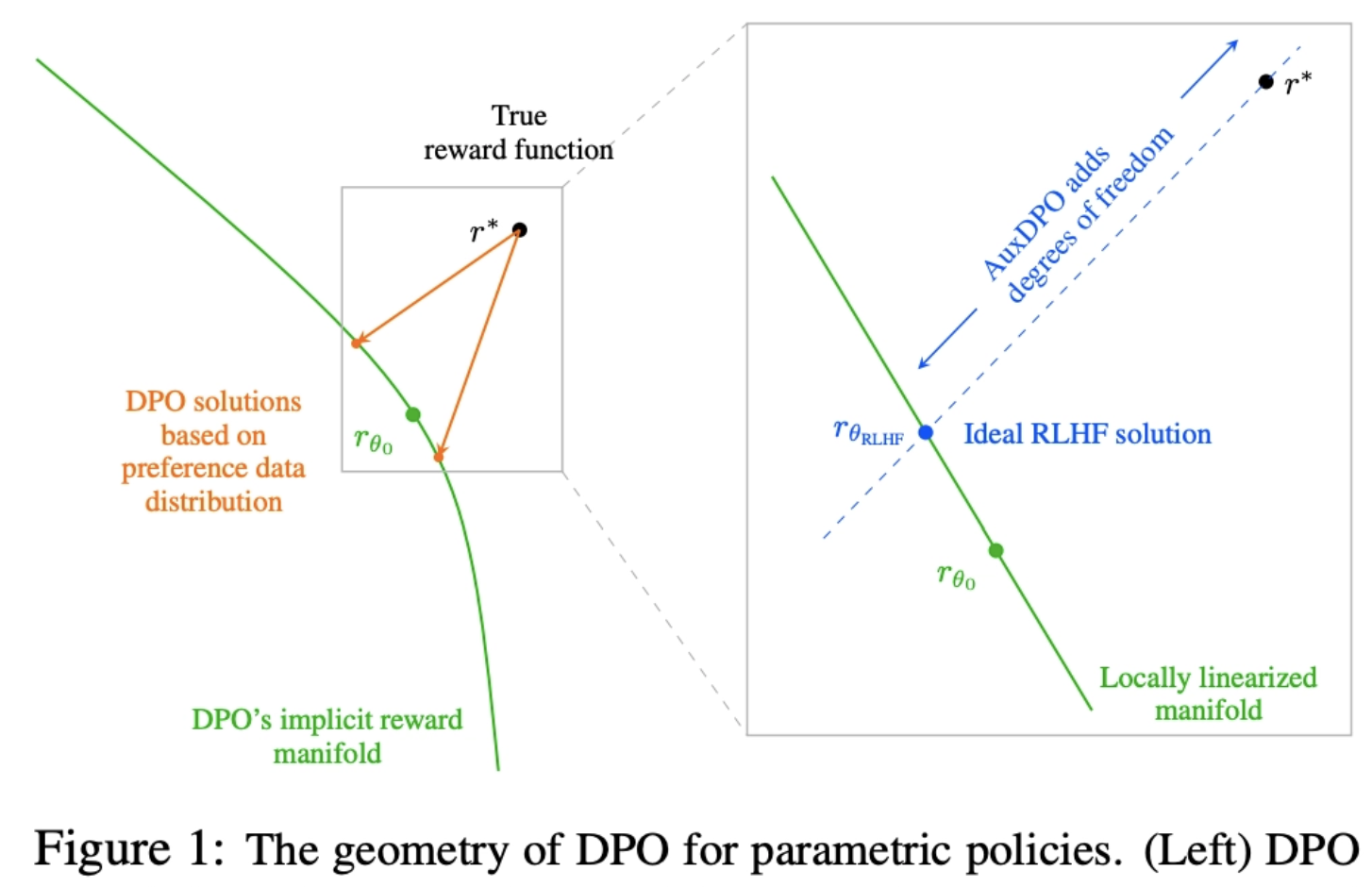
DPO는, 실제로 생성된 reward function(r*; 검은 점)를 policy class에 의해 암묵적으로 표현되는, reward function의 manifold(DPO’s implicit reward manifold; 초록 곡선)로 projection함
- 이상적인 건 r*가 manifold 위에 있는 것이지만, 아닌 경우 data distribution에 영향을 받아 unreliable solution (주황 점)으로 projection 한다
- data가 Noisy해서 발생하는 것이 아니라, 분포 자체에 영향을 받아 unreliable하다는 것!
