26 March 2026
LoongRL: Reinforcement Learning for Advanced Reasoning over Long Contexts
ICLR'26 Oral
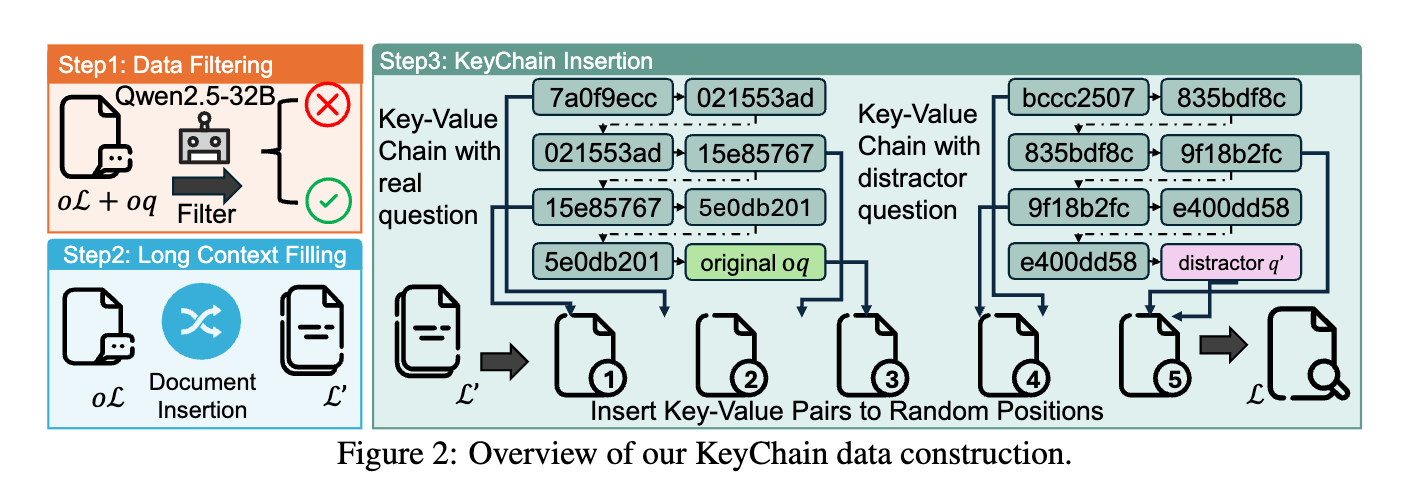
💡short-context(16K) RL 학습만으로 long-context(128K) 추론을 잘하게 하자.어떻게?⇒ UUID 체인으로 질문을 숨긴 고난이도 합성 데이터(KeyChain)로 RL 학습하면, plan–retrieve–reason–recheck 사고 패턴이 발생하여 높은 장문 추론 성능을 7B/14B의 소형 모델로 달성할 수 있다.
26 March 2026
Language Model Personalization via Reward Factorization
COLM'25
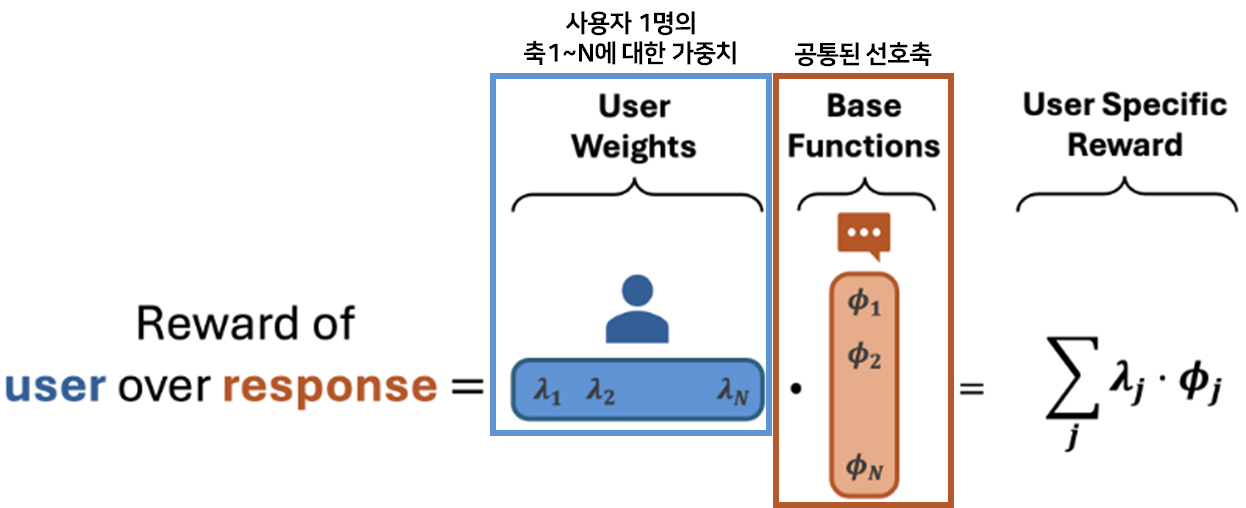
💡여러 사용자의 선호를 공통된 선호 축(e.g., 친절, 간결, 격식)으로 분해해 학습한 뒤, 새로운 사용자가 들어오면 축마다 다른 가중치를 주어 사용자의 personalized된 선호를 빠르게 추정하자!