⇒ AuxDPO를 통해 추가로 조절할 수 있는 degrees of freedom를 추가하여, projection 오차를 줄임
⇒ 이상적인 RLHF solution θ 에 대응하는 reward function( ; 파란점)으로 투영할 수 있도록 하자!
DPO 알고리즘이 다양한 failure mode를 가질 수 있음을 수식적으로 밝힘
: 양질의 데이터(=true reward function r∗를 기반으로 하는 Bradley-Terry-Luce (BTL) model로부터 생성되는 infinite preference data)를 사용하고, 아주 단순한 설정(single prompt를 쓰고, 3가지 응답에 대한 1차원 policy parameter 사용)에서도 DPO가
두 번째로 좋은 응답을 더 선호하도록 학습되거나(
order reversal of preferences)최고 보상 응답의 확률이 기준 정책보다 감소함 (
overall reward reduction)⇒ 특히, 어떤 preference pair data가 많이 사용되었는지(=count)에 대해서도 매우 민감함.
about Bradley-Terry-Luce (BTL) model
: “두 선택지 중 무엇을 더 선호하는가” 같은 pairwise comparison를 확률로 모델링하는, 가장 심플한 생성 모델 중 하나
DPO 알고리즘의 misspecified statistical estimation problem을 밝힘
- tabular assumption 때문에, 실제 DPO의 projection이 optimal하지 않다!
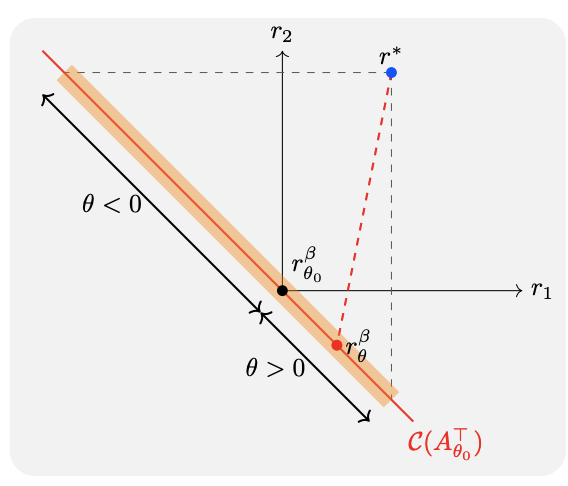
An example with 3 responses and 1-d policy parameter showing failure modes of DPO. r∗ is the latent reward. The red line denotes the linear approximationC(A^⊤_θ0 ) of the implicit reward manifold Rβ . The region shaded in orange represents all possible implicit reward functions that DPO can possibly project onto, depending on the relative proportion of pairwise preference counts n_1,2, n_2,3, n_3,1. If n3,1 dominates the rest, then the projection rβ θ induces a postoptimized policy parameter θ > 0, leading to preference reversal and reduction of expected reward, causing DPO to fail. DPO는 implicit reward manifold( ;실제 DPO가 표현할 수 있는 reward 공간;빨간선)위로 실제 reward (r*; 파란 점)를 projection하는 것이며, 대부분 DPO는 데이터 분포에 의해 mis-projection(red dashed line)될 가능성이 큼
- reward는, model의 더 좋은 선택을 위해 policy parameter를 어느 방향으로 update할지를 알려줌. 그런데 실제 DPO의 reward는 유한한 manifold라서, reward를 바꾸더라도 policy가 항상 유의미하게 update되지 않는다!
즉, policy에 영향을 주지 않는 null space 가 존재한다
- tabular assumption 때문에, 실제 DPO의 projection이 optimal하지 않다!
DPO의 misspecification을 우회하기 위한 AuxDPO 제안
: policy에 영향을 주지 않는 null space 를 자유도로 활용하자!
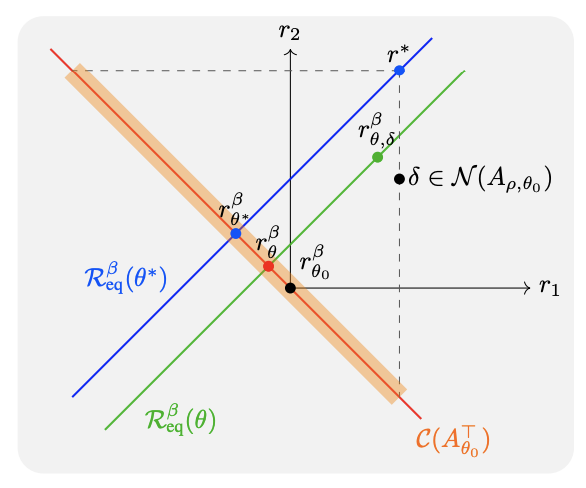
AuxDPO fixes DPO’s misspecification. r∗ is the latent reward. The blue line denotes the equivalence class R^β_eq(θ∗)of all reward functions that yield the RLHFoptimal policy πθ∗ . The red line denotes the linear approximation C(A^⊤_θ0 ) of the implicit reward manifold Rβ . The region shaded in orange represents all possible implicit reward functions that DPO can possibly project onto. The green line depicts the domain of optimization over AuxDPO’s auxiliary variables δ ∈ N (A_ρ,θ_0 ) for a fixed θ (the line shifts in parallel for other θ). δ introduces additional degrees of freedom, which help push the KL projection of r∗ to lie in the equivalence class Rθ∗ . The projection induces the optimal policy πθ∗ . DPO는 implicit reward