26 March 2026
Exploring the Limit of Outcome Reward for Learning Mathematical Reasoning
COLM'25
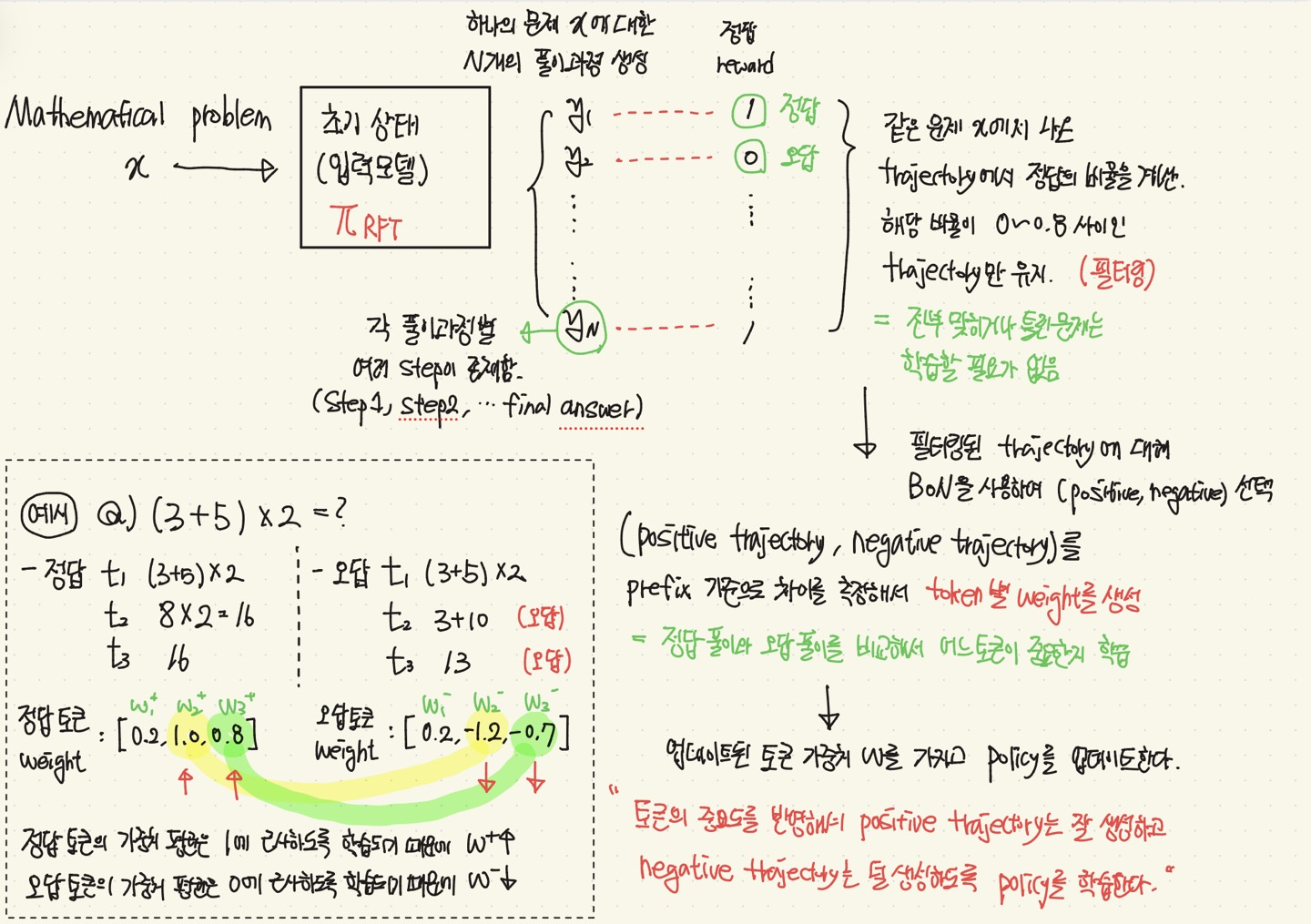
💡Mathematical Reasoning Task 를 할 때, RL을 간접적으로 구현하여 간단하게 풀어보자.(= 강화학습 형태로 수학문제를 효과적으로 풀어보자 !)