manifold( ;실제 DPO가 표현할 수 있는 reward 공간;빨간선)위로 실제 reward (r*; 파란 점)의 equivalence class(policy 관점에서 같은 효과를 내는 reward의 집합;파란선)를 projection하는 것.
실제로는, r*와
optimal policy간에 ( reward space 이 아닌, null space 의 원소)만큼 차이가 발생함.**
⇒ null space 방향으로 움직이는, 추가적인 자유도 ( ; green line)를 활용하여 reward space 을 탐색하도록 하자!
즉, 를 만족하는 를 탐색할 수 있도록 기존 DPO에 항을 추가하여, optimization(green line)하자!
⇒ 빨간선+초록선을 함께 움직일 수 있게 되어 misspecification 완화!
- AuxDPO 수식
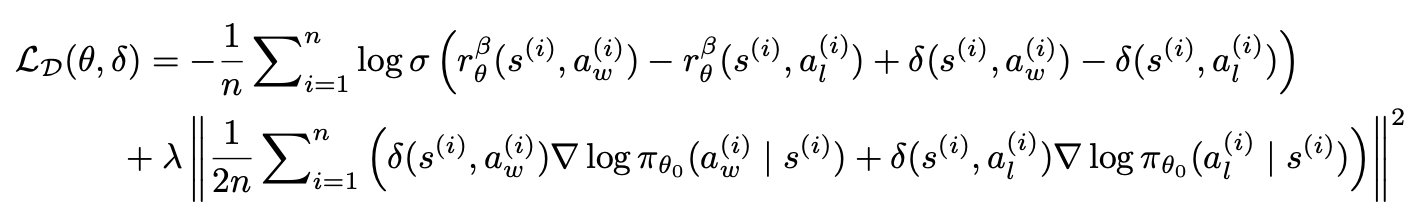
- δ 로 시작하는 항이, null space를 활용한 부분
- 실험을 통해 AuxDPO의 효과 증명
- 실험 세팅
- dataset
- for training: ULTRAFEEDBACK
- for eval: MMLU-PRO, REWARDBENCH V2
- LLM: Llama3.1-8B , Llama3.2-1B, Qwen3-0.6B
- dataset
- 결과
- Table1: base LLM 대비 mean accuracy 변화량(%)
** 10이면 베이스보다 평균 정확도가 10%p 올라갔다는 뜻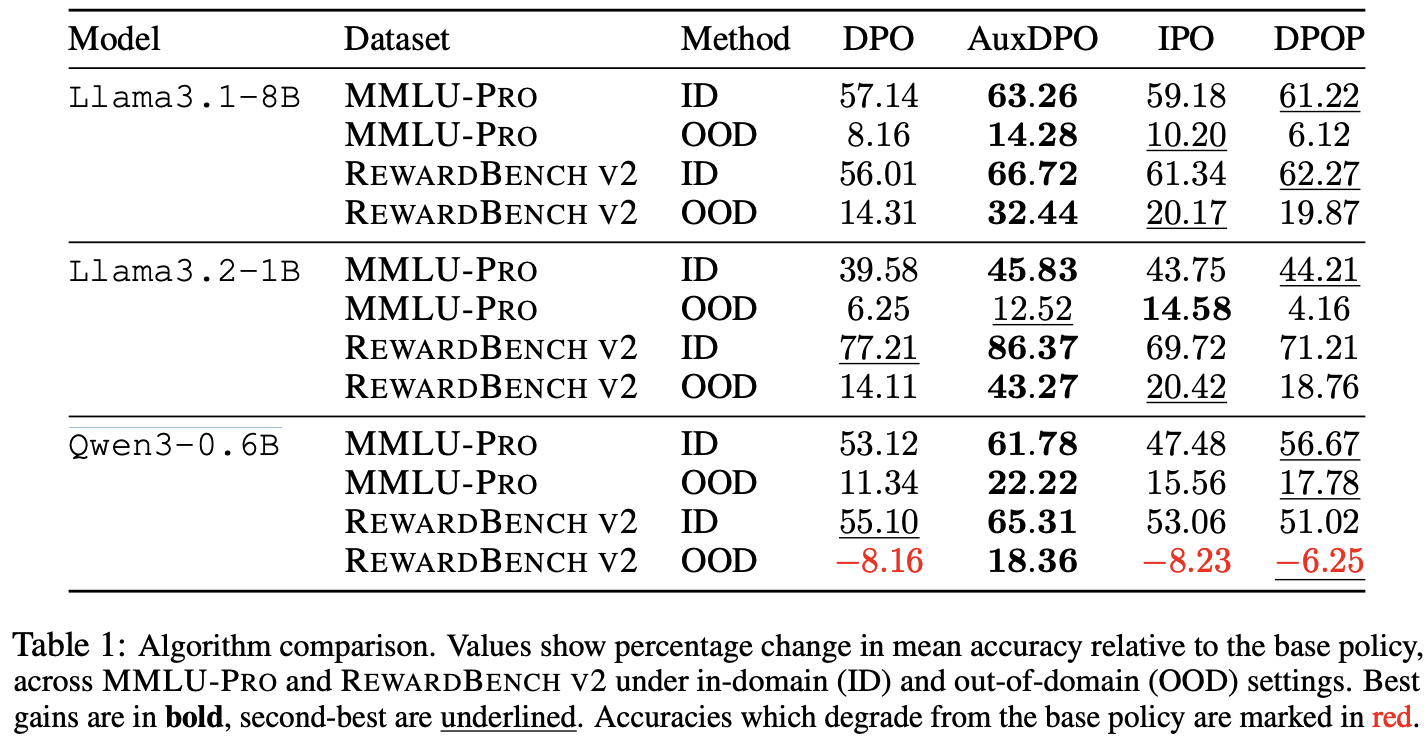
base policy 대비 mean accuracy (chosen logit > rejected logit)변화량 - 전반적으로 AuxDPO가 큰 개선을 보임!
- 특히 out-of-domain (OOD) setting 에서
- DPO는 오히려 base LLM의 성능을 해치기도 함
- Llama3.1-8B에 대한, MMLU-Pro의 subject 별 성능
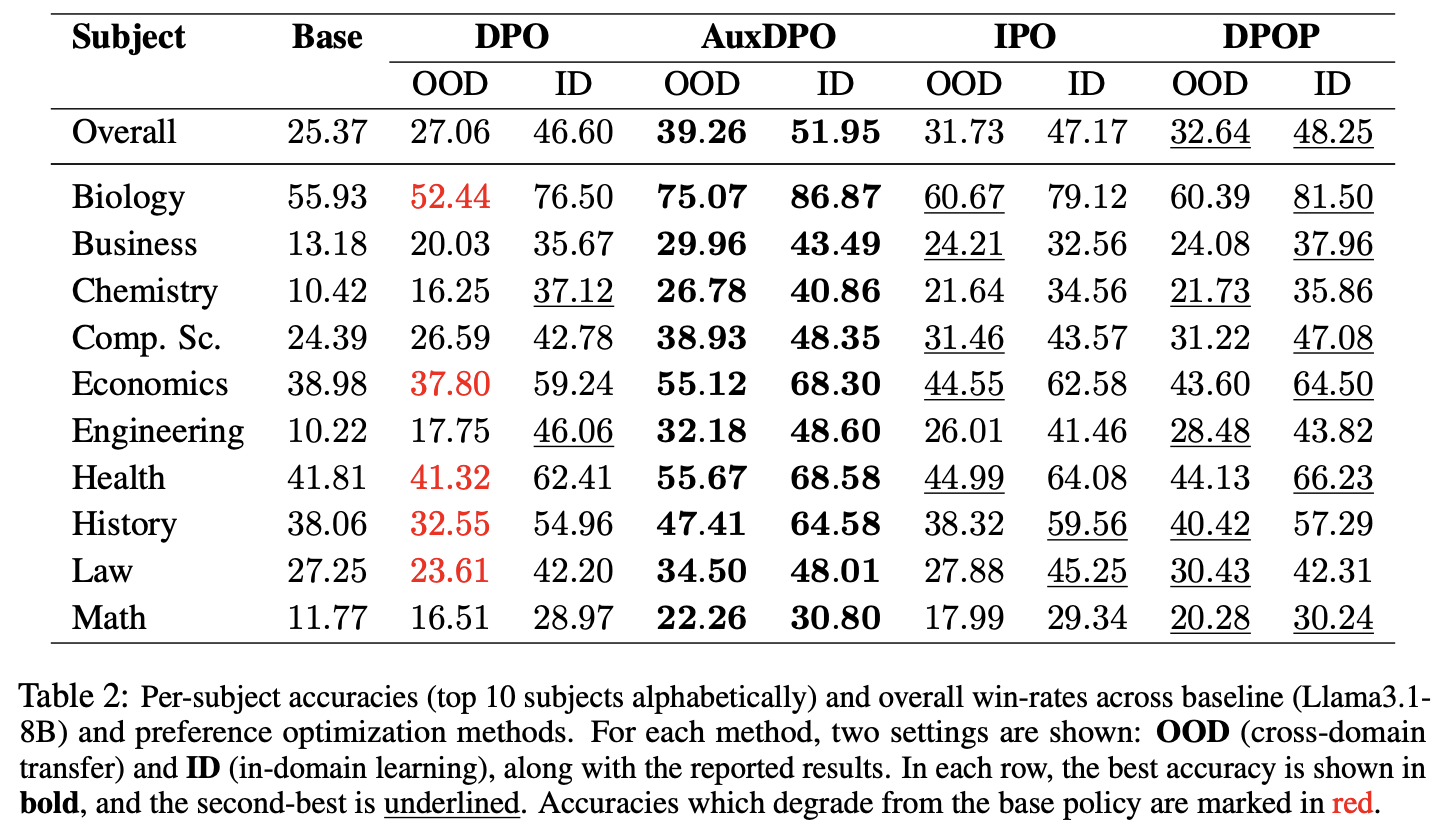
- Table1: base LLM 대비 mean accuracy 변화량(%)
- 실험 세팅
- AuxDPO 수식